
Зачем извлечение текста из PDFS по -прежнему ощущается как взлом - и устаревший дизайн, который застрял ИИ
2 июля 2025 г.Разработки, работающие с LLMS, постоянно сталкиваются с анализом документов. И каждые несколько месяцев вокруг проблемы PDF есть новая волна шумихи (или разочарования). В эти моменты нередко видеть, что программное обеспечение, ребята, высказалось о том, как один формат файла стал такой огромной головной болью. Но борьба не нова.
Задолго до того, как LLMS вступил в картину, целые предприятия SaaS были построены вокруг управления беспорядком PDF. И на то есть веские причины, это формат, который никогда не был предназначен для структурированного, машино читаемого доступа, который мы теперь ожидаем.
Когда программное обеспечение становится таким же широко распространенным, как Adobe Acrobat и формат PDF, оно начинает ощущаться как постоянная часть ландшафта. Легко забыть, что за этим повсеместным распространением были реальные дизайнерские решения, ограничения и компромиссы, сделанные реальными инженерами, решающими реальные проблемы. Проблемы, которые со временем развивались и стали корнями сегодняшней боли.
Да, PDF -файлы разочаровывают. Но они не родились сломанными. На самом деле, они были удивительно элегантным решением для своего времени.
Итак, давайте увеличимся. Эта история делает шаг назад, чтобы исследовать происхождение формата PDF: как это произошло, какие проблемы он решил решить, и как решения, принятые в начале 90 -х годов, все еще пролистывают сегодняшнюю стек. Цель: понять не только «Почему это так сложно?», Но и «как мы сюда попали?»
Вернемся к 80 -х годам, от бумаги до пикселей.
Сдвиг начался. Персональные компьютеры взрывались в популярности, а бумажные документы больше не были дефолтом. Программное обеспечение, такое как Visicalc, WordStar, WordPerfect и Range Microsoft Word, отмечало рассвет нового способа писать, редактировать и поделиться.
К концу 80 -х годов Suites почти убили пишущую машинку. Руководители могут настроить отчеты за несколько минут до встречи. Аналитики запускали сценарии «что если» в электронных таблицах. Учителя печатали тесты на лету. Инженеры заменили составы столов на цифровые чертежи.
Документы все чаще стали новым рабочим местом. Не только конечный продукт, но и там, где на самом деле произошла работа.
90 -е и рождение PDF.
В начале 1990-х годов рост обработки текстов на основе ПК и электронный обмен файлами решал много проблем, в то же время внедрив новые. У каждого компьютера были свои собственные шрифты, драйверы принтеров и причуды макета. Отчет, который выглядел идеально на одной машине, может напечатать как беспорядочный беспорядок на другой. Обмен файлами стала азартной игрой.
Чтобы исправить это, в 1991 году соучредитель Adobe Джон Уорнок и его команда запустили проект под кодовым названием «Camelot» для создания действительно универсального формата документов. Результатом стал PDF, файл, который встроенные шрифты, графика и макет страницы в одном месте. Эта «цифровая бумага» гарантировала, что документы выглядели точно так же везде, будь то на Windows, Mac или любом принтере.
Собешая каждый шрифт, изображение и детали макета в один файл, PDF -файлы позволяют пользователям обмениваться документами без сюрпризов, и то, что вы видите на экране, напечатано точно одинаково везде. Adobe сделал бесплатный читатель Acrobat доступным в 1994 году, и в течение пяти лет PDF стал форматом для всего, от руководств по продукту и корпоративных отчетов до государственных форм и академических работ.
К началу 2000-х годов «Экспорт как PDF» был вариантом в один клик практически в каждом инструменте авторизации, и организации в разных отраслях приняли его для распространения, архивирования и соответствия. И это все еще стандарт сегодня.
PDF -дизайнерская ловушка
То, что сделало PDFS настолько привлекательными (их обещание о том, что Pixel-идеальная верность), также представило скрытый компромисс: он заблокировал контент в жесткую, первую структуру печати.
