

Развертывание Elasticsearch Elasticsearch Zero-Laytime с поиском Hibernate: стратегия проката, которая работает
13 августа 2025 г.У нас была эта проблема, когда нам нужно было обновить наши сопоставления Elasticsearch, не нарушая поиск во время развертывания. Наша настройка довольно стандартная: приложение Spring Boot с данными продукта Hibernate Search Indexing для Elasticsearch, работая на Kubernetes с развертываниями на ходу. Отлично работает, пока вам не нужно изменить свою поисковую схему.
Основная проблема заключается в том, что во время развертывания на ходу у вас есть старые и новые стручки, работающие одновременно, и они ожидают различных индексных структур и отображений. Схемы обновления требуют времени простоя, пока новый индекс создан и документы индексируются.
Проблема, с которой мы столкнулись
Наши конкретные болевые точки были:
- Добавление новых полейне нарушая существующую функциональность
- Изменение анализаторов или полевые отображениябез отбоя в поисках
- Сохранение функционала поискаВ то время как стручки циклически проходят через версии
- Управление периодом сосуществованияГде половина ваших стручков запускают старую версию и наполовину запустите новую версию
Этот последний действительно получил нас. Kubernetes Rolling развертывания великолепны, но они предполагают, что ваши приложения могут мирно сосуществовать. Когда ваша схема базы данных меняется, это предположение распадается довольно быстро. На самом деле мы не решили эту проблему, мы гарантировали, что смешанные версии ничего не ломают на этапе перехода.
Почему мы избегали сложных решений
Когда мы начали планировать это, мы пошли в кроличьи дыры. Провели недели, глядя на сложные подходы, которые казались хорошими на бумаге.
Основанный по псевдонизам управление индексомС фоновым переодежением звучало умно. Я действительно увлекался этой идеей о том, что все эти причудливые псевдонимы переключались на заднем плане. Но когда я на самом деле думал о том, чтобы отладки его во время инцидента, это казалось слишком сложным.
Голубо-зеленые развертыванияопределенно сработает. Но запуск двух полных кластеров Elasticsearch только для развертывания поиска казался излишним для нашей настройки.
Внешние инструменты оркестровки- Мы посмотрели на несколько. Но у нас уже было достаточно движущихся кусочков. Добавление еще одной услуги, которая может потерпеть неудачу во время развертывания, было рискованным и потребовало большего обслуживания.
В какой -то момент мы поняли, что делаем это слишком сложным. Именно тогда мы отступили и подумали об этом по -другому.
Как это на самом деле работает
Итак, вот что мы закончили. Каждая версия схемы получает свой собственный индекс, довольно проста, когда вы думаете об этом. Когда вы развертываетеv2вашего приложения, это создаетProducts_v2индекс, пока стручки V1 продолжают помечать вместе сПродукция_v1Полем
Во время развертывания прохождения запросы могут попасть в любую версию, но это оказалось в порядке. Каждый стручок просто ищет свой собственный индекс и возвращает действительные результаты. После того, как развертывание завершится и все стручки будут работать V2, вы можете очистить старый индекс.
