Во многих предыдущих сообщениях в Клубе парсинга веб-страниц мы обсуждали, как парсить веб-сайты при различных обстоятельствах, например, когда веб-сайт защищен Cloudflare или при использовании мобильного приложения.
Однако мы не исследовали, какие секторы больше всего выигрывают от извлеченных данных.
Некоторые секторы совершенно очевидны, например предприятия электронной коммерции, стремящиеся понять предложения своих конкурентов, а также приложения для доставки и другие рынки.
Однако есть один сектор, который всегда жаждет данных, поскольку новый и надежный набор данных может принести миллионы долларов прибыли, и это финансовый сектор. В Re Analytics, моей нынешней компании, мы накопили опыт в этой отрасли. В этом посте и в предстоящем лабораторном занятии (запланированном на 27 апреля) мы углубимся в мир альтернативных данных.
Что это значит для альтернативных данных?
В финансовом секторе данные играют решающую роль, помогая инвесторам принимать решения об их инвестиционных стратегиях. Майкл Блумберг построил свою империю, продавая финансовые данные и новости инвесторам.
Джим Симмонс, опытный математик, создал хедж-фонд «Ренессанс» и одним из первых применил то, что мы сейчас называем как наука о данных в финансах. Это позволило ему получить конкурентное преимущество перед другими фондами и заключать более выгодные сделки. Medallion, основной фонд фонда, закрытый для внешних инвесторов, заработал более 100 миллиардов долларов прибыли от торговли с момента своего основания в 1988 году. Согласно Википедии, это соответствует среднему валовому годовому доходу 66,1% или среднему чистому годовому доходу 39,1% в период с 1988 по 2018 год.
По мере того, как мировая экономика становится все более цифровой, становятся доступными новые источники информации. В то время как традиционные источники финансовых данных, такие как финансовые отчеты, балансы и исторические данные финансового рынка, остаются важными, различные источники из цифрового мира становятся все более привлекательными для финансовой отрасли. Эти источники называются альтернативными данными. Согласно официальному определению, альтернативные данные — это информация о конкретной компании, опубликованная источниками за пределами компании, предоставление уникальной и своевременной информации об инвестиционных возможностях.
Какие типы альтернативных данных существуют?
Поскольку альтернативные данные — это данные, которые поступают не из самой компании, это определение включает широкий спектр возможностей.
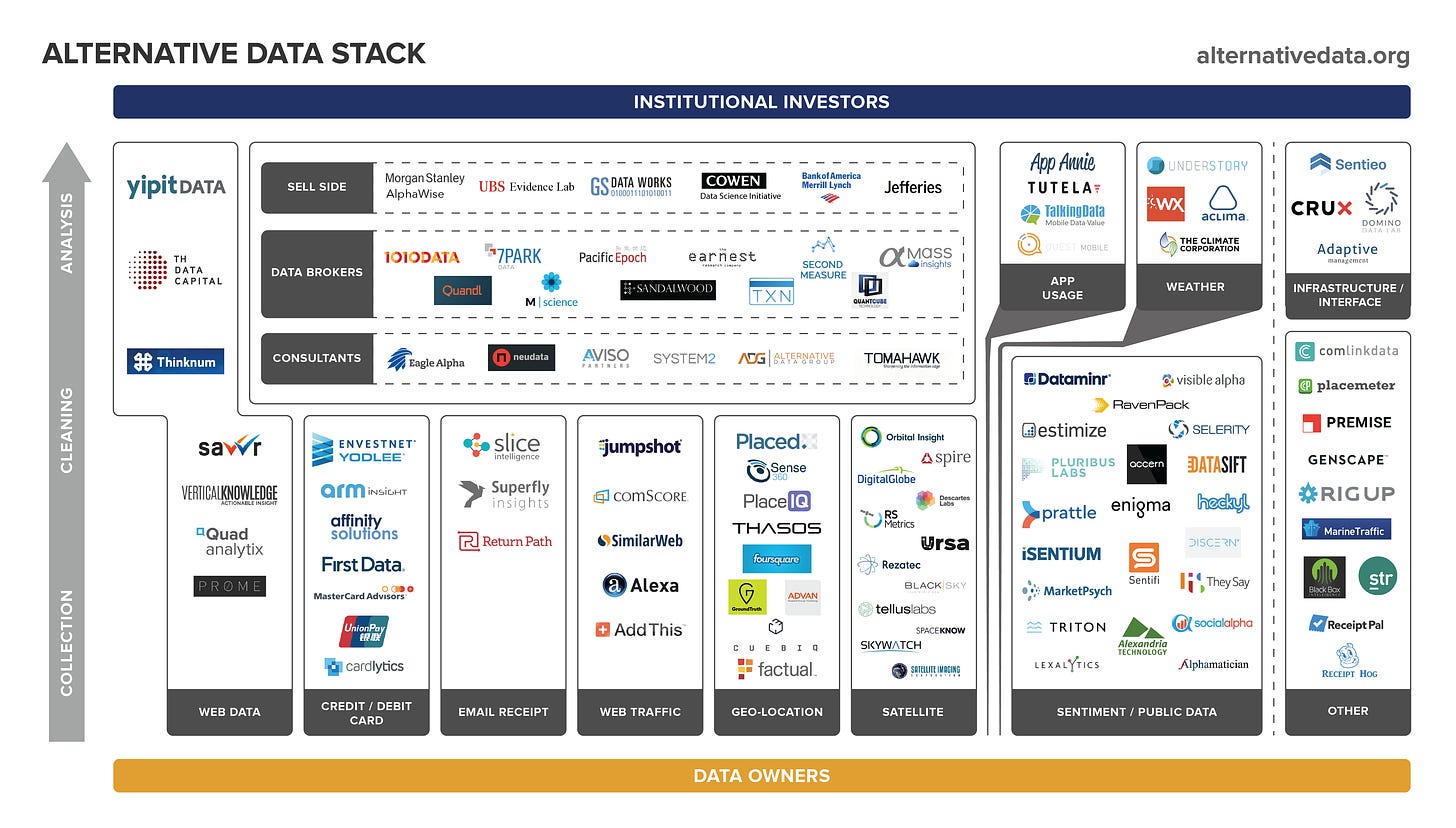
Как видно из этого слайда с alternativedata.org, в дополнение к веб-данным у нас есть спутниковые изображения, транзакции по кредитным картам, данные о настроениях и так далее.
