

За пределами отзыва и точности: переосмысление показателей в предотвращении мошенничества
12 ноября 2023 г.В эпоху цифровых технологий защитить бизнес-операции от мошенничества сложнее, чем кажется на первый взгляд. Речь идет не только о выявлении обмана; речь идет о защите целостности бренда и доверия клиентов. Это требует смещения акцента с традиционных показателей, таких как полнота и точность, на более детальный подход.
В этой статье рассматриваются расширенные показатели, которые помогают предприятиям защитить свою операционную целостность и репутацию бренда.
Двоичная классификация
Мы часто решаем проблему двоичной классификации, когда нам нужно пометить объекты или события (пользователей, клики, отзывы, рейтинги, транзакции и т. д.) как законные или мошеннические. Но как мы можем измерить его точность? Если вы спросите специалиста по случайным данным о двух наиболее важных показателях для задачи двоичной классификации, он назовет «Вспомнимость» и «Точность». н
Есть классическая матрица (1 для мошенничества и 0 для легитимности) и всеми любимые метрики:
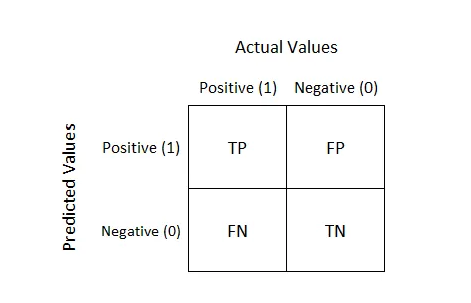
Точность измеряет процент выявленных положительных результатов. Напомним, с другой стороны, измеряется количество фактических положительных результатов, которые были правильно идентифицированы. Показатель F1 измеряет точность теста и представляет собой средневзвешенное значение точности и отзыва.
Конечно, это наиболее удобные метрики для сравнения двух моделей на одном наборе данных, но с точки зрения бизнеса я бы выделил другие метрики, мониторинг которых необходим в рамках задачи по борьбе с мошенничеством.
Классовый дисбаланс
Проблема заключается в дисбалансе классов, который возникает, когда одна категория данных в наборе данных значительно перевешивает другую. Например, в наборе данных с миллионом транзакций по кредитным картам, если только 100 из них являются мошенническими, в данных возникает значительный дисбаланс.
Это может привести к тому, что модели упустят из виду редкие, но важные категории, такие как мошенничество.
Как эксперт по предотвращению мошенничества, я имел дело с классовым дисбалансом в других категориях мошенничества. Вот несколько примеров:
- Похожая доля. Это может произойти при парсинге электронной коммерции, когда количество запросов от парсеров может быть соизмеримо с запросами людей, что дает нам примерно такой же баланс.
* Подавляющая активность мошенничества. Это DDoS-атаки, при которых во время атаки может присутствовать 0,00001% или меньше трафика от законных пользователей. Одна из самых серьезных атак, с которыми я столкнулся, заключалась в 21 миллионе запросов в секунду от злоумышленника.
Еще одним примером такого дисбаланса являются сервисы CAPTCHA. Если у вас есть хороший алгоритм определения того, кому показывать капчу, то ее увидят 99,9% роботов и очень немногие люди.
* Мелкие случаи мошенничества. Это уже упомянутый транзакционный антифрод или злоупотребление промокодами при наличии разумных ограничений по продуктам.
Важно отметить, что мошенничество может быть нестабильным. Могут быть ситуации, когда мошенничества будет мало неделями, а потом произойдет неожиданная атака, и баланс занятий сместится.
Кроме того, могут произойти системные сдвиги в области мошенничества. Допустим, наша доля мошенничества составляет 10%; год назад он составлял 5%. Если раньше мы считали точность 95 % хорошим значением, то теперь, возможно, нам придется поднять планку.
Проблемы с точностью и отзывом
Давайте рассмотрим реальный пример из моего опыта борьбы с DDoS-атаками. Представьте себе сценарий атаки, в котором мы зафиксировали 1 000 000 запросов от ботов при обычном человеческом трафике в 1000 запросов. Это указывает на ситуацию, когда трафик ботов в 1000 раз превышает законный трафик.
Теперь представьте, что у вас есть две стратегии защиты:
Первый может похвастаться точностью 99,9%. Внедрив этот алгоритм, мы заблокировали весь входящий трафик. В результате наша точность составляет 1 000 000, разделенный на 1 001 000, что составляет примерно 99,9%. На бумаге это выглядит впечатляюще. Однако с практической точки зрения этот алгоритм несовершенен, поскольку он блокирует и настоящих пользователей-людей.
