

Ваш следующий робот может подумать пальцами
13 июня 2025 г.Авторы:
(1) Самсон Ю, кафедра компьютерных наук, Национальный университет Сингапура (samson.yu@u.nus.edu);
(2) Кельвин Лин. Департамент компьютерных наук, Национальный университет Сингапура;
(3) с тревогой Сяо, кафедра компьютерных наук, Национальный университет Сингапура;
(4) Цзяфей Дуан, Вашингтонский университет;
(5) Гарольд Сох, кафедра компьютерных наук, Национальный университет Сингапура и Институт интеллектуальных систем NUS (harold@comp.nus.edu.sg).
Таблица ссылок
- Аннотация и I. Введение
- II Связанная работа
- Iii. Физиклеар - тактильное и физическое понимание обучения и оценки
- IV Осьминог-физические рассуждения с осью осьминоги
- V. Экспериментальная установка
- VI Экспериментальные результаты
- VII. Абляции
- VIII. Заключение и обсуждение, подтверждения и ссылки
- Приложение для осьминоги: рассуждения о свойстве объекта с большими моделями тактильно-языка
- Приложение A: сведения об аннотации
- Приложение B: сведения о объекте
- Приложение C: Статистика недвижимости
- Приложение D: образец статистики видео
- Приложение E: Анализ энкодера
- Приложение F: PG-Instructblip Avocado Прогнозирование имущества.
- Приложение для осьминоги: рассуждения о свойстве объекта с большими моделями тактильно-языка
VIII. Заключение и обсуждение
В этой работе мы расширили большие модели на языке зрения (LVLMS) для обработки и описания тактильных входов с использованием физических свойств. Мы предложили тактильный набор данных под названием Physiclear, включающий данные из датчиков зрения (камеры) и тактильных (гельзольных) датчиков, собранных из повседневных объектов, наряду с аннотациями физического свойства. Мы также представляем Octopi, большую тактильноязычную модель, обученную с использованием таких наборов данных, как Physilear для выполнения рассуждений физических свойств с использованием тактильных входов.
Наши эксперименты показывают, что осьминоги могут описывать тактильные сигналы из новых невидимых объектов и что предполагаемые физические свойства можно использовать для физических рассуждений и выполнения задач робота в сценариях с визуальной двусмысленностью. Мы изучили влияние различных компонентов в осьминогах и обнаружили, что использование визуального энкодера, специфичного для конкретного задачи, который настраивается на наших меток значительно повышает производительность во всех задачах. Это говорит о том, что улучшения визуального энкодера принесут пользу. Кроме того, параметры, эффективная, точная настройка LLM последовательно улучшала производительность.
Наша работа открывает будущую работу в тактильной робототехнике. В настоящее время мы работаем над улучшением тактильного энкодера и более разнообразных исследовательских процедурах для получения дополнительных физических свойств. Было бы также интересно объединить различные наборы данных (например, те, которые используют другие тактильные датчики [44, 45]), наряду с другими методами, такими как проприоцепция робота. Мы планируем также выполнить физическое понимание выравнивания с изображениями объектов и точной настройки LLM с дополнительными физическими данными [52, 31].
Благодарности
Это исследование поддерживается Национальным исследовательским фондом, Сингапуром, под своим средним центром развитых робототехнических технологических инноваций.
Ссылки
[1] Жан-Батист Алайрак, Джефф Донахью, Полин Люк, Антуан Мич, Иэн Барр, Яна Хассон, Карел Ленк, Артур Менш, Кэтрин Милликан, Малкольм Рейнольдс и др. Flamingo: модель визуального языка для нескольких выстрелов. Достижения в системах обработки нейронной информации, 35: 23716–23736, 2022.
[2] Стефан Арока-Уэллет, Кори Пайк, Алессандро Рон-Кон и Катарина Канн. Прост: Физическое рассуждение объектов через пространство и время. Arxiv Preprint arxiv: 2106.03634, 2021. URL https://arxiv.org/pdf/2106. 03634.pdf.
[3] Джинзе Бай, Шуай Бай, Шушенг Ян, Шидзи Ван, Синан Тан, Пенг Ван, Джунианг Лин, Чанг Чжоу и Цзинрен Чжоу. QWEN-VL: пограничная большая модель на языке зрения с универсальными способностями. Arxiv Preprint arxiv: 2308.12966, 2023. URL https://arxiv.org/pdf/2308.12966.pdf.
[4] Антон Бахтин, Лоренс ван дер Маатен, Джастин Джонсон, Лора Густафсон и Росс Гиршик. Phyre: новый эталон для физических рассуждений. 2019. URL https: //arxiv.org/pdf/1908.05656.pdf.