В этом 2010 года, мы сможем лучше понять, как можно использовать спутниковые снимки в финансовых целях. Компания Remote Sensing Metrics LLC использовала спутниковые снимки для мониторинга 100 парковок Walmart в качестве репрезентативной выборки. Они ежемесячно подсчитывали количество автомобилей, припаркованных на улице, чтобы оценить квартальный доход, рассчитав поток людей.
Как вы могли догадаться, этот метод не дает точной суммы в долларах, но с подходящей моделью он может дать оценку доходов задолго до того, как общедоступные данные о публично торгуемых акциях станут доступны, возможно, за несколько месяцев до того, как данные станут общедоступными. .
Почему парсинг веб-страниц важен в среде альтернативных данных?
Как видно из предыдущего слайда, альтернативных поставщиков данных можно разделить на две группы: те, кто владеет существующими данными или преобразует их (как в примере со спутниковым изображением, упомянутом ранее, когда компания получила изображения от поставщиков и настроила свой продукт данных). для оценки доходов Walmart) и тех, кто извлекает данные из общедоступных источников и использует их для получения информации (включая веб-данные и анализ настроений).
Пример второй категории может включать компанию, которая извлекает настроения клиентов из онлайн-обзоров, чтобы определить, теряет ли целевая компания свое влияние на своих клиентов. Изучая данные электронной торговли, мы также можем определить, наблюдается ли значительный рост продаж определенного бренда по сравнению с его прямыми конкурентами, что может свидетельствовать о проблемах с продуктом или продажами.
На что обращают внимание данные, извлеченные из Интернета, в финансовой отрасли?
На финансовые рынки распространяются строгие правила, направленные на предотвращение мошенничества и инсайдерской торговли, то есть торговли акциями на основе закрытой информации о компании, а также других юридических аспектов. На самом деле использование собранных ненадлежащим образом данных может привести к юридическим последствиям для самого фонда и его руководителей.
Поэтому, если вы планируете продавать данные хедж-фондам и инвесторам, вы должны быть готовы к большому количеству бумажной волокиты. Хорошая статья Zyte содержит подробную информацию о том, что вы необходимо продемонстрировать фондам, что вы правильно собрали данные.
Как сказано в статье:
<цитата>В целом риски, связанные с альтернативными данными, можно разделить на четыре категории:
* Эксклюзивность & Инсайдерская торговля * Нарушения конфиденциальности * Нарушение авторского права * Сбор данных
Давайте кратко обобщим риски, связанные с четырьмя предыдущими пунктами.