При втором подходе мы заблокировали 99,9% вредоносного трафика, не затрагивая при этом реальный человеческий трафик. Однако это по-прежнему означает, что до нашего сервиса дошло 0,01% вредоносного трафика, что соответствует 10 000 запросам. Этот объем в десять раз превышает наш обычный трафик (1000 запросов) и может серьезно поставить под угрозу функциональность сервиса.
Особое внимание к продукту
С точки зрения бизнеса лучше смотреть на истинно отрицательный показатель (на какую долю реальных пользователей мы затрагиваем) и отрицательный прогнозируемый показатель (какая доля трафика является хорошей). Первый вариант – хорошая альтернатива Precision, а второй — вполне достойная замена Recall.
Напомним, что истинно отрицательный показатель измеряет точность идентификации законных транзакций как немошеннических. Это процент правильно классифицированных законных транзакций от всех законных транзакций.
Высокий показатель истинного отрицательного результата означает, что ваша система может точно отличать подлинные транзакции от потенциальных угроз, что способствует более эффективному и надежному механизму предотвращения мошенничества.
Отрицательный прогнозируемый коэффициент измеряет точность выявления законных транзакций. По сути, это процент правильно классифицированных законных транзакций среди всех прогнозируемых транзакций.
Высокий показатель отрицательного прогнозирования указывает на то, что когда ваша система прогнозирует законную транзакцию, она, скорее всего, будет правильной, что повышает эффективность вашего механизма обнаружения мошенничества.
Как это работает
Для простоты возьмем два алгоритма.
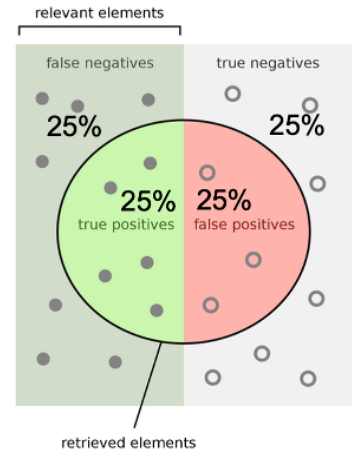
Первый случайный. При равном балансе классов наша матрица ошибок будет выглядеть так:
 n
n
Мы найдем половину мошенничества и классифицируем половину законных событий как мошенничество.
Второй почти идеален. При равном балансе классов наша матрица ошибок будет выглядеть так:
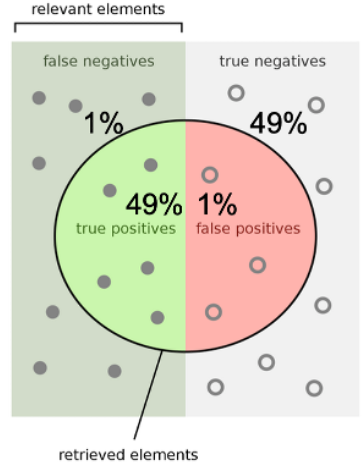
Среди всего мошенничества мы найдем 98% объектов. А еще мы правильно отметим 98 % всех законных событий.
Теперь давайте посчитаем нашу матрицу ошибок для этих алгоритмов для балансов классов. Это можно реализовать следующим образом:
def random_algorithm(count_0, count_1):
TN = count_0 * 0.5
FP = count_0 * 0.5
TP = count_1 * 0.5
FN = count_1 * 0.5
return TN, FP, TP, FN
def perfect_algorithm(count_0, count_1):
TN = count_0 * 0.98
FP = count_0 * 0.02
TP = count_1 * 0.98
FN = count_1 * 0.02
return TN, FP, TP, FN
Также мы посчитаем основные интересующие нас метрики:
recall = TP / (TP + FN)
precision = TP / (TP + FP)
TNR = TN / (TN + FP)
NPV = TN / (TN + FN)
По сути, все эти показатели можно интерпретировать как «чем больше, тем лучше».
Теперь давайте сравним показатели отзыва и отрицательного прогнозирования, которые показывают, насколько хорошо мы обнаруживаем мошенничество, а также точность и истинно отрицательный коэффициент, которые демонстрируют точность наших методов.
Мы должны взять разные пропорции классов и предположить, что наши затраты на ошибки примерно равны. Если они не идентичны, мы можем добавить их как веса к балансу классов, и наши графики в начале и конце по оси X будут более растянуты, но общая идея останется прежней.
