
Почему новые наборы данных необходимы для IR с глубоким обучением
29 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 предыстория и связанная с ним работа
2.1 Поиск информации в Интернете
2.2 Существующие наборы данных
3 MS MS MARCO WEBEATET и 3.1 Подготовка документов
3.2 Выбор запроса и маркировка
3.3 Анализ наборов данных
3.4 Новые проблемы, поднятые MS Marco Web Search
4 базовые результаты и настройка среды 4.1
4.2 Базовые методы
4.3 Метрики оценки
4.4 Оценка моделей встраивания и 4.5 Оценка алгоритмов ANN
4.6 Оценка сквозной производительности
5 Потенциальные предубеждения и ограничения
6 Будущая работа и выводы, а также ссылки
2.2 Существующие наборы данных
Чтобы поощрять инновации в области поиска информации, сообщество собрало несколько наборов данных для публичного сравнительного анализа (обобщено в таблице 1).
Существует много общедоступных веб -данных для традиционных задач поиска информации, таких как robust04 [3], clueWeb09 [13], clueWeb12 [9], Gov2 [12], ClueWeb22 [37] и Common Crawl [2]. К сожалению, эти наборы данных имеют, в большинстве случаев, сотни маркированных запросов, далеко не достаточно, чтобы узнать хорошую модель глубокого обучения, улучшенного поиска.
Недавно было опубликовано несколько новых наборов данных для исследований по улучшению поиска глубокого обучения [28, 35, 43]. MS Marco [35] является одним из самых популярных наборов данных для внедрения модели. Он содержит 100 тыс. Вопросов, собранных по вопросам поиска Bing в сочетании с человеческими ответами, контекстуализированными в веб -документах. MS Marco Ranking V2 [47] расширяет размер документа, а набор вопросов - до 11 миллионов и 1 миллион соответственно. Orcas [14] предоставляет 10 миллионов уникальных запросов и 18
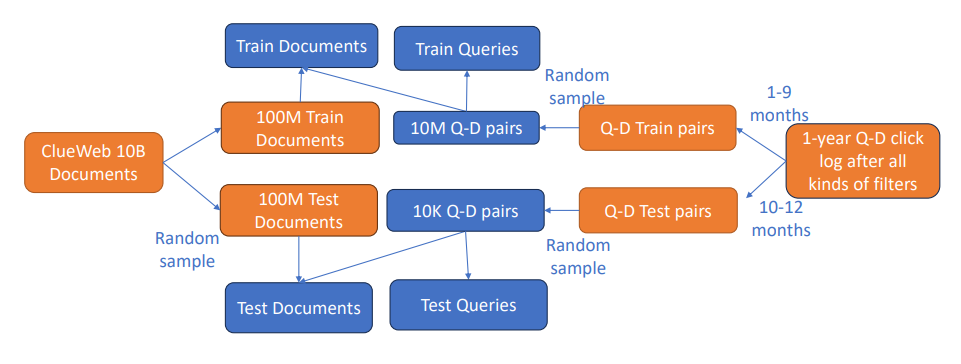
Миллион щелкнул пары запросов-документов для документов MS Marco. Естественные вопросы [28], набор данных для ответа на вопрос, собранной в шкале, собранные в поисковых запросах Google с аннотированными человеческими ответами в статьях Википедии, был перепрофилен для встраивания на основе поиска путем извлечения отрывков из Википедии в качестве ответов кандидата [27]. CLIR [43], набор данных по поиску информации о межязыке в миллион масштабов, собранного в Википедии, использовался для обучения моделей межъязычного встраивания [55]. Тем не менее, ни один из этих наборов данных соответствует появлению крупных, реальных и богатых требований. Эти наборы данных сосредоточены на задачах ответа на вопрос только на английском языке. Ни у кого из них нет желаемых данных в Интернете с высокоязычными многоязычными запросами, которые могут быть короткими, неоднозначными и часто не сформулированными в виде вопросов естественного языка. Кроме того, они предоставляют только необработанный текст запросов и ответов, который ограничивает потенциал будущих межмодальных исследований передачи знаний. Наконец, они сосредоточены только на оценке качества моделей встраивания с использованием поиска грубой силы, который не может отражать сквозные проблемы поиска.
Энн Benchmark [4] и в миллиардном эталонном этаже [1] предоставляют несколько высокоразмерных векторных наборов векторных данных для оценки точности результата и производительности системы для алгоритмов поиска на основе внедрения. К сожалению, они не могут измерить качество модели и, следовательно, не могут отражать сквозную производительность поиска.
Таким образом, крупномасштабный веб-данные, богатый информацией, с реальными документами и распределением запросов, который может отражать реальные проблемы, все еще отсутствует.
Авторы:
(1) Ци Чен, Microsoft Пекин, Китай;
(2) Xiubo Geng, Microsoft Пекин, Китай;
(3) Корби Россет, Microsoft, Редмонд, США;
(4) Кэролин Бурактаон, Microsoft, Редмонд, США;
(5) Jingwen Lu, Microsoft, Redmond, США;
(6) Тао Шен, Технологический университет Сидней, Сидней, Австралия, и работа была выполнена в Microsoft;
(7) Кун Чжоу, Microsoft, Пекин, Китай;
(8) Чеменский Сюн, Университет Карнеги -Меллона, Питтсбург, США, и работа была выполнена в Microsoft;
(9) Yeyun Gong, Microsoft, Пекин, Китай;
(10) Пол Беннетт, Spotify, Нью -Йорк, США, и работа была выполнена в Microsoft;
(11) Ник Красвелл, Microsoft, Redmond, США;
(12) Xing Xie, Microsoft, Пекин, Китай;
(13) Fan Yang, Microsoft, Пекин, Китай;
(14) Брайан Тауэр, Microsoft, Редмонд, США;
(15) Нихил Рао, Microsoft, Mountain View, США;
(16) Anlei Dong, Microsoft, Mountain View, США;
(17) Венки Цзян, Эт Цюрих, Цюрих, Швейцария;
(18) Чжэн Лю, Microsoft, Пекин, Китай;
(19) Mingqin Li, Microsoft, Redmond, США;
(20) Chuanjie Liu, Microsoft, Пекин, Китай;
(21) Зенчжонг Ли, Microsoft, Редмонд, США;
(22) Ранган Мадждер, Microsoft, Редмонд, США;
(23) Дженнифер Невилл, Microsoft, Редмонд, США;
(24) Энди Окли, Microsoft, Редмонд, США;
(25) Knut Magne Risvik, Microsoft, Осло, Норвегия;
(26) Харша Вардхан Симхадри, Microsoft, Бангалор, Индия;
(27) Маник Варма, Microsoft, Бенгалор, Индия;
(28) Юджин Ван, Microsoft, Пекин, Китай;
(29) Линджун Ян, Microsoft, Редмонд, США;
(30) Мао Ян, Microsoft, Пекин, Китай;
(31) CE Zhang, Eth Zürich, Zürich, Швейцария, и работа была выполнена в Microsoft.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)