Чтобы начать глубокое исследование процесса разработки приложений ИИ, важно сначала понять, чем эти проекты отличаются от обычных проектов разработки приложений. Когда дело доходит до ИИ, каждая проблема требует уникального решения, даже если компания уже разрабатывала подобные проекты ранее. С одной стороны, существует множество предварительно обученных моделей и проверенных подходов к построению ИИ. Кроме того, ИИ всегда уникален, поскольку он основан на разных данных и бизнес-кейсах. Из-за этого инженеры ИИ часто начинают свой путь с глубокого изучения бизнес-кейса и доступных данных, изучения существующих подходов и моделей.
Благодаря этим аспектам создание проектов ИИ гораздо ближе к научным исследованиям, чем к классической разработке программного обеспечения. Давайте рассмотрим, почему это так и как понимание этой реальности может помочь вам подготовиться к выполнению этих процессов и бюджета для вашего проекта.
Классификация ИИ-проектов по уровню сложности
Проекты ИИ можно разделить на четыре группы:
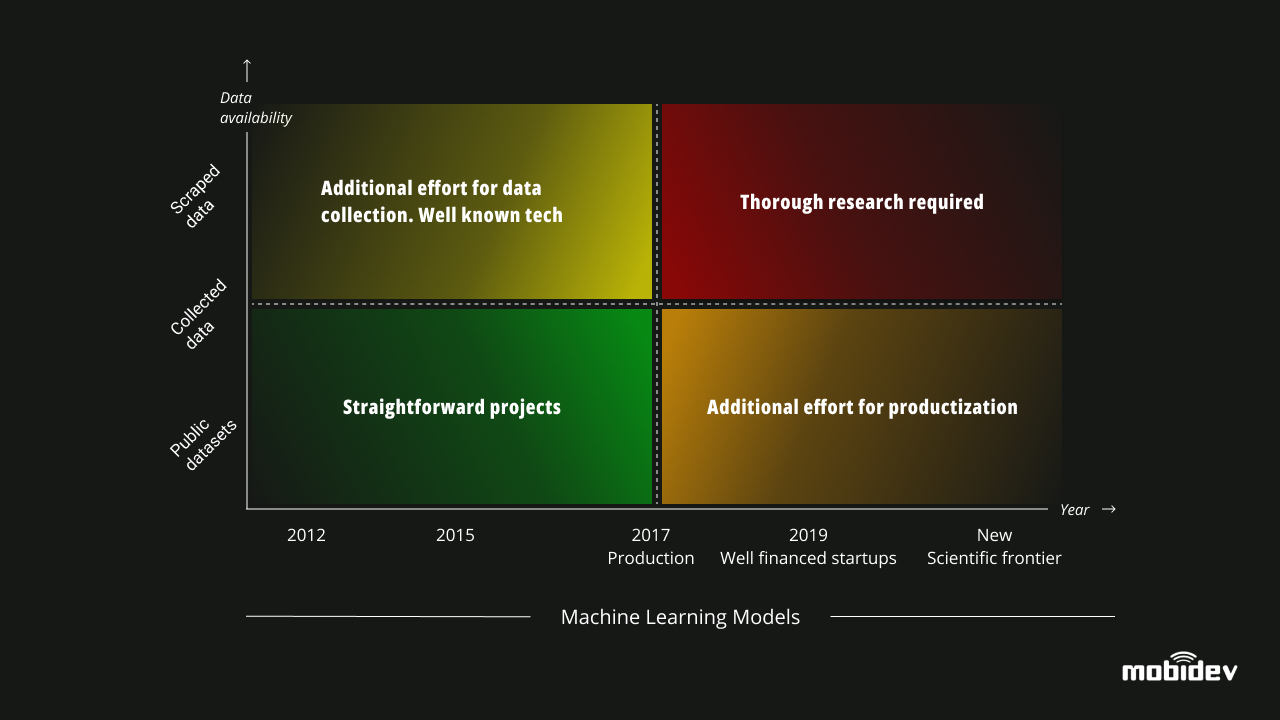
1.Простые проекты
Типичные примеры включают готовые к производству модели, которые можно реализовать с применением общедоступных наборов данных и хорошо известных технологий. Например, ImageNet подходит для проектов, направленных на классификацию изображений.
