

Прототип, использующий выражения лица для облегчения неречевой коммуникации
31 марта 2023 г.Я страстно увлекаюсь технологиями, поэтому я был очарован многочисленными технологическими достижениями. Однако меня особенно заинтересовала вспомогательная технология, которую использовал доктор Стивен Хокинг на поздних стадиях БАС (боковой амиотрофический склероз), позволяющая ему общаться, несмотря на его неспособность говорить. Руководствуясь своей любознательной натурой, я углубился в изучение лежащей в основе технологии, и только недавно у меня появилось достаточно мотивации, чтобы взяться за разработку очень простого прототипа, имитирующего эту технологию.
Технологии
Сочетая подергивание мышц щеки и моргание глаз, доктор Хокинг использовал метод сканирования для выбора символов на экране. Несмотря на медленный темп, эта технология оказалась важным инструментом, облегчающим его общение и делящимся бесценными идеями и знаниями с миром.
В то время как система доктора Хокинга была заметно более сложной, включая адаптивный предсказатель слов после выбора каждой буквы, прототип, который мы намереваемся разработать, будет работать на более простой предпосылке. В частности, он будет обнаруживать моргание глаз и использовать его в качестве входных данных для выбора букв, отображаемых на экране. Впоследствии мы можем легко расширить это, интегрировав внешние API для облегчения прогнозирования следующего слова, а также включив функцию преобразования текста в речь. Подробнее о технологии Intel, которую использовал доктор Хокинг, можно прочитать здесь.< /p>
Исследования
Если вы хотя бы немного интересуетесь распознаванием лиц или обнаружением объектов, весьма вероятно, что вы знакомы с OpenCV. Получив некоторый опыт работы с OpenCV над проектом, связанным с обнаружением полосы движения и предотвращением столкновений транспортных средств, я начал более глубоко изучать, как я могу использовать его возможности для моего текущего проекта.
Я просмотрел многочисленные ранее существовавшие API, такие как Kairos и сервисы распознавания изображений AWS, среди прочих. Полный список этих API можно найти здесь.
Несмотря на то, что я столкнулся с некоторыми вариантами, которые не обеспечивали желаемой функциональности или оказались громоздкими для реализации, моей целью было найти удобное и легко расширяемое решение.
На начальных этапах своего исследования я наткнулся на face-api.js. — высокотехнологичный пакет, предназначенный для распознавания и обнаружения лиц. Заинтригованный примерами использования этого пакета другими, я углубился в процесс кодирования. Однако вскоре я столкнулся с проблемой, так как обнаружение моргания не было включено в функции пакета. Для обнаружения моргания требовалась высокая частота кадров, что в конечном итоге привело к падению моего браузера. Поэтому я отказался от face-api.js и стал искать альтернативные решения. Тем не менее, важно отметить, что несмотря на то, что пакет не подходит для моего проекта, он содержит несколько примечательных функций, которые можно использовать для создания действительно впечатляющих приложений.
От JS к Python
В ходе своего исследования я часто сталкивался с Python как с потенциальным решением. Учитывая мой предыдущий опыт работы с OpenCV на C#, я был заинтригован перспективой изучения Python. В конце концов, я решил, что Python OpenCV с Dlib имеет определенные перспективы, о чем я более подробно читал на pyimagesearch.com.
Хотя поначалу я столкнулся с некоторыми трудностями при установке необходимых зависимостей на свой Mac, в конце концов мне удалось настроить среду разработки и приступить к кодированию. Вскоре мне удалось создать функциональный код для обнаружения моргания, хотя и с некоторыми ограничениями. В частности, обнаружение моргания было не особенно эффективным, а создание пользовательского интерфейса на Python оказалось громоздким. Тем не менее, решение было более эффективным и оперативным, чем face-api.js, и ни разу не привело к зависанию или сбою моего компьютера.
Однако с Python возникло дополнительное ограничение, поскольку создание пользовательского интерфейса оказалось довольно сложной задачей. Продолжая свои исследования, я наткнулся на интересную альтернативу в Google Mediapipe. Что действительно поразило меня в этом решении, так это то, что его можно интегрировать в мобильные приложения, возможность, которая изначально не приходила мне в голову, но, тем не менее, вызвала мой интерес.
:::подсказка ПРИМЕЧАНИЕ. Официальная документация Mediapipe переносится по этой ссылке с 3 апреля 2023 года.
:::
Вернуться к JS
В свете вышеупомянутых ограничений Python я был вынужден вернуться к Javascript. Кроме того, привлекательные и доступные демонстрации, доступные через Mediapipe, были еще одним фактором, который привлек меня к использованию JS. Немного поэкспериментировав и покопавшись в JS, я убедился, что это идеальное решение для моего проекта.