[5] Вутер М. Бергманн. Тактуальное восприятие материалов. Vision Research, 50 (24): 2775–2782, 2010. ISSN 0042-6989. doi: https://doi.org/10.1016/j. Visres.2010.10.005. URL https://www.sciendirect.com/ science/article/pii/s0042698910004967. Восприятие и действие: часть I.
[6] Йонатан Биск, Роуэн Зеллерс, Цзянфенг Гао, Йецзин Чой и др. Пика: Рассуждение о физическом здравом смысле на естественном языке. В материалах конференции AAAI по искусственному интеллекту, том 34, страницы 7432–7439, 2020. URL https://arxiv.org/pdf/1911.11641.pdf.
[7] Энтони Брохан, Ноа Браун, судья Карбаджал, Евген Чеботар, Си Чен, Криштоф Чоромнски, Тянли Дин, Дэнни Дрисс, Авинава Дубей, Челси Финн и др. RT-2: модели с языком зрительного языка передают веб-знания на роботизированное управление. ARXIV PREPRINT ARXIV: 2307.15818, 2023. URL https://arxiv.org/pdf/2307.15818.pdf.
[8] Гуанкун Цао, Цзяки Цзян, Данушка Боллегала и Шан Луо. Учитесь на неполных тактильных данных: обучение тактильному представлению с помощью маскированных автоэнкодеров. В 2023 году Международная конференция IEEE/RSJ по интеллектуальным роботам и системам (IRO), стр. 10800–10805. IEEE, 2023. URL https://arxiv.org/pdf/2307.07358.pdf.
[9] Джун Чен, Деяо Чжу, Сяоциан Шен, Сян Ли, Зачун Лю, Пенгчуань Чжан, Рагураман Кришнамурти, Викас Чандра, Юньян Синь и Мохамед Элхосейин. Minigpt-V2: Большая языковая модель как унифицированный интерфейс для многозадачного обучения на языке зрения. ARXIV PREPRINT ARXIV: 2310.09478, 2023. URL https://arxiv.org/ pdf/2310.09478.pdf.
[10] X. Чен, Фей Шао, Кэти Барнс, Том Чайлдс и Брайан Хенсон. Изучение отношений между восприятием прикосновения и поверхностными физическими свойствами. Международный журнал дизайна, 3: 67–76, 08 2009. URL https://arxiv.org/pdf/1704.03822.pdf.
[11] Вей-лин Чианг, Чжуохан Ли, Зи Лин, Ин Шенг, Чжангао Ву, Хао Чжан, Лянмин Чжэн, Сиюан Чжуан, Йонгао Чжуан, Джозеф Э. Гонсалес, Ион Стоика и Эрик П. Xing. Vicuna: чат-бот с открытым исходным кодом, впечатляющий GPT-4 с 90%* Качество CHATGPT, март 2023 года. URL https://lmsys.org/blog/2023-03-30-vicuna/.
[12] Jiafei Duan, Samson Yu и Cheston Tan. Пространство: симулятор для физических взаимодействий и причинно -следственного обучения в 3D -средах. В материалах Международной конференции IEEE/CVF по компьютерному видению, страницы 2058–2063, 2021.
[13] Jiafei Duan, Samson Yu, Soujanya Poria, Bihan Wen и Cheston Tan. PIP: Прогноз физического взаимодействия посредством умственного моделирования с выбором пролета. На европейской конференции по компьютерному видению, страницы 405–421. Springer, 2022. URL http://phys101.csail.mit.edu/papers/ phys101 bmvc.pdf.
[14] Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu и Cheston Tan. Обзор воплощенного ИИ: от симуляторов до исследовательских задач. IEEE транзакции по новым темам в вычислительном интеллекте, 6 (2): 230–244, 2022.
[15] Jiafei Duan, Yi Ru Wang, Mohit Shridhar, Dieter Fox и Ranjay Krishna. AR2-D2: Обучение робота без робота. Arxiv Preprint arxiv: 2306.13818, 2023.
[16] Letian Fu, Gaurav Datta, Huang Huang, William Chungho Panitch, Jaimyn Drake, Joseph Ortiz, Мустафа Мукадам, Майк Ламбета, Роберто Каландра и Кен Голдберг. Набор данных Touch, Vision и языка для мультимодального выравнивания. Arxiv Preprint arxiv: 2402.13232, 2024.
[17] Дженсен Гао, Бидипта Саркар, Фей Ся, Тед Сяо, Цзяджун Ву, Брайан Ихтер, Анирудха Маджумдар и Дорса Сади. Физически обоснованные модели на языке зрения для роботизированных манипуляций. ARXIV PREPRINT ARXIV: 2309.02561, 2023. URL https://arxiv.org/pdf/2309.02561.pdf.
