Пошаговое руководство по созданию парсера футбольных данных
25 мая 2022 г.Извлечение футбольных данных (или футбола в США) — отличный способ создать комплексный набор данных, который затем можно использовать для создания информационных панелей со статистикой, проведения перекрестного анализа и использования результатов для спортивной журналистики или фэнтезийных лиг.
Какой бы ни была ваша цель, парсинг футбольных данных поможет вам собрать всю необходимую информацию, чтобы воплотить ее в жизнь. В этом руководстве мы собираемся создать простой парсер футбольных данных с помощью Axios и Cheerio в Node.js.
Несколько вещей, которые следует учитывать перед началом
Хотя вы сможете следовать этому руководству без каких-либо предварительных знаний, вам потребуется небольшой опыт в веб-скрейпинге, чтобы максимально использовать его и использовать эту информацию в других контекстах.
Если вы новичок в парсинге веб-страниц, мы рекомендуем вам прочитать наше руководство основы парсинга веб-страниц в Node.js и нашу руководство по как создать парсер eBay, чтобы узнать больше об async/await.
Кроме того, рекомендуется понимание основ HTML и Javascript.
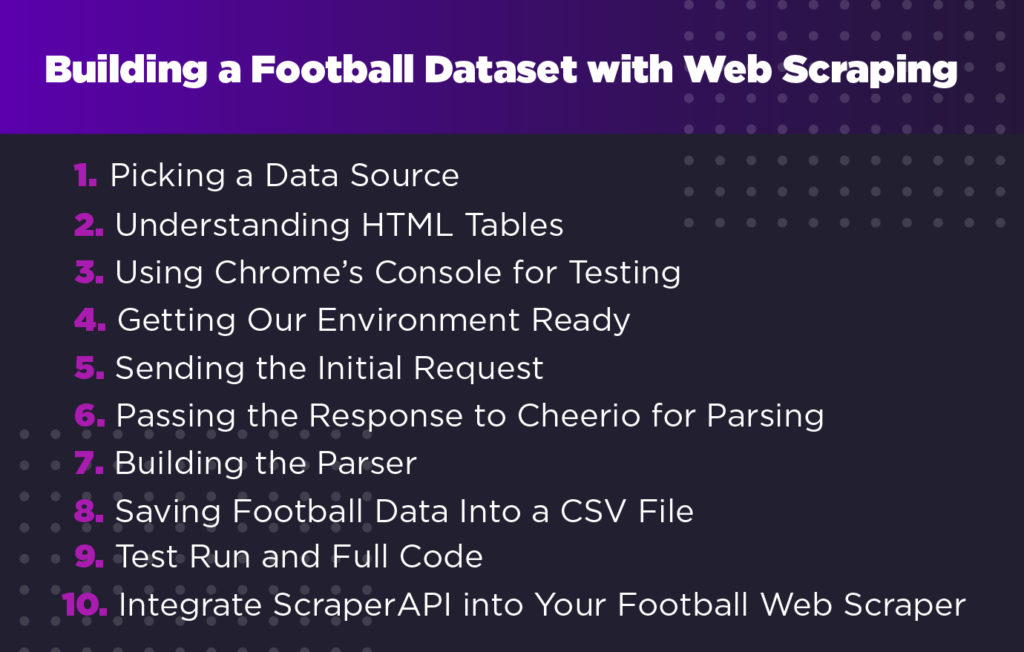
Создание футбольного набора данных с помощью парсинга веб-страниц
1. Выбор источника данных
Несмотря на то, что существуют фундаментальные принципы, применимые к каждому проекту парсинга веб-страниц, каждый веб-сайт представляет собой уникальную головоломку, которую необходимо решить. Так же как и выбор того, откуда вы будете получать данные и как именно вы будете их использовать.