Начало работы
Хотя изначально я намеревался создать приложение React Native, использующее распознавание лиц Mediapipe, нехватка времени вынудила меня вместо этого выбрать ванильный проект JS. Тем не менее, адаптация этого кода к приложению React или Vue JS должна быть относительно простым процессом для всех, кто в этом заинтересован. Кроме того, стоит отметить, что к тому времени, когда вы читаете эту статью, я, возможно, уже разработал приложение React.
Mediapipe имеет значительное преимущество перед другими альтернативами, такими как face-api.js и Python OpenCV, поскольку он может оценивать 468 трехмерных ориентиров лица в режиме реального времени, по сравнению с только 68 ориентирами в модели, используемой с Python OpenCV и face-api.js. . Это важное преимущество, поскольку оно позволяет более эффективно определять выражение лица.
Ориентиры лица — это важные особенности человеческого лица, которые позволяют нам различать разные лица. Ниже приведены лицевые ориентиры, которые я использовал с Python и face-api.js:

Вот те, которые используются MediaPipe:

Вот список всех ориентиров: n https://github.com/tensorflow/tfjs-models/blob/838611c02f51159afdd77469ce67f0e26b7bbb23/face-landmarks-detection/src/mediapipe-facemesh/keypoints.ts
А вот пример реального лица с фейсмешем:

Очевидно, что эталонная модель Mediapipe намного превосходит другие модели, и я мог легко заметить разницу в точности обнаружения. Подробнее о ориентирах можно прочитать здесь.
Обнаружение моргания
По умолчанию пример кода дает вам сетку лица, наложенную на ваше лицо, когда вы смотрите в камеру. Но любое определение выражения лица должно быть сделано вами. Было 2 подхода, которые я мог использовать для обнаружения моргания:
- Следите за тем, чтобы радужная оболочка исчезала, когда глаз закрывался.
- Определить, когда верхнее веко соединяется с нижним веком.
Я решил пойти по второму пути. Обратите внимание на ориентиры на правом глазу ниже. Когда глаз закрыт, расстояние между вертикальными ориентирами 27 и 23 значительно уменьшается (почти до 0), а расстояние между горизонтальными точками 130 и 243 остается почти постоянным.
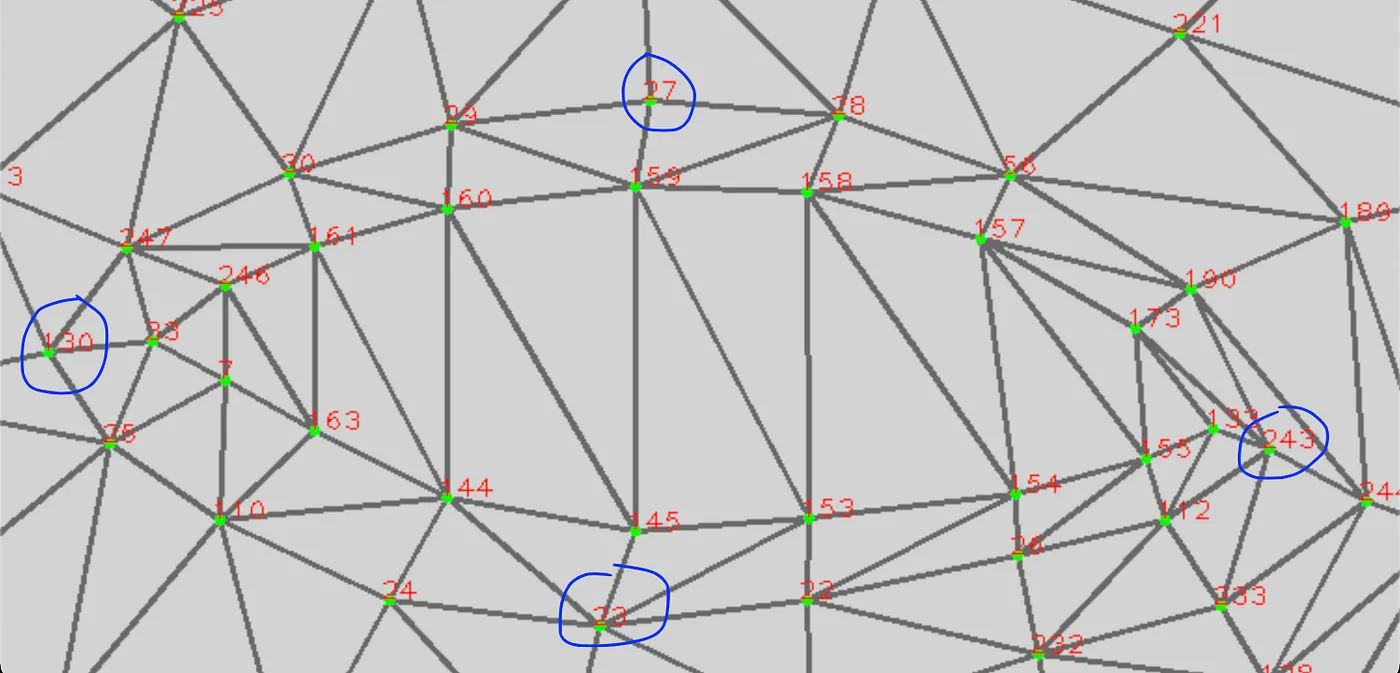
Вот функция обнаружения моргания:
function blinkRatio(landmarks) {
// RIGHT EYE
// horizontal line
let rh_right = landmarks[33]
let rh_left = landmarks[133]
// vertical line
let rv_top = landmarks[159]
let rv_bottom = landmarks[145]
// LEFT EYE
// horizontal line
let lh_right = landmarks[362]
let lh_left = landmarks[263]
// vertical line
let lv_top = landmarks[386]
let lv_bottom = landmarks[264]
// Finding Distance Right Eye
let rhDistance = euclideanDistance(rh_right, rh_left)
let rvDistance = euclideanDistance(rv_top, rv_bottom)
// Finding Distance Left Eye
let lvDistance = euclideanDistance(lv_top, lv_bottom)