2.Известные технологические проекты
В этих случаях мы знаем, какая технология необходима для проекта, но нам все равно нужно приложить усилия для сбора и подготовки данных.
3.Тщательное исследование, требующее проектов
В принципе, мы можем разобраться, как работает модель и как применить существующие данные, или какие шаги нужно предпринять, чтобы обучить модель конкретным задачам. Один только опыт не позволит нам делать какие-либо прогнозы, потому что мы не знаем, как ведет себя модель. Процесс запуска требует дополнительного тестирования и обработки кейсов.
4.Для производственных проектов требуются дополнительные усилия
Кейсы из этой группы предполагают трудности как с данными, так и с недостаточно проверенными на практике моделями.
Почему проекты ИИ такие непредсказуемые?
Среды разработки ИИ-проектов можно представить в виде трехуровневой пирамиды, состоящей из технологий и готовых к использованию решений.
Верхний уровень содержит готовые продукты, подходящие для использования ИИ — вроде сторонних библиотек или проверенных решений компании. Например, решения Google для обнаружения мошенничества с чеками, распознавания лиц и обнаружение объектов служат хорошими примерами.
Второй уровень состоит из новых ниш, описывающих бизнес-задачи. У нас может быть подходящая модель для решения задачи, но технология требует небольшой модификации или адаптации, чтобы доказать свою эффективность во время внедрения. Предполагается, что модель будет специализирована под конкретный вариант использования, и это приведет к появлению новой ниши в использовании ИИ.
Научные исследования составляют слой нижнего уровня. Здесь мы можем найти статьи и новые модели — упомянем [GPT-3] (https://openai.com/blog/gpt-3-apps/) в качестве примера. Научные исследования не готовы к производству, поскольку мы не знаем, какие результаты продемонстрируют такие модели. Это глубокий уровень в системе ИИ, хотя мы можем работать в этом направлении.
Чем разработка приложений с искусственным интеллектом отличается от обычных приложений?
Разработка приложений с ИИ принципиально не отличается от приложения без ИИ, но включает PoC (Proof of Concept) и демонстрацию. Получается, этап BA и этап UI/UX начинается, когда демо и компонент AI готовы.
Первое, что делает компания-разработчик приложений, когда владелец продукта поручает ей создать приложение на основе ИИ, — это спрашивает о потребностях и данных клиентов. Является ли ИИ ядром продукта или дополнительным компонентом? Ответ на этот вопрос влияет на то, насколько сложным будет решение.
Клиентам может не понадобиться самое точное и современное решение. Поэтому важно выяснить, не мешает ли отсутствие ИИ-составляющей полноценной разработке продукта и есть ли смысл создавать продукт без ИИ-составляющей. После того, как это будет проработано, мы можем двигаться дальше.
Вначале мы можем разделить проекты ИИ на две подкатегории — независимо от того, создается ли приложение с нуля или компонент ИИ интегрируется в существующее приложение.
Создание приложения ИИ с нуля
Итак, вы решили разработать новое приложение с функциями ИИ с нуля. Из-за этого у вас нет никакой инфраструктуры для интеграции AI-приложения. Здесь мы подходим к самому важному вопросу: можно ли обрабатывать разработку функций ИИ так же, как обрабатываются обычные функции приложений, такие как вход/выход из системы или отправка/получение сообщений и фотографий?
На первый взгляд, ИИ — это просто функция, с которой пользователи могут взаимодействовать. Например, ИИ можно использовать для определения того, следует ли считать сообщение спамом, для распознавания улыбки на лице на фотографии, для реализации входа на основе ИИ с помощью распознавания лица и голоса.
Однако разработка решений ИИ довольно молода и основана на исследованиях. Это приводит к осознанию того, что функции ИИ в приложении — самая рискованная часть всего проекта. Особенно, если бизнес-цель требует инновационного и сложного решения на основе ИИ.
Рассмотрим небольшой пример. Вы хотите создать чат-приложение с экраном входа/выхода, системой сообщений и видеозвонками. Видеозвонки должны поддерживать фильтры, подобные Snapchat. Вот таблица рисков и обзор сложности различных функций приложения:

Глядя на таблицу видно, что с точки зрения стратегии минимизации рисков нецелесообразно начинать процесс разработки с задач, имеющих наименьшую сложность и риски.
