:::информация Этот документ доступен на arxiv под лицензией CC 4.0.
Авторы:
(1) Shanshan Han & Qifan Zhang, UCI;
(2) Вэньсюань Ву, Техасский университет A&M;
(3) Baturalp Buyukates, Yuhang Yao & Weizhao Jin, USC;
(4) Салман Авестимер, USC & ФедМЛ.
:::
Таблица ссылок
Предлагаемое двухэтапное обнаружение аномалий
Проверяемое обнаружение аномалий с использованием ZKP
5 ОЦЕНОК
В этом разделе представлена всесторонняя оценка нашего подхода. Мы уделяем особое внимание следующим аспектам: (i) эффективность обнаружения перекрестных проверок; (ii) эффективность обнаружения перекрестных клиентов; (iii) сравнение эффективности нашего подхода с другими средствами защиты; (iv) устойчивость нашего подхода к динамическому подмножеству вредоносных клиентов; (v) оборонное освещение нашего подхода на различных моделях; (vi) эффективность нашего протокола обнаружения аномалий, проверенного ZKP.
Экспериментальная установка. Краткое описание наборов данных и моделей для оценок можно найти в таблице 1. По умолчанию мы используем CNN и не-i.i.d. Набор данных FEMNIST (параметр разделения α = 0,5), как не-i.i.d. сеттинг точно отражает сценарии реального мира. В наших экспериментах мы используем FedAVG. По умолчанию для обучения FL мы используем 10 клиентов — все клиенты участвуют в обучении в каждом раунде. Мы используем три механизма атаки, включая византийские атаки случайного режима (Чен и др., 2017; Фанг и др., 2020) и бэкдор-атаку с заменой модели (Багдасарян и др., 2020b). Мы используем три базовых защитных механизма: м-Крум (Blanchard et al., 2017), Foolsgold (Fung et al., 2020) и RFA (Pillutla et al., 2022). Для m-Krum мы установили m равным 5, что означает, что 5 из 10 представленных локальных моделей участвуют в агрегировании в каждом раунде обучения FL. По умолчанию результаты оцениваются с точностью глобальной модели. Оценки обнаружения аномалий проводятся на сервере с 8 графическими процессорами NVIDIA A100-SXM4-80 ГБ, а оценки ZKP проводятся на Amazon AWS с экземпляром m5a.4xlarge с 16 ядрами ЦП и 32 ГБ памяти. Наш код реализован с использованием эталонного теста FedMLSecurity Han et al. (2023).
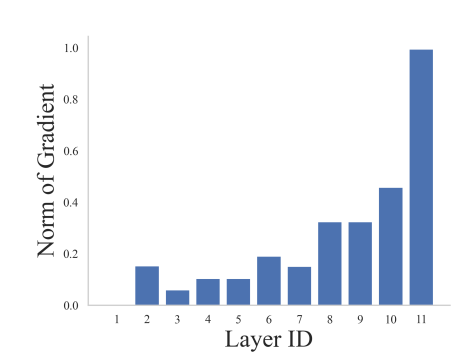
Exp1: Выбор уровня важности. Мы используем норму градиентов для оценки «чувствительности» каждого слоя. Слой с высокой нормой указывает на высокую чувствительность и может представлять всю модель. Мы оцениваем чувствительность слоев CNN, RNN и ResNet56. Результаты для RNN показаны на рисунке 4, а результаты для ResNet56 и CNN отложены до рисунков 14 и 13 в разделе B.2 соответственно. Результаты показывают, что мы можем использовать предпоследний уровень модели в качестве уровня важности, поскольку он включает адекватную информацию обо всей модели.
5.1 ОЦЕНКА КРУГЛОЙ ПРОВЕРКИ
В этом подразделе мы оцениваем эффективность перекрестной проверки при обнаружении атак. Мы используем случайные византийские атаки и бэкдор-атаки с заменой модели и устанавливаем вероятность атаки на 40% для каждой итерации FL, где 1 из клиентов является злонамеренным, когда происходит атака. В идеале перекрестная проверка должна точно подтвердить отсутствие или наличие нападения. Эффективность нашего подхода оценивается точностью перекрестной проверки, которая измеряет долю итераций, в которых алгоритм правильно обнаруживает случаи с атакой или без нее, по отношению к общему количеству итераций. 100% точность перекрестной проверки означает, что все атаки обнаружены, и ни один из неопасных случаев не идентифицируется как «атаки».