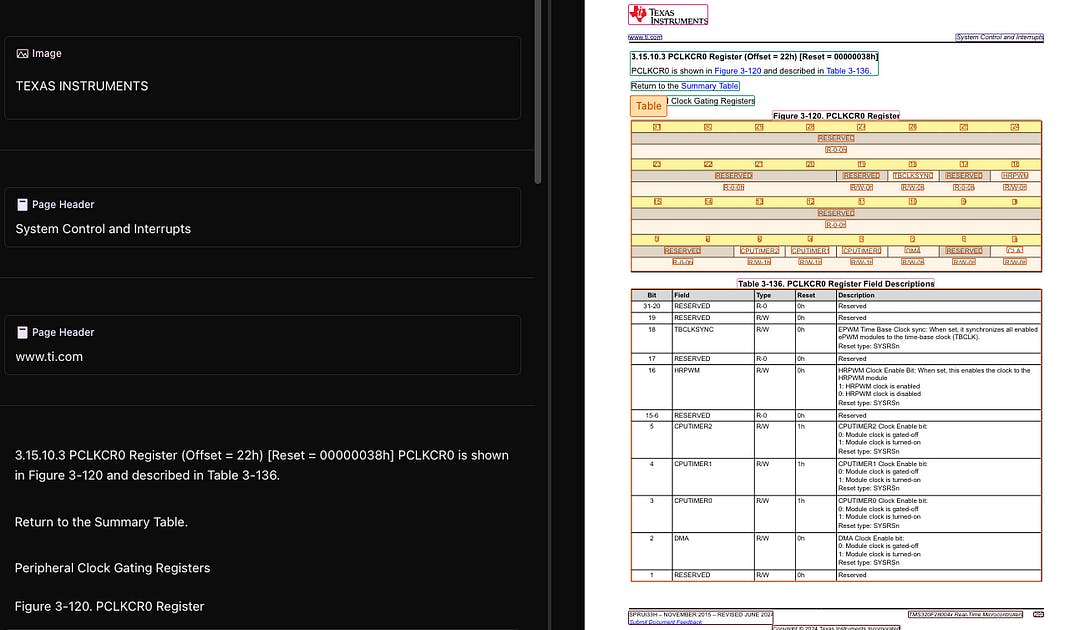
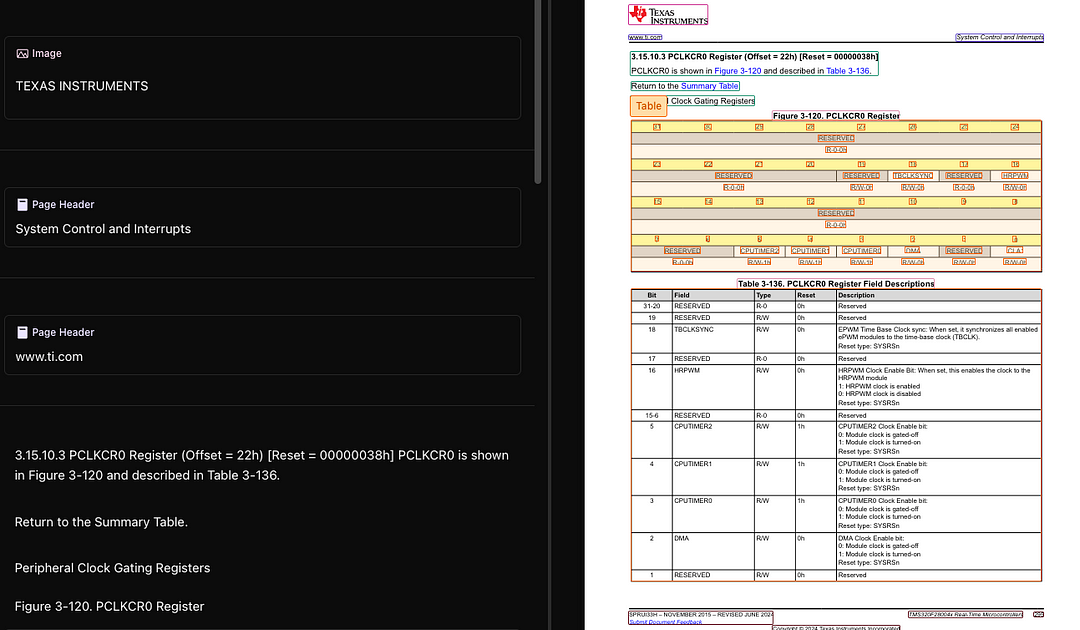
Под каждой безупречной страницей был по сути цифровой снимок, созданный, чтобы имитировать то, что вышло из принтера. Заголовки, столы, абзацы, ни один из них не имел семантического значения. Для компьютера это были просто координаты и текстовые поля, разбросанные по холсту.