Вот что на самом деле происходит во время развертывания:
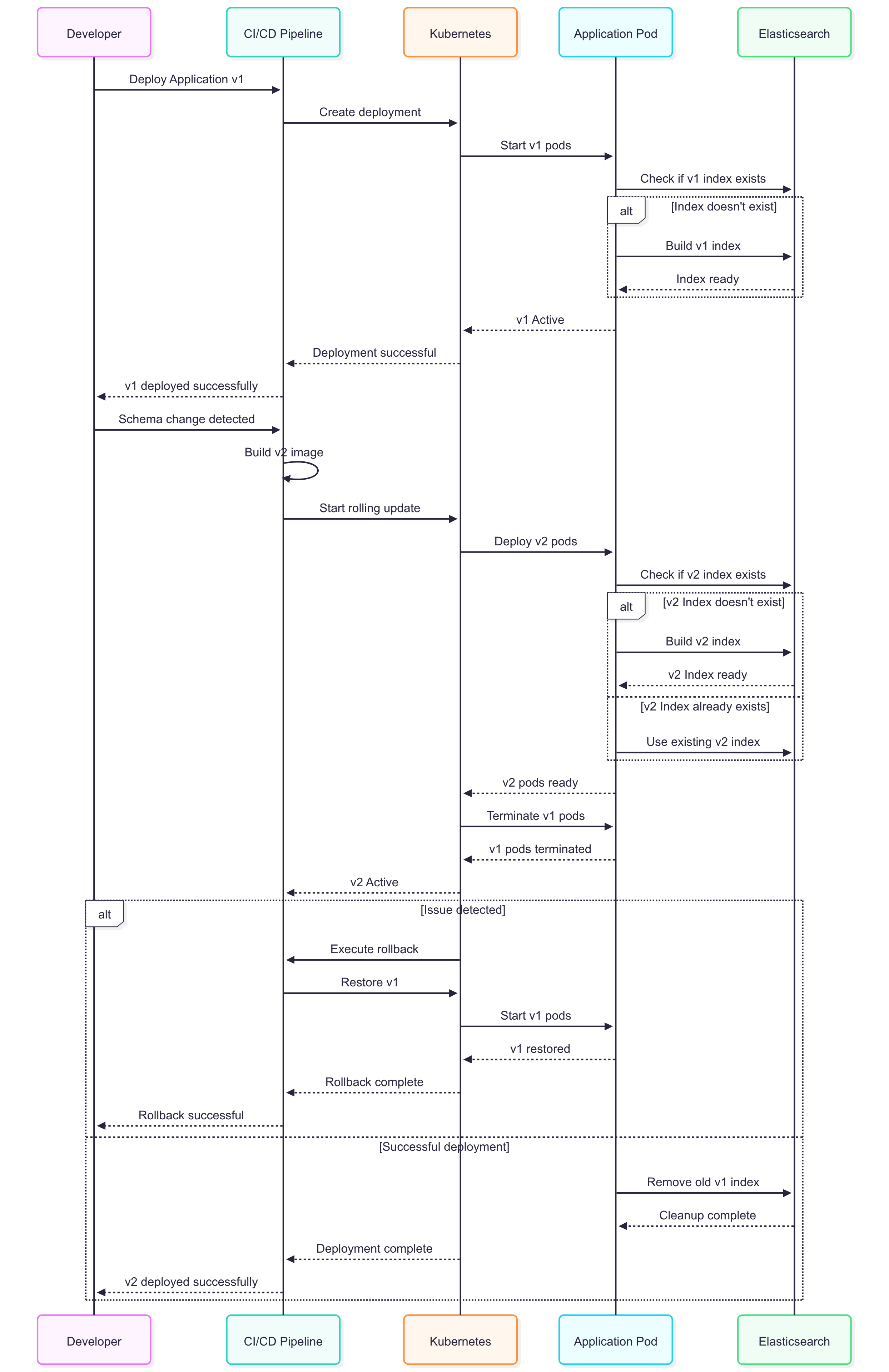
sequenceDiagram
participant Dev as Developer
participant CI as CI/CD Pipeline
participant K8s as Kubernetes
participant App as Application Pod
participant ES as Elasticsearch
Dev->>CI: Deploy Application v1
CI->>K8s: Create deployment
K8s->>App: Start v1 pods
App->>ES: Check if v1 index exists
alt Index doesn't exist
App->>ES: Build v1 index
ES-->>App: Index ready
end
App-->>K8s: v1 Active
K8s-->>CI: Deployment successful
CI-->>Dev: v1 deployed successfully
Dev->>CI: Schema change detected
CI->>CI: Build v2 image
CI->>K8s: Start rolling update
K8s->>App: Deploy v2 pods
App->>ES: Check if v2 index exists
alt v2 Index doesn't exist
App->>ES: Build v2 index
ES-->>App: v2 Index ready
else v2 Index already exists
App->>ES: Use existing v2 index
end
App-->>K8s: v2 pods ready
K8s->>App: Terminate v1 pods
App-->>K8s: v1 pods terminated
K8s-->>CI: v2 Active
alt Issue detected
K8s->>CI: Execute rollback
CI->>K8s: Restore v1
K8s->>App: Start v1 pods
App-->>K8s: v1 restored
K8s-->>CI: Rollback complete
CI-->>Dev: Rollback successful
else Successful deployment
App->>ES: Remove old v1 index
ES-->>App: Cleanup complete
K8s-->>CI: Deployment complete
CI-->>Dev: v2 deployed successfully
end
Детали реализации
Конфигурация версии
Прежде всего, добавьте настройку версии в свою конфигурацию:
app:
search:
index-version: v1
hibernate:
search:
backend:
hosts: elasticsearch:9200
protocol: https
Когда вам нужны изменения схемы, подключите ее к V2. Мы начали с V1, но вы можете использовать любую схему именования, работающая для вас.