[18] Рухан Гао, Зилин С.И., Йен-Ю Чанг, Сэмюэль Кларк, Джанетт Бог, Ли Фей-Феи, Вэньчжэнь Юань и Цзяджун Ву. ObjectFolder 2.0: многосенсорный набор данных объекта для передачи SIM2Real. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию шаблонов, страницы 10598–10608, 2022. URL https://arxiv.org/pdf/ 2204.02389.pdf.
[19] Рухан Гао, Йиминг Доу, Хао Ли, Танмай Агарвал, Жаннетт Бог, Юнжу Ли, Ли Фей-Феи и Цзяджун Ву. ОБЪЕДИНЕННЫЙ БЕЗНАЧЕНИЕ: Многосенсорное обучение с нейронными и реальными объектами. В материалах конференции IEEE/CVF по компьютерному зрению и распознаванию шаблонов (CVPR), стр. 17276–17286, июнь 2023 года. URL https://arxiv.org/pdf/2306.00956.pdf.
[20] Ян Гао, Лиза Энн Хендрикс, Кэтрин Дж. Кученбекер и Тревор Даррелл. Глубокое обучение тактильному пониманию из визуальных и тактичных данных. В 2016 году IEEE Международная конференция по робототехнике и автоматизации (ICRA), страницы 536–543. IEEE, 2016. URL https: //arxiv.org/pdf/1511.06065.pdf.
[21] Дэн Хендриккс и Кевин Гимптель. Гауссовая ошибка линейные единицы (гелус). Arxiv Preprint arxiv: 1606.08415, 2016.
[22] Иин Хонг, Зишуо Чжэн, Пейхао Чен, Ян Ван, Джуньян Ли и Чуан Ган. Умножение: мультисенсорная объектно-ориентированная крупная модель языка в 3D. Arxiv Preprint arxiv: 2401.08577, 2024.
[23] Эдвард Дж. Ху, Йелонг Шен, Филипп Уоллис, Зейуан Алленжу, Юаньжи Ли, Шин Ванг, Лу Ван и Вейху Чен. LORA: Низкая адаптация крупных языковых моделей. Arxiv Preprint arxiv: 2106.09685, 2021. URL https://arxiv.org/pdf/2106.09685.pdf.
[24] Хун-Юй Хуанг, Сяофенг Го и Вэньчжэнь Юань. Понимание динамического тактильного зондирования для оценки свойства жидкости. ARXIV PREPRINT ARXIV: 2205.08771, 2022. URL https://arxiv.org/pdf/2205.08771.pdf.
[25] Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Persomie, Bharath Hariharan и Ser-Nam Lim. Визуальная приглашенная настройка. В Европейской конференции по компьютерному видению, страницы 709–727. Springer, 2022.
[26] Цзяки Цзян и Шан Луо. Роботизированное восприятие свойств объекта с использованием тактильного зондирования. В тактильном зондировании, обучении навыкам и роботизированной ловкой манипуляции, страницы 23–44. Elsevier, 2022.
[27] Роберта Клацки и Кэтрин Л Рид. Хаптическое исследование. Scholaredia of Touch, страницы 177–183, 2016.
[28] Марк Х. Ли. Тактильное зондирование: новые направления, новые проблемы. Международный журнал исследований робототехники, 19 (7): 636–643, 2000. DOI: 10.1177/027836490001900702. URL https://doi.org/10.1177/ 027836490001900702.
[29] Junnan Li, Dongxu Li, Silvio Savarese и Steven Hoi. BLIP-2: предварительное обучение на основе лечения языка с замороженными кодерами изображения и большими языковыми моделями. Arxiv Preprint arxiv: 2301.12597, 2023. URL https: //dl.acm. org/doi/10.5555/3618408.3619222.
[30] Кунчан Ли, Инан Х. Х., И Ванг, Ихуо Ли, Венхай Ван, Пинг Луо, Яли Ван, Лимин Ван и Ю Цяо. Видеочат: понимание видео, ориентированное на чат. Arxiv Preprint arxiv: 2305.06355, 2023. URL https: //arxiv.org/pdf/2305.06355.pdf.
[31] Лей Ли, Цзинцзин Сюй, Цинсиу Донг, Се Чжэн, Сюй Сан, Лингпенг Конг и Ци Лю. Могут ли языковые модели понять физические концепции? В Houda Bouamor, Juan Pino и Kalika Bali, редакторы, Материалы конференции 2023 года по эмпирическим методам в обработке естественного языка, страницы 11843–11861, Сингапур, декабрь 2023 г. Ассоциация по вычислительной лингвистике. doi: 10.18653/v1/2023.emnlp-main.726. URL https://aclanthology.org/2023.emnlp-main.726.