Сначала это не имело значения. Но когда документы перемещались с рабочих столов в веб -браузеры, мобильные экраны и автоматизированные трубопроводы, трещины начали показывать. Хотите извлечь чистые данные? Текст с помощью телефона? Понимать структуру документа? Внезапно то, что выглядело чисто для людей, стало беспорядком для машин.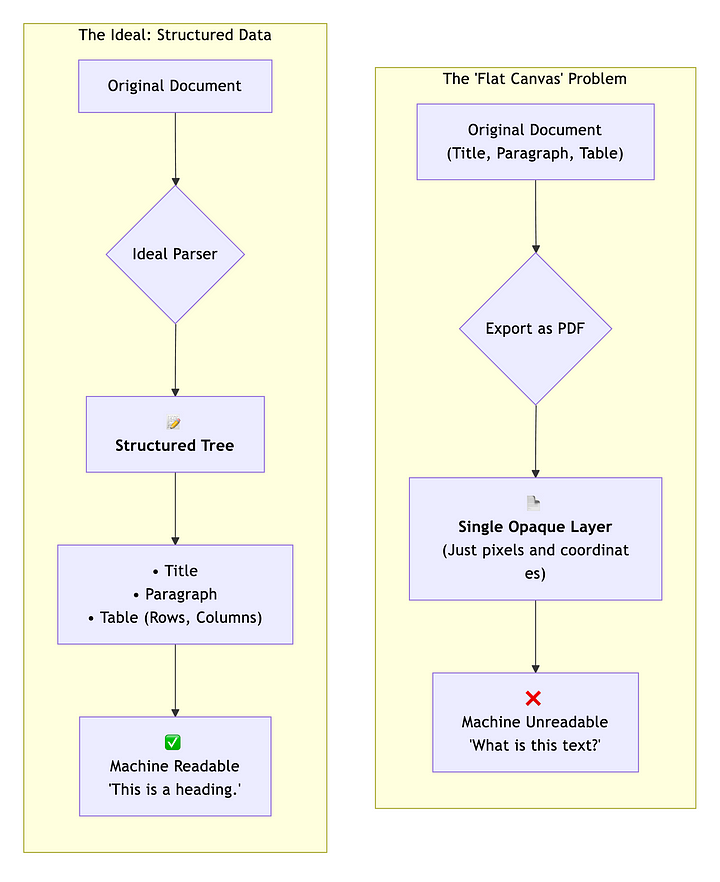
Tagged PDF и другие попытки модернизации
Adobe не была слепой к проблеме. Tagged PDF (введенный в 2001 году, а затем формализованный в PDF/UA для доступности) добавляет HTML-подобную логическую структуру. Он никогда не стал универсальным, но он предназначен для доступных правительственных документов и широко используется в рабочих процессах крупно предпринимаемого. Другие вехи, такие как PDF/A для долгосрочного архивирования, поддержка метаданных XMP и передача спецификации 2008 года, показывают устойчивые усилия по модернизации формата. Тем не менее, широкое усыновление отстало; Метка невидима для большинства пользователей, утомительно для создателей и часто разряжается небрежными настройками экспорта.
Целая экосистема инструментов SaaS появилась, чтобы преодолеть этот разрыв. Вы видите его в тяжеловесах, таких как Docusign, во многих веб-редакторах PDF, таких как Dochub, и в библиотеках с открытым исходным кодом, таким как Poppler, от которых разработчики зависят только для того, чтобы вытащить текст из PDF.
Именно поэтому все крупные облачные игроки бросают в эту проблему серьезную мускулы ИИ: AWS с Textract, Google с AI Document AI и Microsoft с интеллектом Azure AI Document. Рынок появился, последовало продукты, а также много доходов. Adobe, нравится нам это или нет, изменил игру.
Восстание обработки PDF-PDF
Когда ЧАТГПТ ударил, «Проблема PDF» взорвалась. Компании пытались подавать свои данные в LLMS, только чтобы попасть в стену: большая часть этой ценной информации была заблокирована внутри PDF.
Сначала цель была проста: просто извлечь чистый текст для поколения, задуманного (RAG). Но это быстро оказалось слишком простым. Без осознания макета текст из столбцов разразился, таблицы превратились в чушь, изображения игнорировались, а важный контекст исчез.
Современный документ AI теперь обучает модели для понимания визуальной и логической планировки документа: определение названий, абзацев, таблиц и изображений. Таким образом, ИИ может ссылаться на информацию, пропустить повторяющиеся заголовки/нижние колонтитулы и понять общую структуру.
Этот стек ИИ раскрывает полную степень беспорядка, с которым мы имеем дело. То, что должно быть простым извлечением данных, теперь требует нескольких специализированных слоев:
- Анализ макета для понимания структуры документа,
- OCR для извлечения текста из изображений и отсканированных документов,
- VLM оркестровка для координации этих различных компонентов ИИ.