Вы можете спросить, почему фильтры, подобные Snapchat, имеют наибольший риск? Вот простой ответ: чтобы создать фильтр, похожий на Snapchat, вам нужно задействовать множество передовых технологий, таких как AR и глубокое обучение, правильно смешать их и установить на мобильные телефоны, которые работают с низкими вычислительными ресурсами. Для этого вам предстоит решить массу неординарных инженерных задач.
Вот почему разработка приложений ИИ с нуля имеет очень специфическую структуру PoC, которая будет обсуждаться далее в этой статье в разделе «Этап разработки PoC».
Интеграция компонента AI в существующее приложение
Интеграция функции ИИ в существующий проект имеет некоторые отличия от создания приложений ИИ с нуля.
Во-первых, из нашего опыта часто бывает, что существующие проекты, которые нам нужно улучшить с помощью ИИ, разрабатывались без какого-либо архитектурного учета функций ИИ. Принимая во внимание, что ИИ-функция является частью некоторого конвейера данных, мы делаем вывод, что разработка ИИ-функции обязательно потребует как минимум некоторых изменений в архитектуре приложения.
С точки зрения ИИ существующие приложения можно классифицировать следующим образом:
Проекты на базе БД:
- Обработка текста
- Системы рекомендаций Чат-боты Прогнозирование временных рядов
Проекты, не основанные на БД:
- Обработка изображений/видео
- Обработка голоса/звука
Ниже мы рассмотрим разработку PoC для нового проекта разработки функций ИИ и интеграцию как для проектов, основанных на базе данных, так и для проектов, не основанных на базе данных.
Основные этапы процесса разработки ИИ-приложений
Давайте рассмотрим пять этапов типичного процесса разработки приложений с искусственным интеллектом.
- ЭТАП БИЗНЕС-АНАЛИЗ
На первом этапе мы получаем вход или видение клиента, которое может быть документом с общим обзором идеи. Здесь мы начинаем процесс бизнес-анализа.
Чтобы подготовить входные данные, нам нужно рассмотреть бизнес-задачу. Предприятия обращаются к компаниям-разработчикам приложений с бизнес-проблемами, и задача последних — найти точку пересечения бизнеса и возможностей ИИ.
Например, в случае ресторан или продуктовой сети, владельцы бизнеса заинтересованы в снижении пищевых отходов и достижении баланса путем анализа покупок и продаж. Для инженеров ИИ, эта задача превращается в предсказание временных рядов или реляционную задачу анализа, решение которой позволяет предсказать конкретные цифры. Мы работали над подобными проектами для наших клиентов, и это [исследование случая] (https://mobidev.biz/case-studies/pos-application-development) можно рассматривать как пример машинного обучения на основе модуля прогнозирования спроса разработка.
- ЭТАП ОПРЕДЕЛЕНИЯ ЗАДАЧИ МАШИННОГО ОБУЧЕНИЯ
Следующим этапом является определение проблемы ML (Machine Learning), которую необходимо обсудить и решить. При этом необходимо учитывать технологические возможности подполей искусственного интеллекта, таких как компьютерное зрение, обработка естественного языка, распознавание речи, прогнозирование, генеративный ИИ и другие.
- ЭТАП СБОРА ДАННЫХ
Данные — это топливо для машинного обучения. Существует два основных типа данных — специальные и общие. Общие данные можно получить на сайтах с открытым исходным кодом, поэтому все, что нам нужно сделать, сводится к сужению круга целевой аудитории, делая акцент на конкретном регионе, поле, возрасте или других важных факторах. Большое количество общих данных может упростить процесс.
Поэтому, если у клиента есть приложение, основанное на активности фитнес-трекера, мы можем применить данные и передать обучение, чтобы начать внедрение как можно быстрее. То же самое относится и к классификации изображений, где для начала доступно множество коллекций.
Другим вариантом может быть отсутствие доступных данных, их несовместимость с целевой аудиторией или потребность в данных, генерируемых конкретным бизнесом. Например, статистика продаж конкретного предприятия или список обнаружения дефектов сборочной линии. Что делать, если у клиента нет данных, но он собирается внедрить компонент ИИ?
Есть шесть источников для получения данных.