[32] Руи Ли и Эдвард Х. Адельсон. Ощущение и распознавание поверхностных текстур с использованием датчика Gelsight. В 2013 году IEEE Conference по компьютерному зрению и распознаванию шаблонов, страницы 1241–1247, 2013. DOI: 10.1109/CVPR.2013.164.
[33] Хаотиан Лю, Чунюань Ли, Юхенг Ли и Юн Чже Ли. Улучшенные базовые показатели с настройкой визуальной инструкции. Arxiv Preprint arxiv: 2310.03744, 2023.
[34] Хаотиан Лю, Чунюань Ли, Циньян Ву и Юн Чже Ли. Настройка визуальной инструкции. Arxiv Preprint arxiv: 2304.08485, 2023. URL https://arxiv.org/pdf/2304. 08485.pdf.
[35] Илья Лошчилов и Фрэнк Хаттер. Разрешенная регуляризация распада веса. Arxiv Preprint arxiv: 1711.05101, 2017.
[36] Мухаммед Мааз, Хануна Рашид, Салман Хан и Фахад Шахбаз Хан. Видео-чатгпт: к детальному пониманию видео с помощью большого видения и языковых моделей. ARXIV PREPRINT ARXIV: 2306.05424, 2023. URL https://arxiv.org/pdf/2306.05424.pdf.
[37] Эндрю Мельник, Робин Шукер, Мориц Ланге, Андрей Мюресану, Можган Саиди, Анишэш Гарг и Хельдж Риттер. Тесты для физических рассуждений ИИ. Arxiv Preprint arxiv: 2312.10728, 2023. URL https://arxiv.org/ pdf/2312.10728.pdf.
[38] Мэтью Пурри и Кристин Дана. Обучение камер для ощущения: оценка тактильных физических свойств поверхностей из изображений. В Computer Vision - ECCV 2020: 16 -я Европейская конференция, Глазго, Великобритания, 23–28 августа 2020 года, Труды, часть XXVII 16, страницы 1–20. Springer, 2020. URL https://arxiv.org/pdf/2004.14487.pdf.
[39] Алек Рэдфорд, Чон Вук Ким, Крис Халласи, Адитья Рамеш, Габриэль Го, Сандхини Агарвал, Гириш Састри, Аманда Аскалл, Памела Мишкин, Джек Кларк и др. Обучение переносимым визуальным моделям от надзора естественного языка. На Международной конференции по машинному обучению, страницы 8748–8763. PMLR, 2021. URL https://arxiv.org/pdf/2103.00020.pdf.
[40] Хануна Рашид, Мухаммед Узайр Хаттак, Мухаммед Мааз, Салман Хан и Фахад Шахбаз Хан. Тонко настроенные модели клипов-эффективные видеобазвители. В материалах конференции IEEE/CVF по компьютерному видению и распознаванию шаблонов, страницы 6545–6554, 2023.
[41] Маки Сакамото и Джунджи Ватанабе. Изучение тактильных измерений восприятия с использованием материалов, связанных с сенсорным словарным запасом. Границы в психологии, 8, 2017. URL https://api.semanticscholar.org/corpusid: 14038261.
[42] Мехмет Сэйгин Сейфиоглу, Мудрость Оикзогво, Фатмех Гезлу, Ранджай Кришна и Линда Шапиро. Quiltllava: настройка визуальной инструкции путем извлечения локализованных повествований из гистопатологических видеороликов с открытым исходным кодом. arxiv e-prints, pages arxiv-2312, 2023. url https://arxiv.org/pdf/2312.04746.pdf.
[43] Куниюки Такахаши и Джетро Тан. Глубокое визуальное обучение: оценка тактильных свойств из изображений. В 2019 году Международная конференция по робототехнике и автоматизации (ICRA), страницы 8951–8957. IEEE, 2019. URL https://arxiv.org/pdf/1803.03435.pdf.
[44] Тасболат Тауньязов, Вейконг Снг, Хиан Хиан Сит, Брайан Лим, Джетро Куан, Абдул Фатитар Ансари, Бенджамин К.К. и Гарольд Со. Визуальное ощущение и обучение, управляемое событиями для роботов. ARXIV PREPRINT ARXIV: 2009.07083, 2020. URL https://arxiv.org/pdf/2009.07083.pdf.
[45] Тасболат Тауньязов, Луар Шуй Сонг, Юджин Лим, Хиан Хиан Сит, Дэвид Ли, Бенджамин К.К. Ти и Гарольд Со. Расширенное тактильное восприятие: вибрационное определение с помощью инструментов и схваченных объектов. В 2021 году Международная конференция IEEE/RSJ по интеллектуальным роботам и системам (IRO), страницы 1755–1762. IEEE, 2021.