Вот несколько источников, которые вы можете использовать для получения футбольных данных:
https://www.premierleague.com/
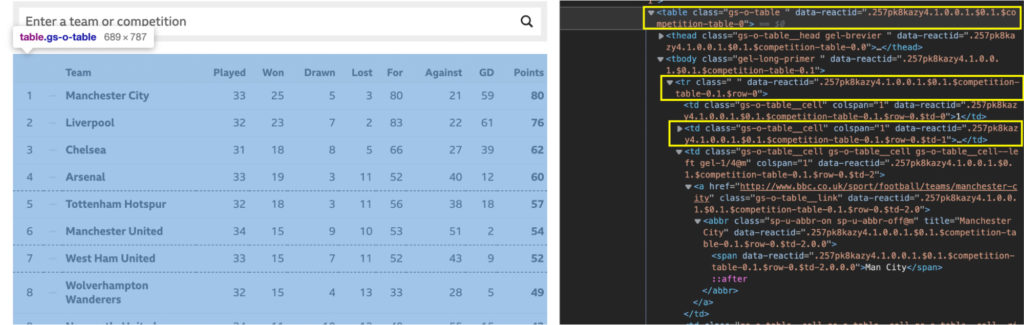
Для простоты мы будем очищать страницу Таблица высшей лиги BBC, так как она содержит всю информацию, которую мы будем очищать, непосредственно внутри HTML-документа. , а также потому, что многие данные, найденные на этих веб-сайтах, представлены в виде таблиц, поэтому очень важно научиться эффективно их очищать.
Примечание. Другие веб-сайты, такие как ESPN, используют JavaScript для вставки содержимого таблицы на страницу, что затрудняет нам для доступа к данным. Тем не менее, мы будем иметь дело с такими таблицами в более поздней статье.
2. Понимание таблиц HTML
Таблицы — отличный способ упорядочить содержимое и отобразить наборы данных с более высоким обзором, что позволяет нам, людям, легче его понять.
На первый взгляд каждая таблица состоит из двух основных элементов: столбцов и строк. Однако [HTML-структура таблиц] (https://www.w3schools.com/tags/tag_table.asp) немного сложнее.
Таблицы начинаются с тега
| для каждой ячейки таблицы внутри |
| внутри строк. Вот пример из W3school:
Давайте изучим нашу целевую таблицу с учетом этой структуры, проверив страницу.
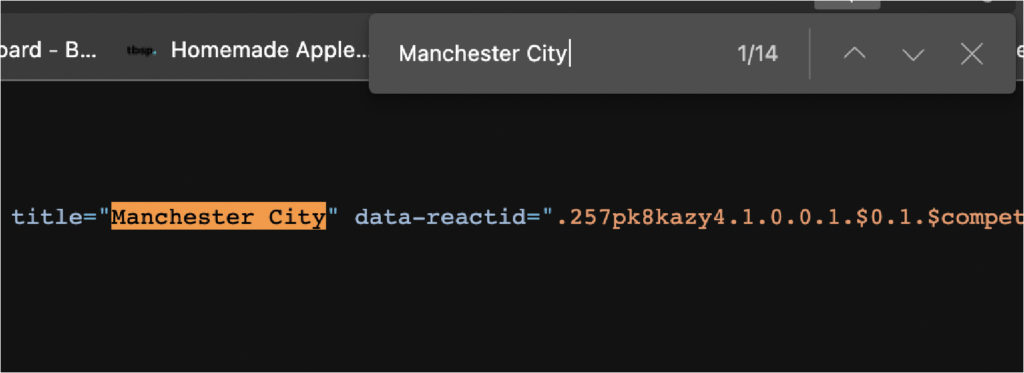
Код немного беспорядочный, но такой HTML-файл вы найдете в реальном мире. Несмотря на беспорядок, он по-прежнему соблюдает Итак, каков наилучший подход к извлечению футбольных данных из этой таблицы? Хорошо, если мы можем создать массив, содержащий все строки, мы можем перебрать каждую из них и получить текст из каждой ячейки. Ну это вообще гипотеза. Чтобы подтвердить это, нам нужно проверить несколько вещей в консоли нашего браузера. 3. Использование консоли Chrome для тестированияЕсть пара вещей, которые мы хотим протестировать. Первое, что нужно проверить, — находятся ли данные в файле HTML или они вводятся в него. Мы уже говорили вам, что он находится в файле HTML, но вы захотите узнать, как проверить его самостоятельно для будущих проектов парсинга футбольных матчей на других сайтах. Самый простой способ увидеть, внедряются ли данные откуда-то еще, — это скопировать часть текста из таблицы — в нашем случае мы скопируем первую команду — и поискать ее в исходном коде страницы.