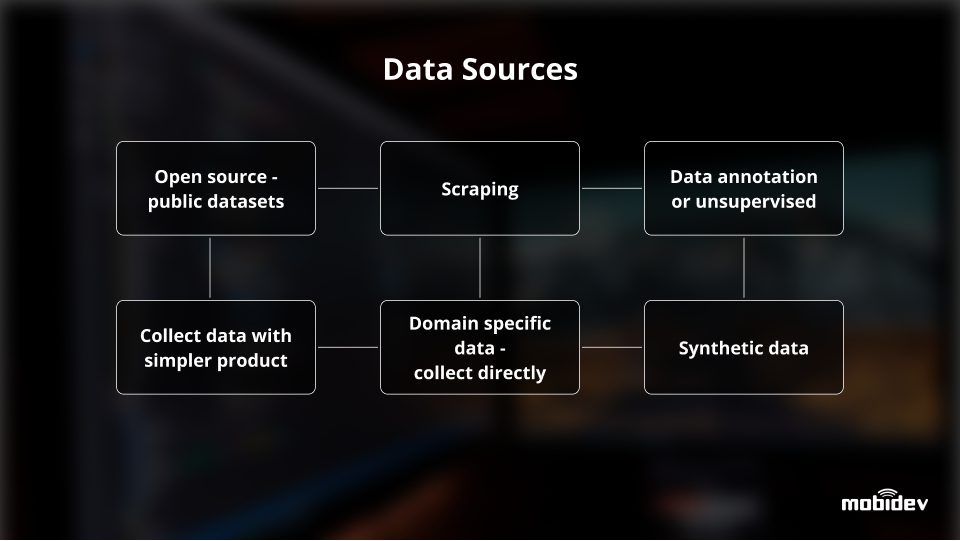
1. Есть шесть источников для получения данных. Первый — это кладезь данных с открытым исходным кодом, который позволяет запускать множество проектов с общедоступными наборами данных.
2.Второй источник — скрапинг, который помогает реализовывать проекты ИИ с текстовыми данными. Веб-страницы, такие как Википедия, содержат текстовую информацию или определенные данные. Например, база вакансий без учета ИИ может быть полезна отделам по подбору персонала. Такие данные являются наполовину открытыми.
3.Третий источник подразумевает аннотацию данных, выполняемую вручную или автоматически. В случае ручной аннотации данных для сбора и маркировки изображений или других данных может быть привлечена сторонняя компания.
4.Четвертый источник — получение данных с помощью коллекции с более простым продуктом. Типичный кейс — разработка чат-бота. Если у нас нет данных для реализации, мы задаем клиенту ряд вопросов. Ответы на эти вопросы служат исходной информацией для дальнейшего развития. Можно привести и другие примеры распознавания символов: пользователи исправляют ошибки в тексте, полученном в результате обработки необработанной модели, и эта информация позволяет нам улучшить модель.
5. Тем не менее, конкретные данные являются пятым источником информации, и для их сбора необходимо проделать большую работу.
6. Последний источник, синтетические данные, появляется, когда мы самостоятельно создаем что-то вроде графиков, диаграмм или диаграмм. Инженеры ИИ создают графики или диаграммы с помощью Python и используют их в качестве набора данных для начинающих. Впоследствии сюда добавляются более реалистичные производственные данные. Еще одним примером синтетического подхода к сбору данных является использование движков 3D-игр, таких как Unity или Unreal Engine, для разных типов задач компьютерного зрения и даже для задач обучения беспилотных автомобилей.
Роль данных в проектах ИИ нельзя умалять. Насколько эффективно работает алгоритм, зависит от данных, поэтому обширность входных данных делает его более точным.
Существуют специальные методики, способные улучшить качество данных.
- ЭТАП РАЗРАБОТКИ КОН
Следующим шагом является определение бизнес- и технических показателей, которые могут существенно различаться. Владелец бизнеса может задаться вопросом, будет ли достаточной точность проекта. Инженер ИИ не всегда готов ответить на этот вопрос, поскольку это может быть новая ниша. На помощь приходит PoC, демонстрирующий минимальную точность, которую можно получить. Самое примечательное, что бинарные решения точны на 50%, как подбрасывание монеты.
Давайте рассмотрим первый пример, в котором клиенту необходимо сократить количество пищевых отходов. Превратив бизнес-задачу в техническое решение, мы пришли к выводу, что нам необходимо прогнозировать покупки, поэтому метрика MAPE (Средняя абсолютная ошибка в процентах) будет оптимальным.