Эксклюзивность и эффективность Инсайдерская торговля:
Как упоминалось ранее, инсайдерская торговля предполагает использование закрытых данных для торговли акциями. Это означает, что данные за платным доступом, как правило, запрещены, поскольку они не являются общедоступными для всех, а только для платных пользователей целевых веб-сайтов. Кроме того, если парсеру необходимо войти на целевой веб-сайт для получения данных, это вызывает некоторые опасения, и вы должны убедиться, что не нарушаете никаких Условий использования.
Нарушения конфиденциальности:
Это относится к очистке личных данных из Интернета, поскольку в последние годы правила конфиденциальности во всем мире, особенно в Европе с GDPR, становятся все более строгими.
По этой причине удаление личных данных, как правило, запрещено в любом проекте, если только вы не можете сделать их анонимными.
Нарушение авторских прав:
Извлечение и перепродажа данных, защищенных авторским правом, таких как фотографии и статьи, не рекомендуется и категорически запрещено.
Сбор данных:
Фонды, несомненно, захотят узнать, был ли весь процесс сбора данных максимально честным и не причинил ли он вреда целевым веб-сайтам.
По этой причине Организация по стандартам инвестиционных данных выпустила контрольный список с рекомендациями по очистке веб-страниц. Вы можете найти все пункты в связанном файле, но просто чтобы дать вам представление, вот некоторые баллы:
- Сборщик данных должен оценивать веб-сайт в соответствии с условиями файла robots.txt.
- Сборщик данных должен получать доступ к веб-сайтам таким образом, чтобы доступ не мешал их работе и не создавал чрезмерной нагрузки на их работу.
- Сборщик данных не должен получать доступ, загружать или передавать закрытые данные веб-сайта.
- Сборщик данных не должен обходить вход в систему или другие ограничения контроля оценки, такие как проверка по слову.
- Сборщик данных не должен использовать маскировку или чередование IP-адресов, чтобы избежать ограничений веб-сайтов.
- Сборщик данных должен уважать действующие уведомления о прекращении и воздержании, а также право веб-сайта регулировать условия доступа к веб-сайту и данным.
- Сборщик данных должен уважать все права собственности на авторские права и товарные знаки и не скрывать или удалять информацию об управлении авторскими правами.
Как видите, правила очень строгие, чтобы избежать возможных проблем для поставщика данных и самого фонда.
Ключевые функции извлечения данных из Интернета в финансовой сфере
Учитывая всю эту информацию и эти предпосылки, какие функции необходимы финансовой отрасли, чтобы считать набор данных интересным?
Прежде всего, важно понимать, что у фондов есть собственная стратегия изучения рынков, которая влияет на то, что они ищут. В широком смысле мы можем разделить фонды на две категории: количественные и фундаментальные. Однако многие фонды находятся где-то между этими двумя полюсами, сочетая обе стратегии.
Фундаментальные инвесторы обычно изучают экономику, анализируя бизнес-модель и факторы риска для отдельных компаний, используя восходящий подход. С другой стороны, кванты используют сложные модели машинного обучения, основанные на большом количестве данных, и ищут корреляции между данными, которые они получают, и фондовым рынком, используя нисходящий подход.
Как вы понимаете, эти два подхода требуют разных типов данных. Для фундаментальных инвесторов набор данных может быть очень специфичным для тикера акций, но он должен давать ценную информацию о бизнес-модели целевой акции. Для количественных расчетов набор данных должен иметь некоторую историю (обычно несколько лет, в зависимости от охватываемого рынка и потребностей модели) и охватывать множество акций. В противном случае добавление данных в модель только для нескольких акций может оказаться неэффективным.
Заключительные замечания
В этой статье я стремился представить ландшафт альтернативных данных, поскольку это один из растущих секторов в мире данных, в котором важную роль играет веб-скрапинг.
Это сложная среда, где действуют строгие правила в отношении источников данных, и поставщики должны доказать свою ответственность. Поэтому для фрилансера вход на рынок является сложной задачей, в то время как для уже существующих компаний это может быть относительно проще.
В зависимости от инвесторов у вас могут быть разные требования к срокам и спецификациям данных, но если вы сможете создать отличный информационный продукт, это может быть полезным полем для входа.
В следующем выпуске The Lab мы попытаемся создать набор данных для финансовых инвесторов в качестве забавного эксперимента.
:::информация Также опубликовано здесь.
:::