[46] Команда Близнецов, Рохан Анил, Себастьян Борги, Йонхуи Ву, Жан-Батист Алайрак, Цзяхуи Ю, Раду Сорикут, Йохан Шалкик, Эндрю М. Дай, Анджа Хаут и др. Близнецы: семейство очень способных мультимодальных моделей. Arxiv Preprint arxiv: 2312.11805, 2023. URL https: //arxiv.org/pdf/2312.11805.pdf.
[47] Йохан Тегин и Ян Викандер. Тактильное восприятие в интеллектуальных роботизированных манипуляциях - обзор. Промышленный робот: Международный журнал, 32, 02 2005. DOI: 10.1108/01439910510573318.
[48] Стивен Тянь, Фредерик Эберт, Динеш Джаяраман, Маюр Мудюгонда, Челси Финн, Роберто Каландра и Сергей Левин. Манипуляция по ощущению: сенсорный контроль с глубокими прогнозирующими моделями. В 2019 году Международная конференция по робототехнике и автоматизации (ICRA), страницы 818–824. IEEE, 2019. URL https://arxiv.org/pdf/1903.04128. PDF.
[49] Хьюго Туврон, Тибо Лаврил, Гаутье Изакард, Ксавье Мартинет, Мари-Энн Лахау, Тимофеи Лакруа, Бап-Тист Розье, Наман Гоял, Эрик Хамбро, Фейсал Азар, `et al. Llama: открытые и эффективные модели языка фундамента. Arxiv Preprint arxiv: 2302.13971, 2023.
[50] Хьюго Туврон, Луи Мартин, Кевин Стоун, Питер Альберт, Амджад Альмахайри, Ясмин Бабей, Николай Башликов, Суйя Батра, Праджвал Бхаргава, Шрайли Бхосале и др. Llama 2: Open Foundation и тонкие модели чата. ARXIV PREPRINT ARXIV: 2307.09288, 2023. URL https: //arxiv.org/pdf/2307.09288.pdf.
[51] Ашиш Васвани, Ноам Шейзер, Ники Пармар, Якоб Ускорет, Ллион Джонс, Эйдан Н Гомес, Лукаш Кайзер и Илья Полосухин. Внимание - это все, что вам нужно. Достижения в области систем обработки нейронной информации, 30, 2017.
[52] Йи Ру Ванг, Цзяфей Дуан, Дитер Фокс и Сиддхартха Шриниваса. Ньютон: Модели больших языков способны к физическим рассуждениям?
[53] Хаоран Вэй, Линью Конг, Цзиньей Чен, Лян Чжао, Чжэн Г.Е., Джинрон Ян, Цзяньцзян Солн, Чунруи Хан и Сяньгу Чжан. Избавиться: масштабирование словарного запаса для больших моделей языка зрений. Arxiv Preprint arxiv: 2312.06109, 2023. URL https://arxiv.org/pdf/2312. 06109.pdf.
[54] Jiajun Wu, Joseph J Lim, Hongyi Zhang, Joshua B Tenenbaum и William T Freeman. Физика 101: изучение свойств физических объектов из немеченых видео. В BMVC, том 2, стр. 7, 2016. URL http://phys101.csail.mit.edu/papers/phys101 bmvc.pdf.
[55] Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji и Tatseng Chua. Next-GPT: Any-To-MultiModal LLM. Arxiv Preprint arxiv: 2309.05519, 2023. URL https://arxiv.org/ pdf/2309.05519.pdf.
[56] Фенгю Ян, Ченьян М.А., Цзячэн Чжан, Цзин Чжу, Венчжэнь Юань и Эндрю Оуэнс. Прикоснитесь и уходите: учиться на собрании человека и прикосновения. Arxiv Preprint arxiv: 2211.12498, 2022. URL https://arxiv.org/ pdf/2211.12498.pdf.
[57] Фенгю Ян, Чао Фэн, Зиян Чен, Хьяунсеб -Парк, Даниэль Ван, Йиминг Ду, Зияо Зенг, Син Чен, Рит Гангопадхьяй, Эндрю Оуэнс и др. Привязывающий прикосновение ко всему: изучение единых мультимодальных тактильных представлений. Arxiv Preprint arxiv: 2401.18084, 2024.
[58] Кексин Йи, Чуан Ган, Юнжу Ли, Пушмет Кохли, Цзяджун Ву, Антонио Торралба и Джошуа Б Тененбаум. CLEVRER: События столкновения для представления видео и рассуждений. ARXIV PREPRINT ARXIV: 1910.01442, 2019. URL https://arxiv.org/pdf/1910.01442.pdf.
[59] Вэньчжэнь Юань, Мандейм А. Сринивасан и Эдвард Х. Адельсон. Оценка твердости объекта с помощью датчика Gelsight Touch. В 2016 году IEEE/RSJ Международная конференция по интеллектуальным роботам и системам (IRO), страницы 208–215, 2016. DOI: 10.1109/iros.2016.7759057.
