Семантическая сегментация – это область компьютерного зрения, которая специализируется на разделении изображения на области на основе характеристик пикселей для идентификации объектов или границ, что упрощает анализ изображения. Этот метод имеет множество различных вариантов использования: от обнаружения рукописных слов и цифр в отсканированных документах до использования его Google и Apple для разделения переднего плана и фона в портретном режиме.
Такие платформы, как Pinterest и Amazon, используют семантическую сегментацию для загрузки изображений, что позволяет идентифицировать похожие по внешнему виду продукты путем сегментирования интересующей области от остальных. Семантическая сегментация является краеугольным камнем индустрии беспилотных транспортных средств, поскольку она помогает идентифицировать полосы движения, автомобили и пешеходов. Эта технология имеет решающее значение для беспилотных автомобилей, поскольку позволяет им понимать окружающую среду через видеовходы камеры, что позволяет принимать обоснованные решения о будущих действиях. Кроме того, семантическая сегментация находит применение в области экстракорпорального оплодотворения (ЭКО), особенно при классификации эмбрионов. Он используется для точного определения структур эмбриона, способствуя точной оценке развития эмбриона и его отбору для вспомогательных репродуктивных технологий.
В этой статье я исследую сложную область семантической сегментации и объясню, как оценить эффективность семантической сегментации, на примерах из области эмбриологии.
Основные понятия семантической сегментации
Семантическая сегментация основана на моделях классификации изображений, уточняя процесс путем присвоения каждому пикселю предопределенного класса. Пиксели одного класса образуют маску сегментации, обеспечивающую точную классификацию объектов и определение границ.
В этом процессе входное изображение подвергается обработке нейронной сетью, в результате чего получается цветная карта объектов, где каждый цвет пикселя обозначает отдельную метку класса. Такое пространственное понимание позволяет компьютерам различать объекты, отделять передний план от фона и автоматизировать задачи робототехники.
Понимание семантической сегментации
Процесс семантической сегментации состоит из отдельных этапов:
- Обработка входного изображения Модель семантической сегментации, инициированная входным изображением, обрабатывает его с помощью сложной архитектуры нейронной сети.
- Анализ нейронной сети Нейронная сеть анализирует изображение, извлекая сложные функции и закономерности, и детально анализирует визуальный контент.
- Классификация на уровне пикселей В отличие от традиционной классификации изображений, семантическая сегментация работает на уровне пикселей. Каждый пиксель изображения классифицируется индивидуально, что способствует созданию подробной маски сегментации.
- Цветная карта объектов Результатом работы модели является цветная карта признаков изображения. Цвет каждого пикселя соответствует определенной метке класса (обычно целого числа), позволяющей различать различные объекты в сцене.
- Группировка пикселей Пиксели, имеющие одну и ту же метку класса, группируются, образуя последовательные сегменты в маске сегментации. Помогает выполнить точную идентификацию и локализацию объектов.
- Пространственное понимание Сегментированное изображение обеспечивает пространственное понимание и позволяет компьютерам различать объекты, отделять элементы переднего плана от фона и улавливать контекстуальные отношения между различными объектами.
Семантическая сегментация с анализом на уровне пикселей обеспечивает основу для расширенного визуального понимания, кардинально меняя то, как машины интерпретируют визуальные данные и взаимодействуют с ними.

Показатели оценки
Преобладающий класс показателей семантической сегментации относится к категории показателей перекрытия. Эти метрики измеряют, насколько хорошо предсказание модели соответствует фактическим деталям данного изображения. Это дает важную информацию о точности модели.
Показатели перекрытия
К наиболее широко используемым показателям перекрытия относятся коэффициент сходства кубика (DSC) и пересечение по объединению (IoU), также известный как индекс Жаккара. Обе метрики дают численное представление перекрытия между истинной и предсказанной масками со значениями в диапазоне от 0 (нет перекрытия) до 1 (полное перекрытие).