Стратегия макета индекса индекса
Настоящий трюк здесь заключается в том, чтобы получить поиск Hibernate для автоматического привлечения версии к вашим именам индекса. Нам пришлось написать обычайIndexlayoutStrategyдля этого:
@Component
public class VersionedIndexLayoutStrategy implements IndexLayoutStrategy {
@Value("${app.search.index-version}")
private String indexVersion;
@Override
public String createInitialElasticsearchIndexName(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_" + indexVersion;
}
@Override
public String createWriteAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_write_" + indexVersion;
}
@Override
public String createReadAlias(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_read";
}
@Override
public String extractUniqueKeyFromHibernateSearchIndexName(String hibernateSearchIndexName) {
return hibernateSearchIndexName + "_" + indexVersion;
}
@Override
public String extractUniqueKeyFromElasticsearchIndexName(String elasticsearchIndexName) {
return elasticsearchIndexName;
}
}
Конфигурация поиска с гибернатом
Зацепите это в конфигурацию поиска Hibernate:
@Configuration
public class ElasticsearchConfig {
@Autowired
private VersionedIndexLayoutStrategy versionedIndexLayoutStrategy;
@Bean
public HibernateSearchElasticsearchConfigurer hibernateSearchConfigurer() {
return context -> {
ElasticsearchBackendConfiguration backendConfig = context.backend();
backendConfig.layout().strategy(versionedIndexLayoutStrategy);
};
}
}
Обработка координации POD
Вот где это становится интересным. Во время развертывания на ходу у вас может быть несколько новых стручков. Вы действительно не хотите, чтобы каждый пытался создать один и тот же индекс. Это просто расточительно и может вызвать странные условия гонки.
Мы нашли способ использовать Elasticsearch_метаПоле как координационный механизм. В основном первый стручок, который начал строить, отмечает индекс как «уже построенный», а другие пропускают его.
@Service
public class IndexBuildService {
@Autowired
private SearchSession searchSession;
@Autowired
private ElasticsearchClient elasticsearchClient;
@Value("${app.search.index-version}")
private String indexVersion;
private static final Logger log = LoggerFactory.getLogger(IndexBuildService.class);
@EventListener
public void onContextRefresh(ContextRefreshedEvent event) {
buildIndexIfNeeded();
}
private void buildIndexIfNeeded() {
String indexName = "products_" + indexVersion;
try {
if (isIndexAlreadyBuilt(indexName)) {
log.info("Index {} already built, skipping", indexName);
return;
}
log.info("Building index {} - this takes a few minutes", indexName);
searchSession.massIndexer(Product.class)
.purgeAllOnStart(true)
.typesToIndexInParallel(1)
.batchSizeToLoadObjects(100)
.threadsToLoadObjects(4)
.idFetchSize(1000)
.startAndWait();
markIndexAsBuilt(indexName);
log.info("Done building index {}", indexName);
} catch (Exception e) {
log.error("Index build failed for {}: {}", indexName, e.getMessage());
throw new RuntimeException("Index build failed", e);
}
}
private boolean isIndexAlreadyBuilt(String indexName) {
try {
boolean exists = elasticsearchClient.indices().exists(
ExistsRequest.of(e -> e.index(indexName))
).value();
if (!exists) {
return false;
}
var mappingResponse = elasticsearchClient.indices().getMapping(
GetMappingRequest.of(g -> g.index(indexName))
);
var mapping = mappingResponse.result().get(indexName);
if (mapping != null && mapping.mappings() != null) {
var meta = mapping.mappings().meta();
if (meta != null && meta.containsKey("index_built")) {
return "true".equals(meta.get("index_built").toString());
}
}
return false;
} catch (Exception e) {
log.warn("Couldn't check build status for {}: {}", indexName, e.getMessage());
// When in doubt, assume it's not built and let this pod try
return false;
}
}
private void markIndexAsBuilt(String indexName) {
try {
Map<String, JsonData> metaData = Map.of(
"index_built", JsonData.of("true"),
"built_at", JsonData.of(Instant.now().toString())
);
elasticsearchClient.indices().putMapping(PutMappingRequest.of(p -> p
.index(indexName)
.meta(metaData)
));
log.info("Marked {} as built", indexName);
} catch (Exception e) {
log.error("Failed to mark index as built: {}", e.getMessage());
}
}
}
Классы организации остаются неизменными
Ваши классы сущности остаются такими же:
@Entity
@Indexed(index = "products")
public class Product {
@Id
@DocumentId
private Long id;
@FullTextField(analyzer = "standard")
private String name;
@FullTextField(analyzer = "keyword") // Added this field in v2
private String category;
@KeywordField
private String status;
// getters/setters...