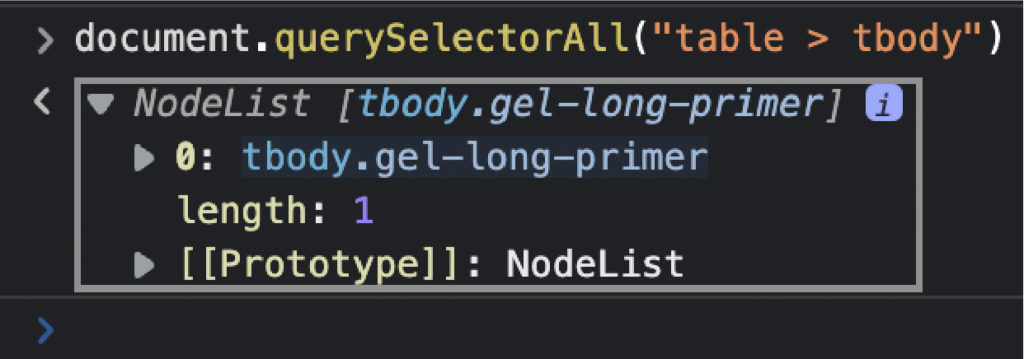
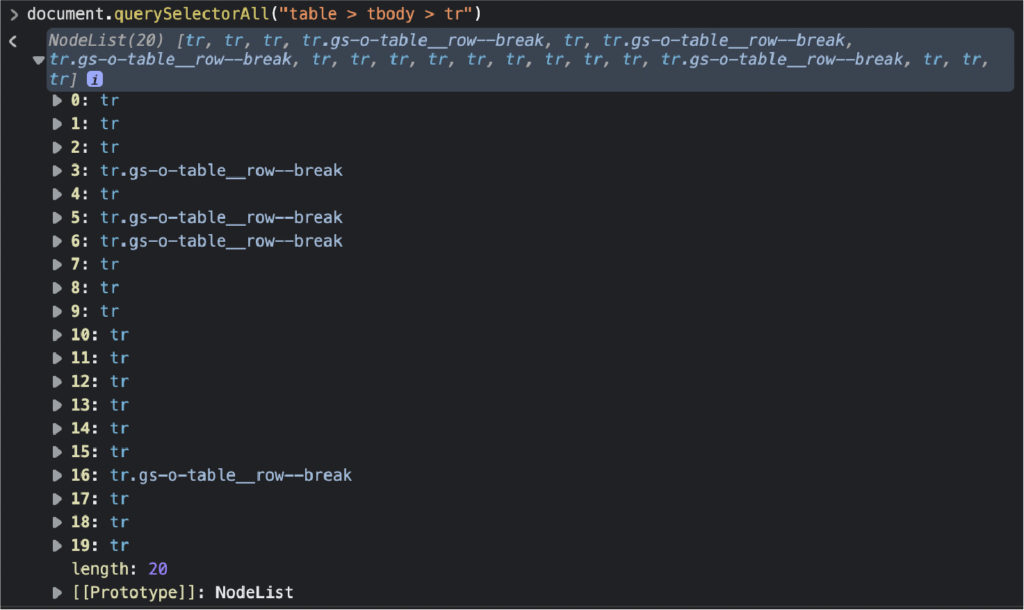
Сделайте то же самое с еще несколькими элементами, чтобы быть уверенным. Источником страницы является файл HTML до того, как произойдет какой-либо рендеринг, поэтому вы можете увидеть начальное состояние страницы. Если элемента там нет, это означает, что данные вводятся откуда-то еще, и вам нужно найти другое решение для их очистки. Второе, что мы хотим протестировать перед кодированием парсера, — это наши селекторы. Для этого мы можем использовать консоль браузера для выбора элементов с помощью метода .querySelectorAll(), используя элемент и класс, которые мы хотим очистить. Первое, что мы хотим сделать, это выбрать саму таблицу. document.querySelectorAll ("таблица")
Наконец, мы выберем все элементы
Круто, 20 узлов! Он соответствует количеству строк, которые мы хотим очистить, поэтому теперь мы знаем, как их выбирать с помощью нашего скребка. Примечание. Помните, что когда у нас есть список узлов, счетчик начинается с 0, а не с 1. Не хватает только изучения положения каждого элемента в ячейке. Внимание, спойлер, он увеличивается с 2 до 10.
Отлично, теперь мы наконец готовы перейти к нашему редактору кода. 4. Подготовка нашей средыЧтобы начать проект, создайте новый каталог/папку и откройте его в VScode или предпочитаемом вами редакторе кода. Сначала мы установим Node.js и NPM, затем откройте ваш терминал и запустите проект с помощью команды Затем мы установим наши зависимости с помощью NPM:
5. Отправка исходного запросаМы хотим создать парсер как асинхронную функцию, чтобы использовать ключевое слово await, чтобы сделать его более быстрым и устойчивым. Давайте откроем нашу функцию и отправим первоначальный запрос с помощью Axios, передав ей URL-адрес и сохранив результат в переменной с именем response. Чтобы проверить, работает ли он, зарегистрируйте статус ответа.