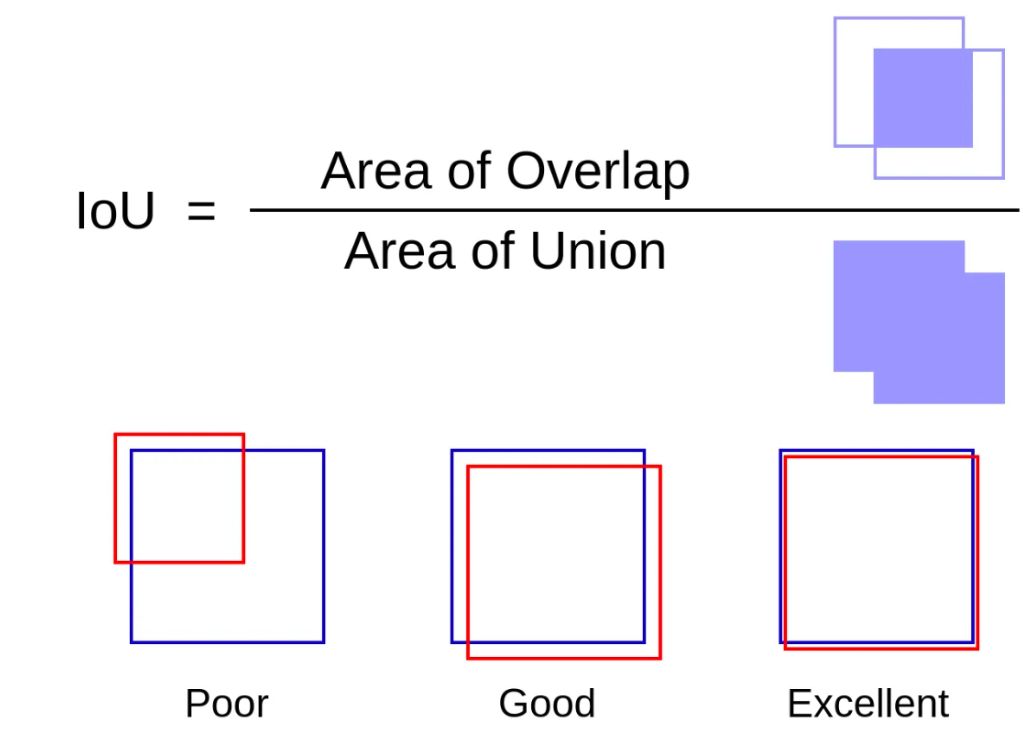
Хотя эти показатели дают значительную информацию, они также имеют ограничения. Примечательно, что они не могут различить различия в форме, что является критическим фактором в таких сценариях, как сегментация бластоцисты в области эмбриологии, где важно точное предсказание нетривиальных форм.
Метрики на основе границ могут помочь выявить изменения в формах и дополнить метрики перекрытия. Однако у них также есть ограничения. Хотя они могут обнаруживать различия в форме, они часто упускают из виду структурные особенности масок, такие как дыры в предсказаниях. Это особенно важно в контексте сегментации бластоцисты, где компоненты могут содержать отверстия.
Показатели на основе объема
Еще один параметр, который следует учитывать при сегментации, — точность объема. Метрики, основанные на объеме, имеют решающее значение для проверки точности моделей семантической сегментации. Они помогают измерить детали прогнозов, связанные с размером. Двумя ключевыми показателями в этой категории являются сходство объемов (VS) и относительная разница объемов (RVD).
Сходство объема (VS) измеряет сходство между основной истинной и прогнозируемой масками, учитывая их соответствующие объемы. Этот показатель дает количественную оценку того, насколько близко прогнозируемый объем соответствует фактическому объему. Это помогает исследователям более тщательно оценить точность сегментации.
Относительная разница объема (RVD) количественно определяет разницу в объеме между основной истиной и масками прогнозирования по отношению к объему основной истинной маски. Этот показатель дает нормализованную меру разницы в объемах и позволяет оценить долю расхождения относительно истинного объема.