}
Поисковая служба также остается простым
Ваша логика поиска не должна знать о версиях:
@Service
public class ProductSearchService {
@Autowired
private SearchSession searchSession;
public List<Product> searchProducts(String query) {
return searchSession.search(Product.class)
.where(f -> f.bool()
.should(f.match().field("name").matching(query))
.should(f.match().field("category").matching(query)))
.fetchHits(20);
}
}
АIndexlayoutStrategyОбрабатывает маршрутизацию к правильному индексу версии автоматически.
Уроки извлечены
Индексное здание требует времени
Для нашего индекса документов ~ 200 тыс. Индекс, индексация обычно занимает 5-6 минут.
Память важна
Массовая индексация использует много памяти. Убедитесь, что у вас достаточно.
Очистка по -прежнему ручной
Старые индексы просто сидят там, пока вы не решите удалить их, предполагая, что вы уверены, что нет необходимости в отказе.
Ответы работают хорошо
Если вам нужно отказаться от развертывания, старые стручки возвращаются и используют свой первоначальный индекс. Работает гладко.
Наш процесс развертывания
Наш процесс не что -то необычное:
- Убить версиюномер в файле конфигурации и внесите изменения схемы
- Проверка на Dev и Pre-Prod Empironments
- Смотрите журналы стартаповЧтобы убедиться, что индекс строится должным образом
- Запустите тестовые запросыЧтобы проверить функциональность поиска
- Очистить старые индексы
Почему этот подход работает для нас
Самая большая победа - не приходится много думать об этом. После того, как он будет настроен, развертывания просто работают. Нет координации между службами, нет фоновых процессов для мониторинга, нет сложных процедур отката, когда что -то идет вбок.
Хранение стоит немного дороже, так как у вас есть дублирующие индексы, которые временно сидят вокруг, но дело со сложной системой развертывания будет стоить нам дороже в инженерном времени. Кроме того, в нашем кластере Elasticsearch есть много места.
Альтернативы, которые мы рассмотрели
Голубо-зеленые развертыванияВ нашем исследовании появилось, но запуск дублирующих среде для развертывания поиска казался чрезмерным.
REINDEX APIСначала казалось многообещающим, но когда мы проверили его с помощью нашего полного набора данных, это занимало вечно. Может быть, это будет работать для меньших индексов, но не практично для нашего варианта использования.
Псевдоним переключениеС фоновым повторным реиндексированием в теории было умно, но обработка ошибок быстро усложнилась. Что произойдет, если реиндекс не удастся на полпути? Что если новое отображение несовместимо? Слишком много краевых случаев.
Последние мысли
Этот подход работает для нас уже около 8 месяцев. Это не самое элегантное решение. В конечном итоге вы станете временными дублирующими индексами и ручной очисткой, но это надежно и легко понять.
Ключевым пониманием для нас было понимание, что простые решения часто лучше, чем умные. Вместо того, чтобы бороться с тем, как работают Kubernetes Dlling Deployments, мы разработали что -то, что работает с ними естественным образом.
Ваша ситуация может быть другой. Если у вас есть огромные индексы или действительно жесткие ограничения хранения, этот подход может не сработать. Но для большинства приложений простота стоит дополнительной стоимости хранения.
Если вы имеете дело с подобными проблемами, попробуйте. Код не слишком сложный, и как только он работает, вы можете в основном забыть об этом.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27294)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)