[60] Вэньчжэнь Юань, Сиюань Донг и Эдвард Х. Адельсон. Gelsight: тактильные датчики робота с высоким разрешением для оценки геометрии и силы. Датчики, 17 (12), 2017. ISSN 1424-8220. doi: 10.3390/s17122762. URL https://www.mdpi.com/1424-8220/17/12/2762.
[61] Вэньчжэнь Юань, Ючен Мо, Шаоксонг Ван и Эдвард Х. Адельсон. Активное восприятие материала одежды с использованием тактильного зондирования и глубокого обучения. В 2018 году IEEE Международная конференция по робототехнике и автоматизации (ICRA), страницы 4842–4849. IEEE, 2018. URL https: //arxiv.org/pdf/1711.00574.pdf.
[62] Бен Зандонати, Руохан Ван, Рухан Гао и Ян Ву. Исследование основополагающих моделей зрения для обучения тактильному представлению. Arxiv Preprint arxiv: 2305.00596, 2023. URL https://arxiv.org/pdf/2305. 00596.pdf.
[63] Ханг Чжан, Синь Ли и Лидонг Бинг. Видео-Лама: модель аудиовизуального языка, настроенная на подготовку к инструкции для понимания видео. Arxiv Preprint arxiv: 2306.02858, 2023.
[64] Йиюан Чжан, Кайсион Гонг, Кайпенг Чжан, Хоншенг Ли, Ю Цяо, Ванли Уянг и Сяньгу Юэ. Мета-трансформатор: унифицированная структура для мультимодального обучения. ARXIV PREPRINT ARXIV: 2307.10802, 2023. URL https://arxiv.org/pdf/2307.10802.pdf.
[65] Ченген Чжу, Фаньи Сяо, Андрес Альварадо, Яс-шахт Бабей, Цзябо Ху, Хихем Эль-Мохри, Шон Чанг, Рошан Сумбали и Чжичэн Ян. EgoObjects: крупномасштабный эгоцентрический набор данных для мелкозернистого понимания объекта. В материалах Международной конференции IEEE/CVF по компьютерному видению (ICCV), 2023.
[66] Йисин Чжу, Тао Гао, фанат Lifeng, Siyuan Huang, Mark Edmonds, Hangxin Liu, Feng Gao, Chi Zhang, Siyuan Qi, Ying Nian Wu, et al. Темный, за пределами глубокой: парадигма переход к когнитивному ИИ с человеческим здравым смыслом. Инжиниринг, 6 (3): 310–345, 2020.
Приложение для осьминоги: рассуждения о свойстве объекта с большими моделями тактильно-языка
В приведенных ниже приложениях мы предоставляем более подробную информацию для нашего физического набора данных, особенно для аннотаций, объектов, свойств, образцов видео и подсказок. Мы также предоставляем подробную информацию об экспериментах с осьминогами и авокадо.
Приложение A: сведения об аннотации
Мы разработали общий набор руководящих принципов для выравнивания аннотаций для свойств и уменьшения дисперсии. Мы показываем рекомендации в таблице A1. В то время как свойства твердости и шероховатости обычно аннотируются с фактической тактильной обратной связью из исследовательских процедур человека, свойство неровности обычно визуально аннотируется из тактильных изображений гельза.
![TABLE A1. PHYSICLEAR Property Category Annotation Guidelines. For each property and its three categories, we detail the general guideline we used to choose the most appropriate category for a tactile sample. The annotator rating for each property and its categories are given as [X] where X is the rating.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-l2831lg.png)
![TABLE A2. PHYSICLEAR Annotation Ratings. We show the annotation ratings for each property and its three categories for all objects. The ratings are given as [X, Y, Z] where X is the rating by annotator 1, Y by annotator 2 and Z by annotator 3. The mapping between the ratings and the property categories can be found in Table A1.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-o4a310w.png)
![TABLE A2. PHYSICLEAR Annotation Ratings. We show the annotation ratings for each property and its three categories for all objects. The ratings are given as [X, Y, Z] where X is the rating by annotator 1, Y by annotator 2 and Z by annotator 3. The mapping between the ratings and the property categories can be found in Table A1.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-68b314i.png)
Приложение B: сведения о объекте
В таблицах A3 и A4 мы предоставляем список объектов в физиклеарке, связанном с ним имени видео и наборе (т.е. Train/Val/Test). Мы используем имена объектов в левом столбце во время задачи соответствия объекта объекта.