Метрики на основе объема — эффективный способ оценить производительность семантических моделей, особенно в ситуациях, когда точное прогнозирование объема имеет решающее значение. Одним из основных недостатков использования таких метрик является то, что они не учитывают местоположение прогнозируемой маски. В результате, полагаясь исключительно на них, можно получить прогнозы правильного размера, но не в том месте. Чтобы решить эту проблему, в процесс оценки следует интегрировать показатели перекрытия или границ.
При оценке моделей крайне важно выбрать соответствующие метрики. Хотя метрики на основе границ и объема могут быть полезны в определенных сценариях, они не учитывают все тонкости структуры маски. Коэффициент сходства кубиков (DSC) является наиболее универсальным и часто используемым показателем для оценки семантической сегментации и рекомендуется в качестве универсального решения. Этот выбор соответствует тенденциям, наблюдаемым в современных моделях, которые фокусируются на семантической сегментации бластоцисты. [1] [2] [3]
Задачи
Обобщив свой опыт анализа показателей оценки семантической сегментации, становится ясно, что существует несколько проблем при точной оценке эффективности моделей сегментации. Эти проблемы в основном связаны с изменчивостью формы, распознаванием отверстий и точностью измерения нюансов объема. Ниже я опишу эти ключевые трудности, с которыми я столкнулся:
* Оценка изменчивости формы. Существующие показатели часто не позволяют точно оценить изменчивость формы, особенно для объектов со сложной или нетривиальной структурой. Захват разнообразных форм, что чрезвычайно важно в приложениях медицинской визуализации или распознавании объектов, становится сложной задачей.
* Ограничения распознавания дыр. Метрики на основе границ, обычно используемые при оценке, могут не эффективно распознавать дыры внутри сегментированных объектов. Это ограничение влияет на способность метрики всесторонне оценивать структуру объектов, особенно при наличии внутренних пустот.
* Измерение точности объема. Хотя метрики на основе объема дают представление об объемных аспектах, точное прогнозирование объема каждого сегментированного компонента остается сложной задачей. Если полагаться исключительно на показатели объема, это может привести к неполным оценкам, особенно в сценариях, где важно точное прогнозирование объема.
* Трудность определения пространственных отношений. Оценка пространственных отношений и контекстуального понимания внутри сегментированных областей представляет собой сложную задачу. Существующие показатели могут с трудом отражать сложное взаимодействие объектов и их окружения, что ограничивает целостную оценку качества сегментации.
* Невозможность дифференцировать похожие структуры. Метрики могут столкнуться с трудностями при различении похожих структур, что может привести к потенциальной неправильной классификации или недооценке точности сегментации. Это становится очевидным в сценариях, где объекты имеют визуальное сходство, но имеют разные семантические значения.
* Ограниченная адаптируемость к требованиям конкретной предметной области. Показатели оценки могут не адаптироваться к конкретным предметным областям или приложениям. Таким образом, чтобы обеспечить актуальность и точность оценок, крайне важно точно настроить показатели с учетом нюансов, специфичных для конкретной предметной области.
Обозначенные проблемы указывают на динамичную научную среду, которая требует постоянного совершенствования методологий оценки.
Семантическая сегментация — это важнейшая технология, которая имеет широкое применение в таких областях, как электронная коммерция, медицинская визуализация и автономные транспортные средства. Его потенциал для улучшения жизни людей значителен. Однако, чтобы эффективно использовать его, нам необходимо иметь возможность измерить его точность, а оценка точности остается сложной задачей. Такие метрики, как коэффициент подобия кубиков и пересечение по объединению, не идеальны, поскольку они плохо справляются с изменчивостью формы и распознаванием отверстий. Поэтому необходимо более глубокое понимание и улучшение этих показателей оценки. Комбинируя показатели перекрытия, границ и объема, мы можем повысить точность семантической сегментации. Это достижение принесет ощутимую пользу различным отраслям.