6. Передача ответа в Cheerio для разбораМы собираемся сохранить данные ответа в виде переменной (для простоты назовем ее HTML) и передать ее в Cheerio с помощью метода .load() внутри переменной со знаком доллара $ , как в JQuery.
Cheerio [проанализирует необработанные данные HTML] (https://www.scraperapi.com/blog/what-is-data-parsing/) и превратит их в дерево узлов, по которому можно будет перемещаться с помощью селекторов CSS, как в консоли браузера. . 7. Построение парсераНаписать парсер намного проще, если уже протестированы селекторы в консоли браузера. Теперь нам просто нужно перевести его в Node. JS. Для начала возьмем все строки в таблице: const allRows = $("table.gs-o-table > tbody.gel-long-primer > tr"); Опять же, попробуйте назвать свои переменные так, чтобы это имело смысл. Это сэкономит ваше время на больших проектах и сделает так, чтобы каждый мог понять, что делает каждая часть вашего кода. В Node.JS мы можем использовать .each() для прохода по всем узлам и выбора элементов
Обратите внимание, что сначала мы сохраняем все элементы Давайте протестируем один из этих элементов, чтобы убедиться, что он работает, и посмотрим, что он возвращает:
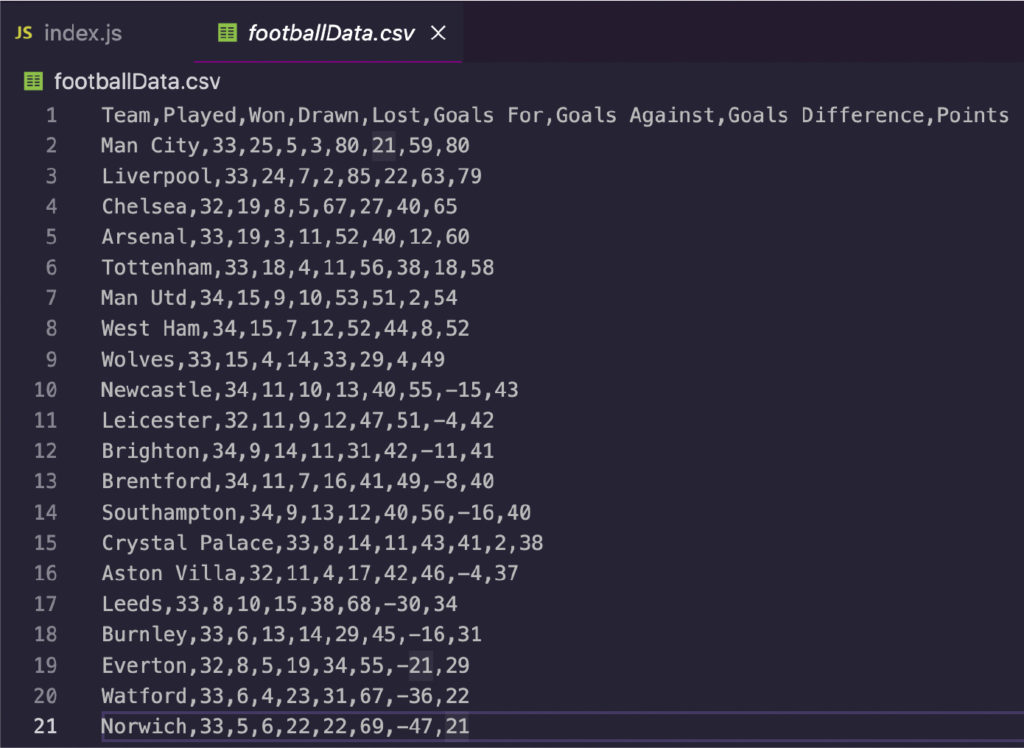
Как видите, он возвращает упорядоченный список, а не длинную строку — именно то, что нам нужно для следующего шага. 8. Сохранение футбольных данных в файл CSVМы разобьем этот процесс на три шага. 1- Создайте пустой массив вне основной функции. premierLeagueTable = []; 2- Затем вставьте каждый извлеченный элемент в массив с помощью метода .push() и используйте описательное имя для их маркировки. Вы хотите, чтобы они соответствовали заголовкам из таблицы, которую вы очищаете.
3- В-третьих, используйте ObjectToCsv, чтобы создать новый файл CSV и сохранить его на своем компьютере с помощью метода .toDisk(), включая путь к файлу и имя файла.