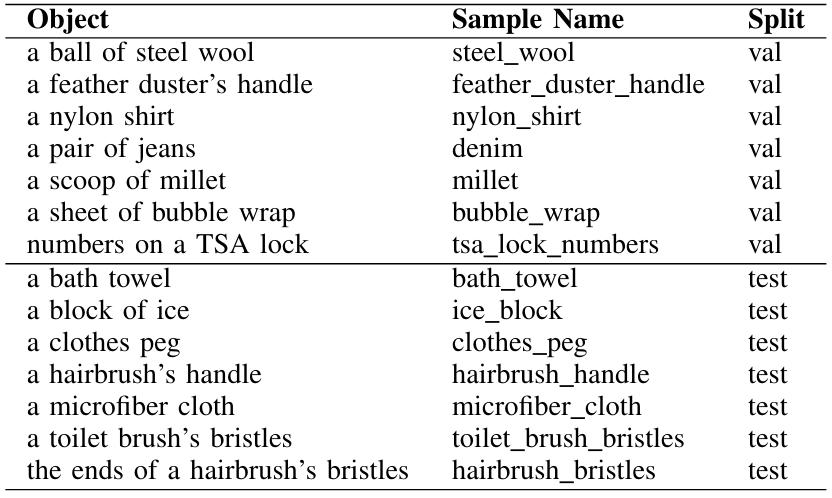
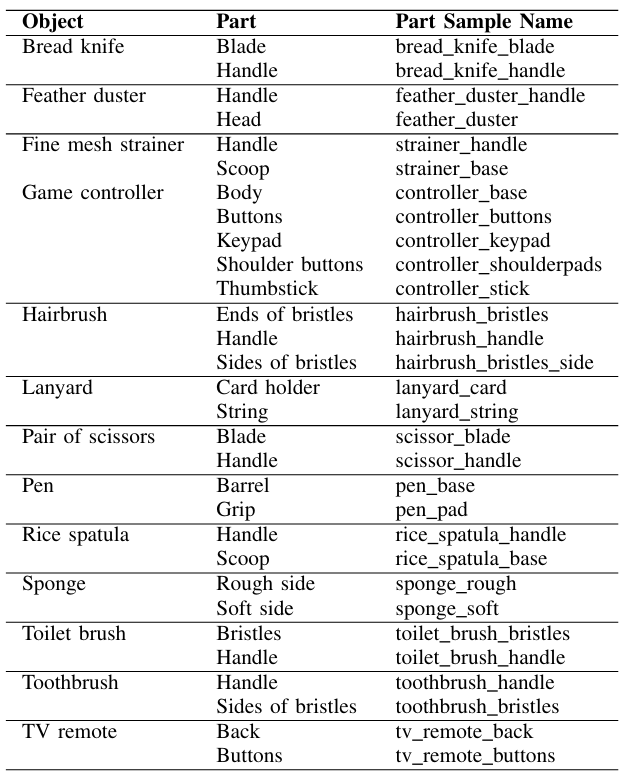
В таблице A5 мы перечисляем объекты, которые имеют семантически значимые части для задач физических рассуждений, основанных на части. В частности, мы отмечаем, что их семантические части можно использовать для более точного соответствия объекта объекта. Поверхностные материалы физикиарных объектов перечислены в таблице A6. Physiclear содержит девять различных общих материалов: ткань, продукты питания, кожа, металл, бумага, пластика, резина, силикон и дерево. Несмотря на то, что мы не используем эти материалы для каких -либо задач в настоящее время, мы каталогизируем их для будущих расширений (например, классификация материалов с использованием свойств).

Приложение C: Статистика недвижимости
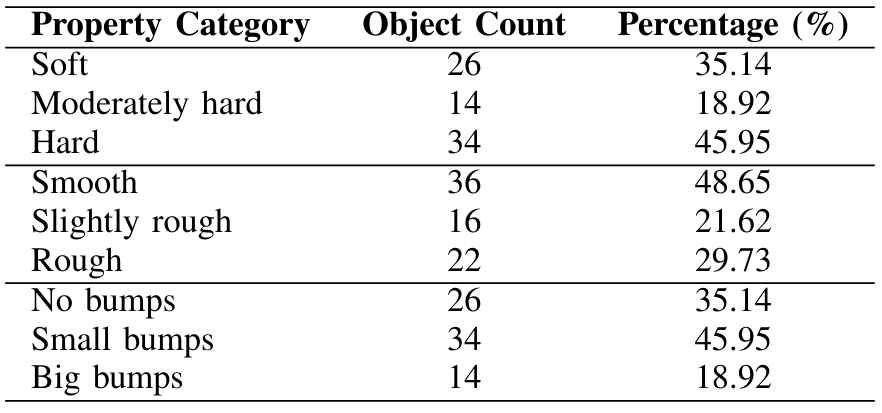
Мы показываем количество объектов и процент каждой категории свойств в таблице A7. Для каждого свойства составляет не менее 18,92% каждой категории, так что набор данных достаточно сбалансирован.
