
Лучшее обнаружение сбоев в бессерверных приложениях
22 апреля 2022 г.Традиционно в мониторинге белого ящика отчеты об ошибках достигаются с помощью сторонних библиотек, которые перехватывают и сообщают об ошибках внешним службам и уведомляют разработчиков при возникновении проблемы. Я здесь, чтобы доказать, что для управляемых служб это может быть достигнуто с меньшими усилиями, без агентов и без потери производительности.
На самом деле существует множество причин, по которым вам не следует использовать классические инструменты отчетов об ошибках в AWS Lambda. Наиболее критичным из них является то, что библиотеки обработки ошибок в коде слепы к специфичным для Lambda сбоям, таким как тайм-ауты, неправильно настроенные пакеты и сбои нехватки памяти. Кроме того, есть проблема с покрытием — реализация отчетов об ошибках для каждой функции требует много работы. Всякий раз, когда вы добавляете службу в свою инфраструктуру, вы должны настроить отслеживание ошибок и мониторинг для нее, и если вы забудете это сделать, это может привести к появлению слепых зон в вашей системе.
К счастью, эти проблемы можно решить довольно легко, и в большинстве случаев это просто вопрос внедрения новых инструментов и методов разработки.
О «Наблюдаемости»
Прежде чем углубляться в детали, важно понять идею наблюдаемости. Это не означает, что у вас будет видимость или что вы даже сможете контролировать свой сервис прямо с места в карьер. Это означает, что система делает себя понятной, выводя данные, которые позволяют разработчику задавать любые произвольные вопросы о текущем или прошлом состоянии системы. К счастью, аспект передачи информации хорошо реализован в AWS, и пользователи без сервера, например, имеют возможность получить видимость, не внедряя дополнительные элементы в свой код.

Помимо журналов CloudWatch, мы могли бы использовать API-интерфейсы AWS для обнаружения ресурсов, а также X-ray и CloudTrail для отслеживания и подключения потоков выполнения.
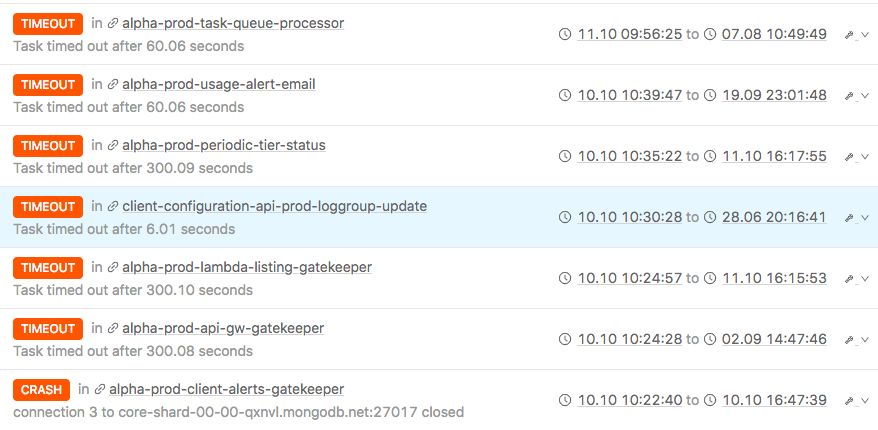
Улучшить обнаружение отказов
Возможность обнаруживать сбои во всех функциях и связывать их с конкретными вызовами, просматривать журналы и извлекать для них рентгеновские трассировки, что значительно сокращает время устранения сбоев в сценариях сбоев.

Давайте разберемся
Единственным предварительным условием для обнаружения ошибок на основе журналов и видимости в целом является то, что журналы отправляются в CloudWatch (в большинстве случаев это значение по умолчанию). С этого момента мы можем выполнить интеллектуальное сопоставление с образцом и вывод для обнаружения сценариев сбоя.

Кроме того, журналы содержат много других данных, которые указывают на задержку и использование памяти и позволяют нам связывать запросы с AWS X-ray и искать отчет о трассировке для конкретного запроса. Все это позволяет собрать много контекста, чтобы понять, что пошло не так в том или ином случае.

Вот что содержит трассировка рентгеновского снимка, когда вы ищете ее для определенного запроса Lambda. Это позволяет вам обнаруживать ошибки в службах, к которым прикасается ваша функция Lambda.
Вывод
С появлением управляемых и распределенных сервисов ландшафт мониторинга должен претерпеть значительные изменения, чтобы не отставать от современных облачных приложений. В настоящее время накладные расходы DevOps являются одним из самых больших препятствий для компаний, которые хотят использовать бессерверные технологии в производстве и полагаться на них для критически важных приложений. Наша команда в Dashbird надеется решить эту проблему по одной за раз.
На настройку Dashbird уходит около 5 минут, после чего вы получите полную информацию о своих бессерверных приложениях. Попробуйте, зарегистрировавшись здесь или посмотрите демонстрацию.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27720)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)