Это все, что нам нужно для экспорта наших данных. Мы также могли бы создать лист сами, но в этом нет необходимости. ObjectToCsv делает процесс очень быстрым и простым. 9. Тестовый прогон и полный кодМы добавили несколько операторов
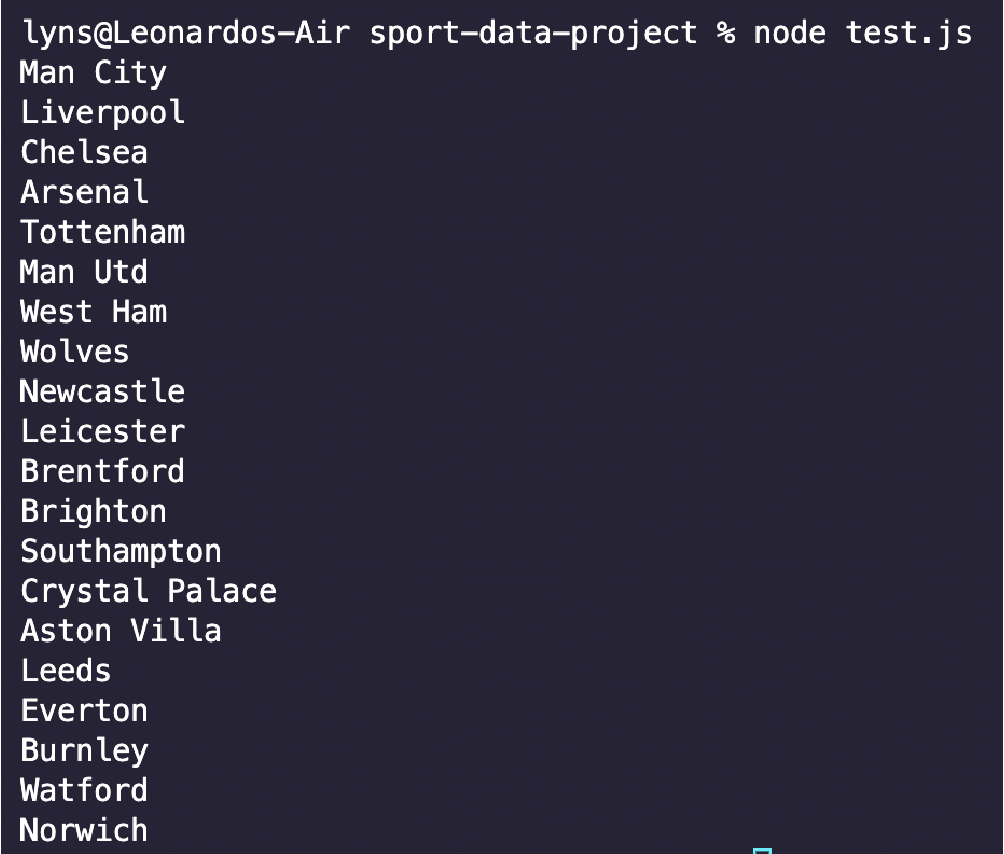
Запустите его с node index.js, и менее чем за секунду у вас будет готовый к использованию CSV-файл.
Вы можете использовать тот же процесс, чтобы очистить практически любую таблицу HTML, которую вы хотите, и создать огромный набор футбольных данных для аналитики, прогнозирования результатов и многого другого.
Давайте добавим уровень защиты к нашему парсеру, отправив запрос через ScraperAPI. Это поможет нам очистить несколько страниц, не рискуя заблокировать наш IP-адрес или навсегда запретить доступ к этим страницам. Во-первых, давайте создадим бесплатную учетную запись ScraperAPI, чтобы получить 5000 бесплатных вызовов API и наш ключ. Там мы также увидим пример cURL, который нам нужно будет использовать в нашем первоначальном запросе.
Как видите, все, что нам нужно сделать, это заменить URL-адрес в примере нашим целевым URL-адресом, а ScraperAPI сделает все остальное. const response = await axios('http://api.scraperapi.com? api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.bbc.com/sport/football/tables'); Наш запрос может занять немного больше времени, но взамен он будет автоматически менять наш IP-адрес для каждого запроса, использовать годы статистического анализа и машинного обучения для определения наилучшей комбинации заголовков и обрабатывать любую капчу, которая может появиться. Первоначально опубликовано [здесь] (https://www.scraperapi.com/blog/how-to-scrape-football-data/) Оригинал 🔥 Популярное на этой неделе
⭐ Самое популярное
Categories
|
|---|