В таблице A8 показаны подсчет каждой комбинации трех свойств: твердость, шероховатость и неровность. Совместное распределение этих свойств по повседневным объектам не является равномерным. Некоторые комбинации встречаются гораздо чаще (например, [жесткие, гладкие, без ударов] для человеческих объектов), чем другие (например, [мягкие, грубые, без ударов]). Кроме того, проклятие размерности означает, что трудно представить все комбинации, поскольку количество свойств увеличивается. Наша будущая работа будет включать в себя лучшие методы обучения для представления для справки с этим дисбалансом.

Приложение D: образец статистики видео
Существует от пяти до семи тактильных видео для каждого объекта в физиклеар. В таблице A9 показано среднее, минимальное и максимальное количество кадров в наших тактильных видеороликах в 112,30, 50 и 126 соответственно.

А. Детали на языке
Мы перечисляем вопросы для каждой задачи в этом разделе.

![]()
Приложение E: Анализ энкодера
На рис. 6 визуализирует матрицы путаницы для прогнозов классификатора зажима, и рис. 7 показывает выходные встроения визуального энкодера для всех невидимых объектов (размерностно-уменьшенная). Мы наблюдаем, что классификатор клипа хорошо работает на жестких объектах, но не так же хорошо на мягких и умеренно жестких объектах. Это также очевидно в встраивании энкодера в самой левой части рис. 7, где встроения для жестких объектов хорошо разделились, в то время как те, которые умеренно жесткие объекты особенно не имеют хорошего отделения. Для свойства шероховатости классификатор клипа хорошо работает на гладких и слегка грубых объектах, но не так же хорошо на грубых объектах. Мы можем увидеть это в кодере

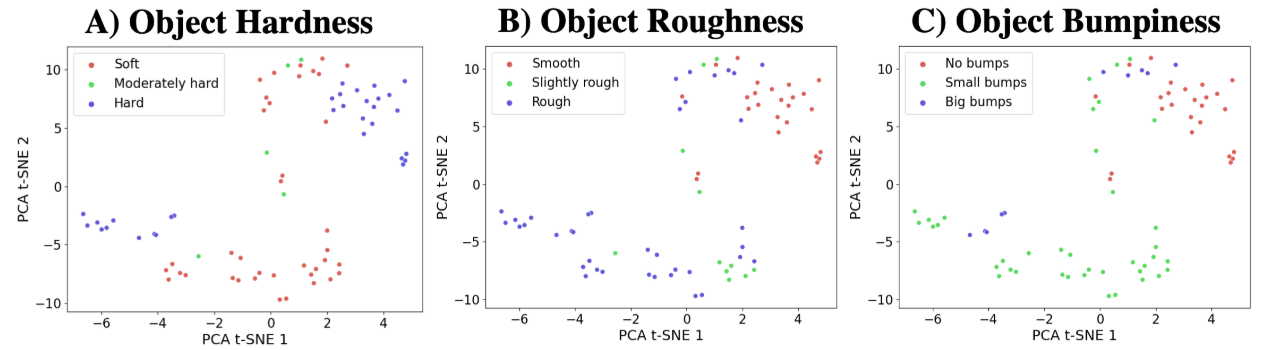
Встраиваемые на рис. 7, где некоторые из встраиваний для грубых объектов впрыскивают с встроениями для гладких объектов. Наконец, для свойства неровности, клип способен различать не удары и небольшие удары, но не так же хорошо на объектах с большими ударами. В встраивании энкодера в правой стороне рис.
Приложение F: PG-Instructblip Avocado Прогнозирование имущества.
Для экспериментов с авокадо с PG-InstructBlip мы снимаем 20 изображений RGB каждого авокадо из сверху вниз на плоской серой поверхности. Мы различаем положение и ориентацию каждого авокадо для каждого изображения и используем обрезанные изображения (пример, показанный на рис. 8); Обрезка изображений авокадо делает его ближе к набору данных PG-InstructBlip. Мы используем исходную подсказку, представленную в примере PG-InstructBlip, и приглашаем модель для каждого физического свойства:
• Твердость - «классифицировать объект как жесткий, мягкий или средний? Ответьте неизвестно, если вы не уверены. Короткий ответ:»
• Шероховатость - «классифицировать объект как грубый, гладкий или средний? Ответьте неизвестно, если вы не уверены. Короткий ответ:»
• Неубирство - «классифицировать объект как иметь большие удары, небольшие удары или нет ударов? Ответьте неизвестно, если вы не уверены. Короткий ответ:»

PG-InstructBlip не обучается на наших трех физических свойствах, и мы обнаруживаем, что он никогда не выбирает «умеренно жесткие» и «немного грубые». Следовательно, мы меняем эти категории на «средний» для твердости и шероховатости.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)