let lhDistance = euclideanDistance(lh_right, lh_left)
// Finding ratio of LEFT and Right Eyes
let reRatio = rhDistance / rvDistance
let leRatio = lhDistance / lvDistance
let ratio = (reRatio + leRatio) / 2
return ratio
}
Мы проверяем оба глаза, потому что мы хотим, чтобы оба глаза были закрыты для моргания. Еще один способ использовать обнаружение глаз — идентифицировать подмигивания, которые можно использовать в качестве другого пользовательского ввода. Однако обнаружить подмигивание может быть непросто, поскольку, когда вы закрываете один глаз, другой глаз также немного сужает свою вертикальную высоту. Хотя я пытался обнаруживать подмигивания, используя модель 68 ориентиров при работе с Python, результаты были удачными. С моделью MediaPipe, имеющей больше ориентиров для глаза, я ожидаю лучших результатов для обнаружения подмигивания.
Возвращаясь к теме моргания, я понял, что использование естественного моргания в качестве пользовательского ввода приводит к непреднамеренным действиям. Следовательно, мне пришлось разработать альтернативный подход. Мое решение заключалось в регистрации ввода только в том случае, если пользователь держал глаза закрытыми немного дольше, чем обычное моргание. В частности, я классифицировал моргание как действия пользователя только в том случае, если глаза оставались закрытыми в течение пяти последовательных видеокадров.
let CLOSED_EYES_FRAME = 5
Изменение длины закрытия глаза позволяло использовать дополнительные пользовательские параметры, такие как возможность удалить ввод или перезапустить подсказки.
let BACKSPACE_EYES_FRAME = 20
let RESTART_EYES_FRAME = 40
Ниже приведен фрагмент кода, который обнаруживает ввод пользователя и отличает его от ввода, удаления или перезапуска.
if (finalratio > CLOSED_EYE_RATIO) {
CEF_COUNTER += 1
} else {
// debugger
if (CEF_COUNTER > CLOSED_EYES_FRAME) {
TOTAL_BLINKS += 1
blinkDetected = true
document.getElementById('blinks').innerHTML = TOTAL_BLINKS
document.getElementById('ratio').innerHTML = finalratio
}
if (CEF_COUNTER > RESTART_EYES_FRAME) {
console.log('restart frames detected')
restart()
} else if (CEF_COUNTER > BACKSPACE_EYES_FRAME) {
console.log('backspace frames detected')
backspace()
restart()
}
CEF_COUNTER = 0
}
Список будущих улучшений
- Добавьте больше выражений — обнаружение взгляда влево/вправо (можно использовать для удаления и автоматического завершения), обнаружение приподнятых бровей.
- Обучающий интерфейс для пользователей перед началом использования приложения.
- Предсказание следующего слова с помощью API.
- Мобильное приложение.
:::информация Ссылка на проект: https://github.com/karamvirs/face-talk
:::
:::подсказка Главный источник изображения: Tumisu Pixabay
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27683)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)