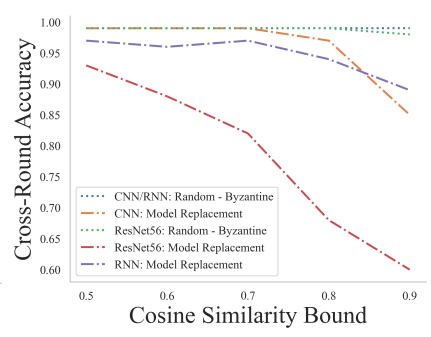
Exp2: Влияние порога сходства. Мы оцениваем влияние косинусного порога сходства γ при перекрестной проверке, устанавливая γ равным 0,5, 0,6, 0,7, 0,8 и 0,9. Согласно Алгоритму 2, значение косинуса ниже γ указывает на меньшее сходство между моделями клиентов текущего раунда и последнего раунда, что может быть индикатором атаки. Как показано на рисунке 5, точность перекрестного раунда близка к 100% в случае случайных византийских атак. Кроме того, если порог косинусного сходства γ установлен равным 0,5, производительность во всех случаях хорошая, с точностью обнаружения перекрестных раундов не менее 93%.
5.2 ОЦЕНКА МЕЖКЛИЕНТСКОГО ОБНАРУЖЕНИЯ
В этом подразделе оценивается, может ли межклиентское обнаружение успешно обнаруживать вредоносные сообщения клиентов с учетом случаев атак. Мы оцениваем качество обнаружения аномалий с помощью модифицированных положительных прогнозных значений (PPV) (Fletcher, 2019), т. е. точности, доли положительных результатов в статистике и диагностических тестах, которые являются истинно положительными результатами. Обозначим количество истинно положительных и ложноположительных результатов как NTP и NFP соответственно, тогда PPV = NTP NTP+NFP . В контексте обнаружения аномалий в FL клиентские материалы, которые определяются как «вредоносные» и на самом деле являются вредоносными, определяются как True Positive, что соответствует NTP, тогда как клиентские материалы, которые определяются как «вредоносные», даже если они безобидны, определяются как Ложное срабатывание, соответствующее NFP. Поскольку мы хотели бы, чтобы PPV раскрывал связь между NTP и общим количеством вредоносных отправок во всех итерациях FL, обозначаемым как Ntotal, независимо от того, обнаружены они или нет, мы вводим модифицированный PPV как PPV = NTP NTP+NFP+Ntotal, где 0 ≤ ППВ ≤ 1 2 . В идеальных случаях обнаруживаются все вредоносные отправки, где NTP = Ntotal, а PPV равен 1 2. Из-за ограничений по количеству страниц мы отложили доказательство этого утверждения до Приложения A.1.
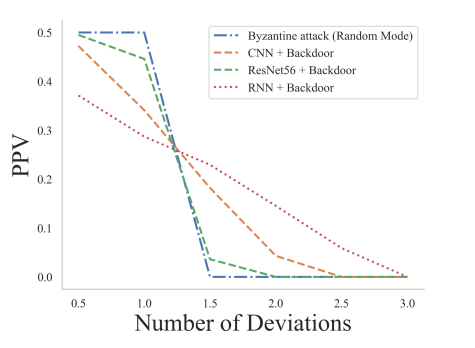
Эксперимент 3: Выбор количества отклонений. В этом эксперименте PPV используется для оценки влияния количества отклонений, т. е. параметра λ в границе аномалии µ + λσ. Чтобы оценить сложный случай, когда большая часть клиентов являются вредоносными, мы установили, что 4 из 10 клиентов являются вредоносными в каждом раунде обучения FL. Учитывая количество итераций FL равное 100, общее количество вредоносных рассылок Ntotal равно 400. Задаем количество отклонений λ равным 0,5, 1, 1,5, 2, 2,5 и 3. Выбираем византийскую атаку случайного режима. и атаку замены модели, и оценим наш подход к трем задачам, а именно: i) CNN+ФЕМНИСТ, ii) ResNet-56+Cifar100 и iii) RNN + Шекспир. Результаты, показанные на рисунке 6, показывают, что когда λ равно 0,5, результаты являются лучшими, при этом PPV составляет не менее 0,37. Фактически, когда λ равно 0,5, все вредоносные отправки обнаруживаются для случайной византийской атаки для всех трех задач, при этом PPV составляет ровно 1/2. В последующих экспериментах, если не указано иное, мы установили λ равным 0,5 по умолчанию.