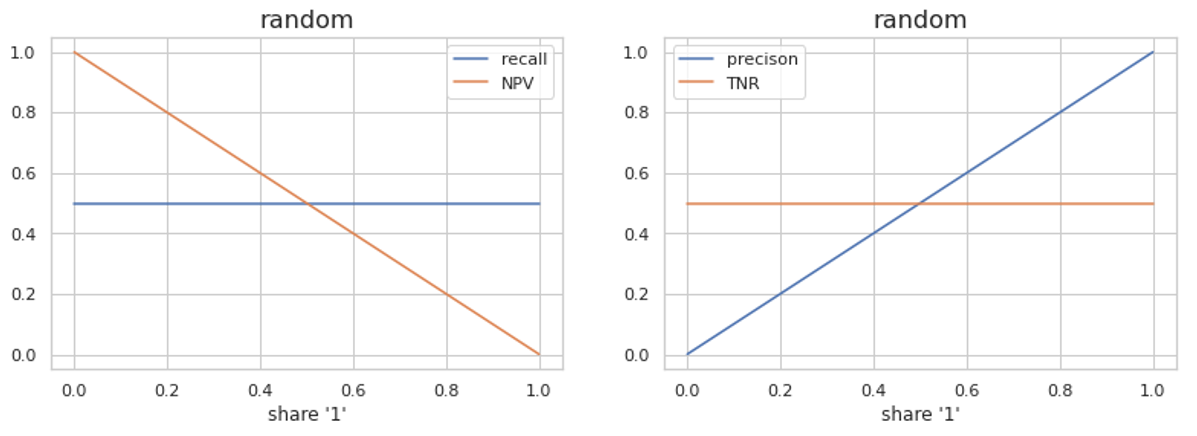
Для случайного алгоритма Recall постоянен и равен 0,5, а NPV падает. NPV становится хуже, как только доля мошенничества во всем потоке увеличивается. Это показывает большое количество мошенничества во всех событиях, оставшихся после очистки.
Что касается показателей «хорошего» трафика, TNR остается постоянным, поскольку мы обнаруживаем одинаковую долю хорошего трафика с помощью наших алгоритмов и подходов Precision, равных 1. Фактически мы по-прежнему влияем на половину легитимного трафика.
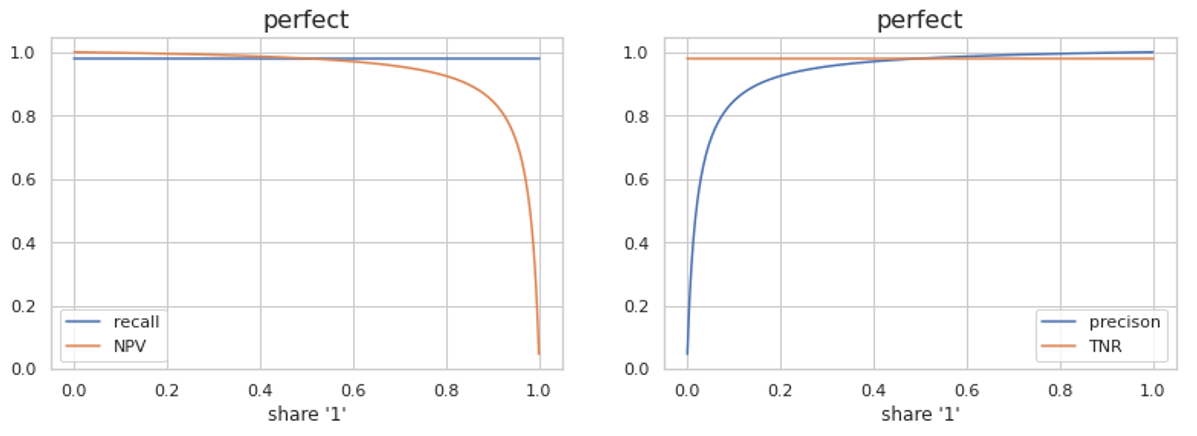
Давайте рассмотрим алгоритм, который работает намного лучше случайного.
С точки зрения фрода Recall остается прежним, но NPV падает, так как, несмотря на очень хорошее качество алгоритма, даже при большом количестве фрода на всем потоке мы все равно пропустим много фрод-трафика. Мы заблокировали 99,9% трафика от DDoS-атаки, но оставшиеся 0,01% оказались настолько большими, что сервис все равно пострадал от этого, и бан 99,9% не помог.
