

Почему правильные основы ИИ каждый раз превосходят необработанные размеры
15 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 терминология
3 Изучение пространства дизайна моделей на языке зрения и 3.1. Все ли предварительно обученные основы эквивалентны VLMS?
3.2 Как полностью ауторегрессивная архитектура сравнивается с архитектурой перекрестного активации?
3.3 Где повышение эффективности?
3.4 Как можно вычислить торговлю на производительность?
4 IDEFICS2-открытая современная модель Фонда зрения и 4.1 многоэтапное предварительное обучение
4.2 Инструкция тонкая настройка и 4.3 оптимизация для сценариев чата
5 Заключение, подтверждение и ссылки
Приложение
A.1 Дальнейшие экспериментальные детали абляций
A.2 Детали инструкции тонкая настройка
A.3 Детали оценок
A.4 Красная команда
2 терминология
Сначала мы создаем общую терминологию для обсуждения различных вариантов дизайна. Обучение VLM, как правило, требует склеивания предварительно обученной основы зрения и предварительно обученного языковой основы путем инициализации новых параметров для подключения двух методов. Обучение этих новых параметров выполняется на этапе предварительного обучения. На этом этапе обычно используется большой мультимодальный набор данных, такой как пары изображений. Мы отмечаем, что, несмотря на то, что наиболее распространено с двух отдельных унимодальных предварительно обученных магистралей, параметры этих двух магистралей могут быть необязательно обмены и инициализированы с нуля, как это сделано (Bavishi et al., 2023). Как и в литературе с большими языковыми моделями, за этапом предварительного обучения следует стадия тонкой настройки инструкции, на которой модель учится из образцов, ориентированных на задачу.
Недавние работы исследуют два основных варианта для объединения визуальных вводов и текстовых вводов. В архитектуре перекрестного активации (Alayrac et al., 2022; Laurençon et al., 2023; Awadalla et al., 2023), изображения, кодируемые через основу зрения, вводится в различных слоях в языковой модели путем интерлизации блоков привязанности к скрещиванию, в которых текст перекрестно витает в изображения Hidden States. Напротив, в полностью авторегрессивной архитектуре (Koh et al., 2023; Driess et al., 2023; Liu et al., 2023), выход кодера зрения непосредственно объединяется с последовательности текстовых внедрений, а вся последовательность передается в качестве входной модели языка. Таким образом, входная последовательность языковой модели является объединением визуальных токенов и текстовых токенов. Последовательность визуальных токенов может быть необязательно объединена в более короткую последовательность, обеспечивая большую вычислительную эффективность. Мы называем слои, которые отображают видение, скрытое пространство, с скрытым пространством, как проекционные слои модальности. Рисунок 2 подчеркивает полностью авторегрессивную архитектуру, которую мы в конечном итоге используем для IDEFICS2.
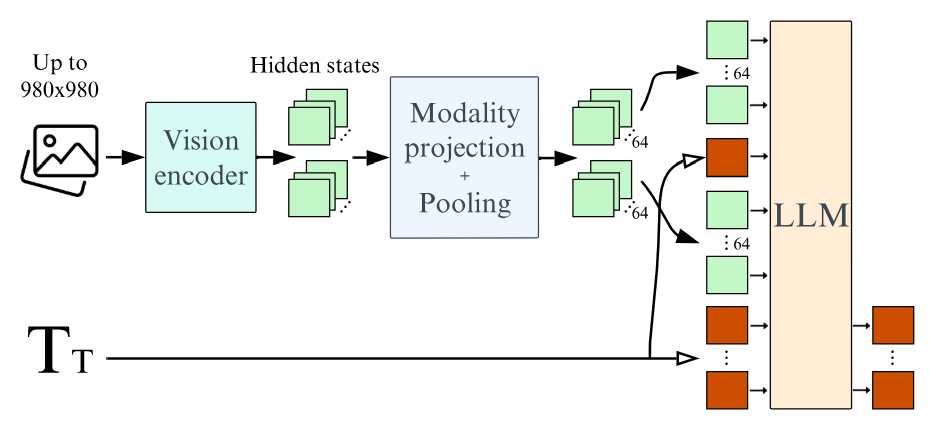
3 Изучение дизайнерского пространства моделей на языке зрения
В этом разделе мы сравниваем рецидивирующий выбор дизайна в литературе по модели на языке зрения и выявляются результаты. Если не указано иное, мы выполняем абляции для 6 000 шагов и сообщаем об среднем балле 4-х сбыточных показателей по 4 нисходящим критериям, измеряющим различные возможности: VQAV2 (Goyal et al., 2017) для общего визуального ответа на вопросы, TextVQA (Singh et al., 2019) для OCR, okVQA (Marino et al., 2019) для Emdence Scalite, Et. et al. подпись.
3.1. Все ли предварительно обученные магистрали эквивалентны для VLMS?
Самые последние VLMs начинаются с предварительно обученных унимодальных магистралей. Как выбор магистралей (видение и текст) влияет на производительность полученного VLM?

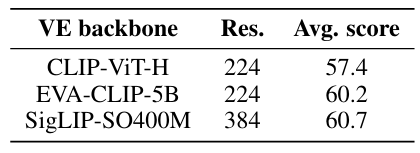
Мы фиксируем размер предварительно проведенных костей, данные, используемые для мультимодальной предварительной тренировки, и количество обучающих обновлений. В рамках архитектуры по перекрестному активации мы наблюдаем, что наибольшее улучшение в показателях показателя на языке зрения, связано с изменением языковой модели на лучшую. Более конкретно, замена Llama-1-7B (Touvron et al., 2023) (35,1% на MMLU (Hendrycks et al., 2021))) на Mistral-7B (Jiang et al., 2023) (60,1% на MMLU) дает повышение 5.1 (см. Таблицу 1). Кроме того, переключение энкодера зрения с Clip-Vit-H (Radford et al., 2021) (78,0% на ImageNet (Deng et al., 2009)) на Siglip-So400m (Zhai et al., 2023) (83,2% на ImageNet), приводит к повышению производительности на уровне (см. Таблицу 2). Этот результат на лучших основаниях зрения подтверждает наблюдения (Karamcheti et al., 2024).
Мы отмечаем, что Чен и Ван (2022) сообщают о более сильном увеличении производительности, масштабируя размер энкодера зрения по сравнению с масштабированием размера языковой модели, даже если масштабирование энкодера зрения приводит к меньшему увеличению количества параметров. Хотя EVA-Clip-5B (Sun et al., 2023) в десять раз больше по количеству параметров, чем Siglip-So400M (Zhai et al., 2023), мы получаем аналогичные результаты в 4 тестах, предполагая, что EVA-Clip-5B может быть в значительной степени недостаточно обучен, и мы признаем, что в сообществе открытых VLM не хватает широкого приюта.
Авторы:
(1) Хьюго Лоренсон, обнимающееся лицо и Sorbonne Université, (порядок был выбран случайным образом);
(2) Léo Tronchon, обнимающее лицо (порядок был выбран случайным образом);
(3) шнур Matthieu, Sorbonne Université;
(4) Виктор Сан, обнимающееся лицо.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)