Второй пример — это безопасный вход, для которого равный коэффициент ошибок (EER) является бизнес-метрикой. EER соответствует равенству частоты ложных срабатываний и ложных отказов.
Третий пример — это проблема классификации, для которой точность правильно распознанных сущностей служит бизнесом. метрика. Классифицируя объекты, мы можем учитывать текст со спамом, изображения с кошками, наличие маски на сотруднике и т. д. Инженеры могут использовать ту же метрику или немного усложнить задачу и применить оценку F1 для иллюстрации.
Следующим моментом, который необходимо определить перед началом PoC, являются ограничения. Это нефункциональное требование, которое может стать ясным позже, во время реализации. PoC должен основываться на одной гипотезе и решать конкретную задачу. Иллюстрацией ограничения безопасности является необходимость размыть все, что находится позади человека на заднем плане.
После того, как входные данные подготовлены, команда ИИ работает над PoC, метриками, измерением результатов и демонстрацией. Параллельно с демонстрацией можно делать отчет, описывая расследования, подводные камни, подтверждая или опровергая гипотезу.
Каждое исследование, включенное в PoC, сопровождается отчетом: что удалось выяснить, что можно сделать в будущем, а какая информация стала понятной и должна быть учтена в следующих итерациях.
Хотя PoC похож на продукт, на самом деле он не готов к использованию. Его можно превратить в продукт, если демо устраивает клиента. Важно понимать, что для полноценной разработки продукта помимо инженеров по ИИ нужны и другие специалисты — фронтенд, бэкенд, мобильные разработчики и многие другие.
РАЗРАБОТКА AI POC ДЛЯ НОВЫХ ПРОЕКТОВ
Стадия PoC нового проекта ИИ должна быть ориентирована на ИИ. Что это значит? Чтобы соответствовать стратегии минимизации рисков, мы должны начать с самой рискованной части проекта, функции ИИ, и, по возможности, не касаться других функций проекта.
Согласно [CRISP-DM] (https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining), этап PoC может повторяться несколько раз для достижения подходящих результатов.
После достижения удовлетворительных результатов мы можем перейти к этапу MVP/индустриализации с разработкой всех оставшихся функций приложения.

РАЗРАБОТКА AI POC ДЛЯ СУЩЕСТВУЮЩИХ ПРОЕКТОВ
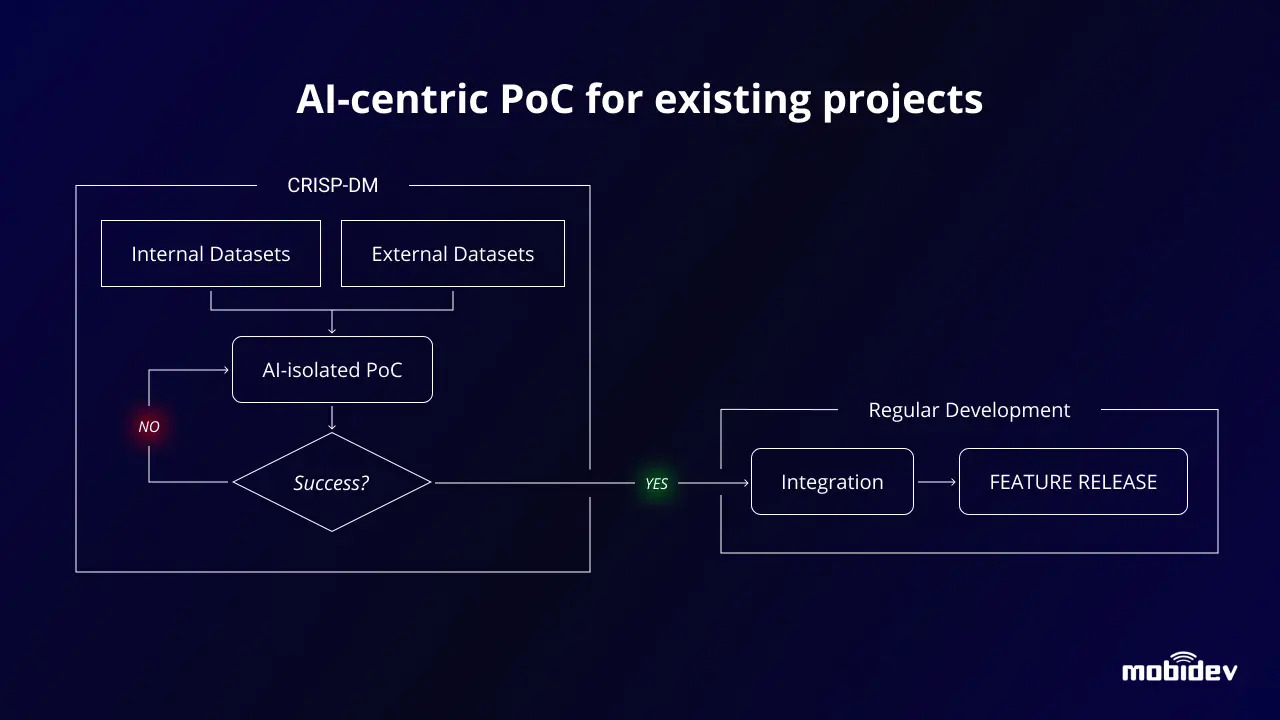
Чтобы сделать функцию ИИ доступной для конечных пользователей, нам сначала нужно разработать эту функцию, а затем интегрировать ее в существующее приложение. А именно, с кодовой базой приложения, архитектурой и инфраструктурой.