С точки зрения законного трафика, TNR остается неизменным, но точность увеличивается. Если бизнесу важно понять, какая доля пользователей «страдает» от нашего антифрод-алгоритма, то метрика TNR точнее покажет эту проблему.
Вот практический пример онлайн-сервиса с отзывами и рейтингами, где мы просим пользователей оставлять отзывы, которые мы используем для формирования рейтинга объекта. На этом сервисе мы видим попытки завышения рейтингов с помощью фейковых отзывов.
Представим, что у нас есть модель практически идеального качества, в которой мы отловим 98% всего мошенничества и только 2% отзывов от людей не будут учитываться при формировании рейтинга и списка отзывов.
На следующем графике количество хороших отзывов немного растет и имеет еженедельную тенденцию. У плохих нет четкой тенденции, обычно они остаются на низком уровне, но у нас есть около 30 дней с большим всплеском.
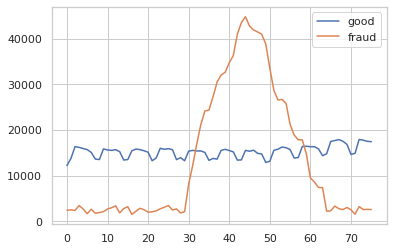
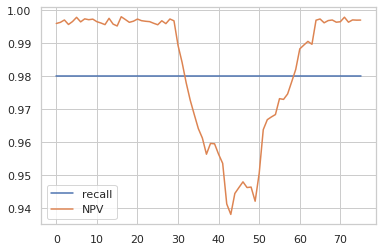
Давайте посчитаем метрики для нашего алгоритма.
Здесь Recall работает стабильно, и мы стабильно выявляем 98% всего мошенничества. Но NPV показывает нам, что реальных заказов меньше. Раньше мы формировали описание на основе 0,99 легитимных и 0,01 фейковых отзывов, тогда как 0,01 не могло существенно повлиять на общую картину и пользовательский опыт.
Когда баланс сместился к 0,94 и 0,06, у нас появился гораздо больший риск того, что завышенные отзывы могут ввести наших пользователей в заблуждение. Напомним, это изображение не отображается.
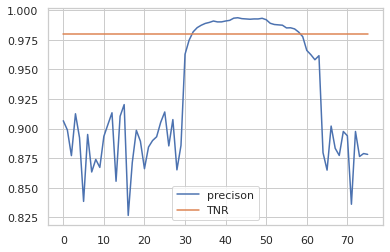
И здесь TNR стабилен, а 2% реальных пользователей мы продолжаем игнорировать. Эти 2% существенно не уменьшают наш охват обзоров и способность формировать рейтинг. Точность возрастает по мере роста фрод-трафика, хотя улучшения продукта не происходит.
н
Напоминаемость и точность — отличные показатели для предотвращения мошенничества. Тем не менее, поскольку баланс классов может меняться резко или плавно в течение года, я рекомендую использовать больше метрик продукта на основе матрицы ошибок.
Итак, мы обсудили показатели двоичной классификации, но есть и другие подходы, которые вы можете использовать для измерения своего успеха. Давайте кратко рассмотрим их.
Влияние на продукт. Например, вы можете разрешить несколько фейковых отзывов, но если вы поставите им очень низкий рейтинг, никто не будет переходить к ним. Если у вас таких отзывов на всем потоке 0,1%, то их увидят только 0,0001% пользователей. Или вы можете учитывать баллы для формирования рейтингов с разными весами. Оценки, в которых вы менее уверены, окажут меньшее влияние.
Стоимость мошеннических услуг. Зачастую существует открытый рынок услуг по накрутке рейтингов, где мошенники могут купить фейковые отзывы. В качестве метрики вы можете взять стоимость услуг на этом рынке, поэтому ваша задача сделать ее выше экономической целесообразности накрутки рейтинга в системе.
Заключение
Для предотвращения мошенничества требуется детальное понимание классических показателей, а также тех, которые напрямую связаны с бизнес-результатами. В идеальном сценарии использовались бы различные показатели, учитывающие абсолютные значения, разнообразные источники данных и фундаментальные показатели качества.
Но зачастую мы вынуждены выбирать минимальный набор метрик, например, для наших коммитов и целей проекта.
Рекомендую не останавливаться только на Recall и Precision. Крайне важно также учитывать показатели, отражающие реальные последствия. Если вы хотите выбрать правильный показатель для измерения влияния на продукт, обратите внимание на другие варианты.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27556)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)