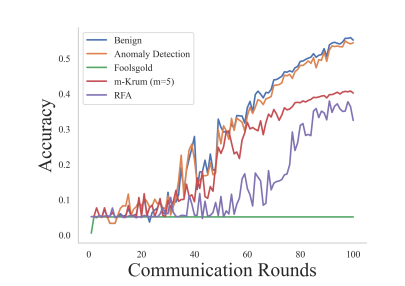
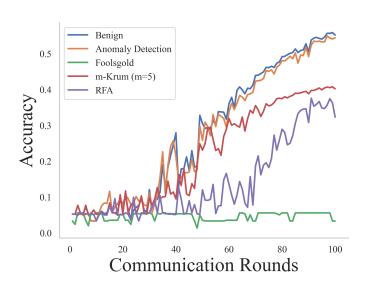
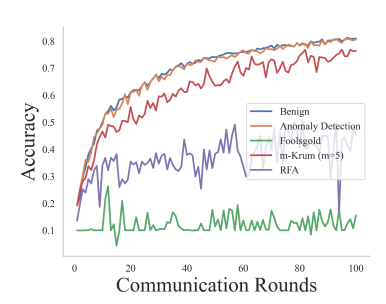
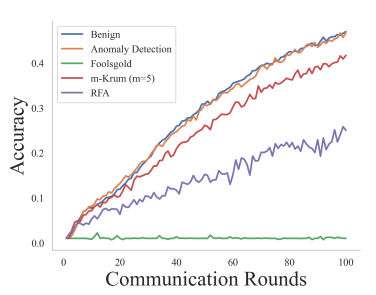
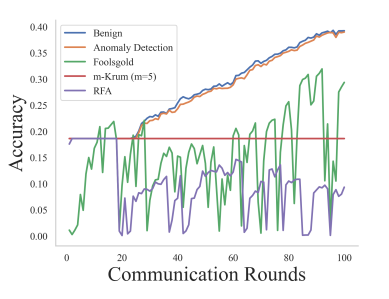
Эксперимент 4: Сравнение обнаружения аномалий и различных средств защиты от атак. В этом эксперименте оценивается эффект нашего подхода по сравнению с различными защитными механизмами, включая Foolsgold, m-Krum (m = 5) и RFA в контексте продолжающихся атак. Мы включаем «мягкий» базовый сценарий без активированной атаки или защиты, а также выбираем случайные византийские атаки и бэкдорные атаки с заменой модели. Результаты случайной византийской атаки и бэкдор-атаки с заменой модели показаны на рисунках 7 и 8 соответственно. Эти результаты показывают, что наш подход эффективно смягчает негативное воздействие атак и значительно превосходит другие средства защиты, а точность тестирования намного ближе к безопасному случаю.
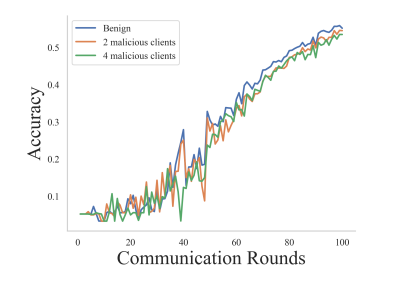
Эксперимент 5. Изменение количества вредоносных клиентов. В этом эксперименте оценивается влияние различного количества вредоносных клиентов на точность тестирования. Мы установили количество злонамеренных клиентов из 10 клиентов в каждом раунде обучения FL равным 2 и 4 и включили базовый случай, когда все клиенты являются безопасными. Как показано на рисунке 9, точность теста остается относительно постоянной для различного количества злонамеренных клиентов, поскольку в каждом раунде обучения FL наш подход отфильтровывает локальные модели, которые имеют тенденцию быть вредоносными, чтобы эффективно минимизировать влияние моделей вредоносных клиентов на агрегацию. .
Опыт 6: Оценки различных моделей. Мы оцениваем механизмы защиты от случайного режима византийской атаки с использованием различных моделей и наборов данных, включая: i) ResNet-20 + Cifar10, ii) ResNet-56 + Cifar100 и iii) RNN + Шекспир. Результаты показаны на рисунках 10, 11 и 12 соответственно. Результаты показывают, что, хотя базовые механизмы защиты могут смягчить воздействие атак в большинстве случаев, некоторые средства защиты могут дать сбой в некоторых задачах, например, m-Krum не работает в RNN на рисунке 12. Это связано с тем, что эти методы либо выбирают фиксированное количество локальные модели или повторно взвешивать локальные модели при агрегировании, что потенциально исключает некоторые локальные модели, важные для агрегирования, что приводит к неизменной точности теста в последующих итерациях FL. Напротив, наш подход превосходит эти базовые методы защиты, эффективно отфильтровывая локальные модели, которые обнаруживаются как «выбросы», с точностью тестирования, близкой к безопасным сценариям.
5.3 РАБОТА ЗКП
Упражнение 7: Оценка размера схемы ZKP, времени проверки и времени проверки. Мы внедряем систему ZKP в Circcom (Circom Contributors, 2022). Эта система включает в себя модуль перекрестной проверки и перекрестного обнаружения клиентов. Мы также реализуем модуль доказательства, который содержит код JavaScript для создания свидетеля для ZKP, а также для выполнения квантования с фиксированной точкой. В наших экспериментах мы включаем CNN, RNN и ResNet-56 в качестве моделей машинного обучения. В частности, мы извлекаем параметры только из предпоследнего слоя каждой модели, то есть уровня важности, в качестве нашего веса, чтобы уменьшить сложность. Например, предпоследний уровень модели CNN содержит только 7 936 обучаемых параметров, а не 1 199 882, если бы мы использовали всю модель. Мы реализовали оба алгоритма на 10 клиентах и представили результаты в Таблице 2.