Самое интересное в ИИ-функциях то, что их можно исследовать, разрабатывать и тестировать, не касаясь основного приложения. Это наводит нас на мысль, что мы можем запускать изолированный AI PoC без риска для основного приложения. В этом и заключается суть стратегии минимизации рисков.
Вот три шага, которые нужно выполнить:
1.Собирайте данные из существующего приложения следующим образом:
- Делаем дамп БД
- Сбор образцов изображений/видео/аудио
- Маркировка собранных данных или получение соответствующих наборов данных из библиотек с открытым исходным кодом.
2. Создайте изолированную среду ИИ с использованием данных, собранных ранее, для:
- Обучение
- Тестирование
- Профилирование
3. Разверните успешно обученный компонент ИИ:
- Изменения в подготовке к текущей архитектуре приложения
- Адаптация кодовой базы для новой функции AI
В зависимости от типа проекта адаптация кодовой базы может привести к:
- Изменения в архитектуре базы данных для упрощения и ускорения доступа к ней модуля ИИ
- Изменения в топологии микросервиса для обработки видео/аудио
- Изменения в минимальных системных требованиях мобильного приложения
ГРУБАЯ ОЦЕНКА СТАДИИ РОС
Владельцы бизнеса часто спрашивают поставщиков программного обеспечения о бюджете, сроках и усилиях, которые могут потребоваться для этапа PoC.
Как мы показали выше, для AI-проектов характерен высокий уровень непредсказуемости по сравнению с обычным процессом разработки. Это связано с высокой вариативностью типов задач, наборов данных, подходов и технологий.
Все эти условия объясняют, почему оценка гипотетического проекта является достаточно сложной задачей. Тем не менее, мы показали одну из возможных классификаций проектов ИИ выше на основе уровня сложности проекта.
В следующей таблице приведены примерные оценки для проектов разного уровня сложности. Имейте в виду, что оценки в таблице могут значительно различаться в зависимости от типа проекта и свойств набора данных. Цифры даны для одной итерации CRISP-DM.
- НОВАЯ ИТЕРАЦИЯ И/ИЛИ СТАДИЯ ПРОИЗВОДСТВА
Следующим шагом после первого PoC может быть новая итерация PoC с дальнейшими улучшениями или развертыванием. Создание нового PoC подразумевает добавление данных, обработку кейсов, анализ ошибок и т. д. Количество итераций условно и зависит от проекта.
Запуск
Любой проект ИИ напрямую связан с рисками. Мы можем столкнуться с рисками, связанными с пригодностью данных, а также с алгоритмическими рисками или рисками реализации. Чтобы снизить риски, разумно начинать разработку продукта только тогда, когда точность ИИ-компонента соответствует целям и ожиданиям бизнеса.
Автор [Евгений Краснокутский] (https://mobidev.biz/our-team/evgeniy-krasnokutsky), руководитель группы JavaScript в [MobiDev] (https://mobidev.biz/services/machine-learning-consulting).
Полная версия статьи была первоначально опубликована здесь и основана на исследованиях технологий MobiDev.