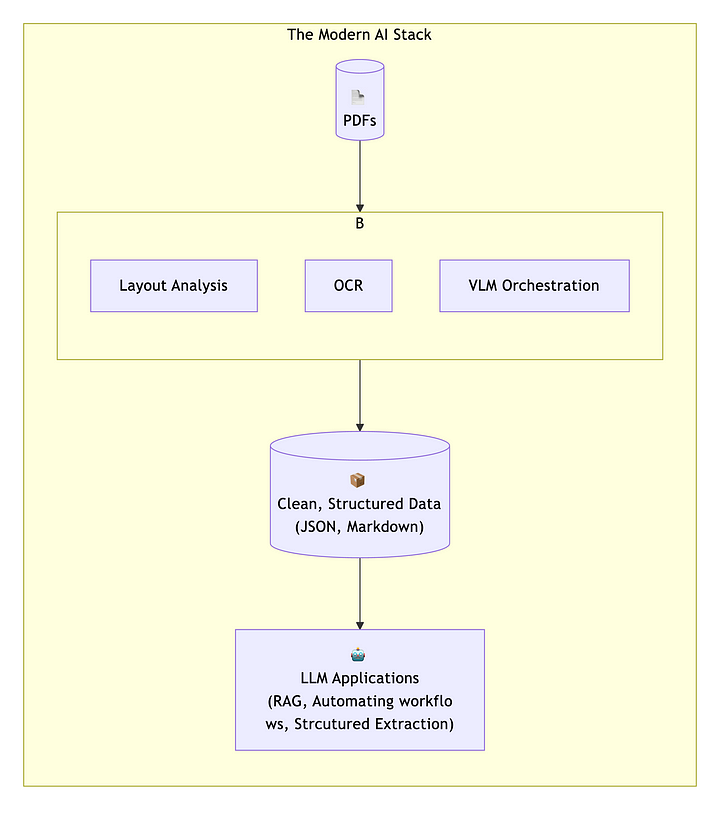
Каждый слой добавляет задержку, потенциальные ошибки и расчет. Ирония ошеломляет: мы используем некоторые из самых продвинутых моделей ИИ, когда-либо созданных, чтобы решить проблему, которая связана с 30-летним решением лечить документы, такие как фотографии.
В то время как PDF-файлы постепенно развивались, их Печатная ДНК сохраняет затраты на накапливание на каждом современном рабочем процессе. Структурированные форматы, отсканированные или сфотографированные, представляют некоторые из тех же препятствий, но дизайн PDF усиливает боль.
Путь вперед
Мы не можем отказаться от десятилетий PDF -файлов в течение ночи, но мы можем избежать повторения истории. Для нового контента выберите форматы рожденных цифр, которые по умолчанию сохраняют семантику:
- HTML5 для Интернета,
- Стандарты на маркеун для технических документов,
- или docx/ooxml, когда совместимость офиса является обязательной.
Когда файл с фиксированным лайком неизбежен, экспорт с полными тегами и метаданными нетронуты; Некоторые инструменты авторизации теперь автоматизируют это. Правила государственных закупок, которые требуют соответствия PDF/UA, являются положительным прецедентом. Аналогичное давление со стороны предприятий на поставщиков и регуляторов может преодолеть теги от «хорошего до« до «столовых ставок».
В долгосрочных, открытых стандартах, таких как портативная веб-публикация W3C или EPUB 3, наряду с предстоящими контейнерными форматами JSON, обещают точность без жертвоприношения структуры. Поддержка их в основных инструментах авторизации (и обучение пользователей их принять) избавит от написания моделей Vision модели следующего поколения, чтобы вытащить текст из контракта.
История PDFS доказывает, что ранний выбор дизайна эхо на протяжении десятилетий. Урок не заключается в том, чтобы вывести инженеров, которые решили проблему 1991 года; Признать, что сегодняшние «достаточно хорошие» ярлыки становятся дорогостоящими наручниками завтрашнего дня. Давайте внедрим семантику в источник, откройте, автоматически читаемые стандарты и обеспечим, чтобы следующая волна технологии документов построена как для людей, так и для машин.
Для команд, уже имеющих дело с устаревшими форматами, такие инструменты, какЧункрПредложите конвейер на основе API с открытым исходным кодом для преобразования сложных документов в структурированные, кусоченные форматы, адаптированные для рабочих процессов LLM и RAG, доступные как в качестве размещенных конечных точек, так и самоуправленной инфраструктуры.
Изо всех сил пытаетесь вырастить свою аудиторию как технический профессионал?
Технологическая аудитория ускорительЭто новостная рассылка для создателей технологий, серьезно относится к выращиванию своей аудитории. Вы получите проверенные рамки, шаблоны и тактику, стоящие за моими 30 -метровыми впечатлениями (и подсчетом).
https://techaudienceaccelerator.substack.com/?embedable=true
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)