

Какой формат pg_dump самый быстрый и самый маленький? Эксперимент с 21-резор
1 августа 2025 г.Я сделал резервную копию, используяpg_dumpи восстановил его 21 раз. Я сделал резервное копирование в 4 различных форматах, используя 1-7 уровней сжатия для каждого формата. Я записал результаты и сравнил различные типы, чтобы понять, какие методы более эффективны для моего случая использования.
Детали и измерения ниже.

Таблица контента:
- Зачем мне это измерение?
- Форматы резервного копирования и типы сжатия в PG_DUMP
- PostgreSQL Конфигурация
- Подготовка данных
- Результаты измерения
- Выводы, основанные на измерениях
- Заключение
Зачем мне это измерение?
У меня была очень конкретная задача: найти лучший формат резервного копирования, используя стандартpg_dumpПолем «Лучший» означает оптимальное соотношение скорости создания резервного копирования, скорости восстановления и окончательного размера файла.
Я использовал эту информацию в своем проекте с открытым исходным кодом для
Были дополнительные требования:
- резервная копия должна быть сжатаПеред отправкойна мой сервер, чтобы минимизировать использование сети;
- Сам файл резервного копированияДолжен быть единственный файл(а не, например, каталог), чтобы его можно было транслировать на диск, S3 или облако;
- Метод создания резервного копирования не должен потребовать заранее какую-либо конфигурацию базы данных (поэтому, PGBackRest, WAL-G и PG_BASEBACKUP, были исключены), чтобы быть легко интегрированной в проект с открытым исходным кодом и работу с любой базой данных (установленные локально, в Docker, в DBAAS, с репликой для чтения и т. Д.).
Форматы резервного копирования и типы сжатия в PG_DUMP
pg_dumpПоддерживает 4 формата:
Равнина (SQL):
- ❌ Нет сжатия.
- ✅ создает один файл.
- ❌ делаетнетПоддержка параллельной резервной копии.
- ❌ делаетнетПоддержка параллельного восстановления.
Custom (-fc):
- ✅ Сжатие включено.
- ✅ создает один файл.
- ❌ делаетнетПоддержка параллельной резервной копии.
- ✅ поддерживает параллельное восстановление.
Каталог (-fd):
- ✅ Сжатие включено.
- ❌ Ни один файл (выводит каталог файлов).
- ✅ поддерживает параллельную резервную копию.
- ✅ поддерживает параллельное восстановление.
TAR (-ft):
- ✅ Сжатие включено.
- ✅ создает один файл (TAR Archive).
- ❌ делаетнетПоддержка параллельной резервной копии.
- ❌ делаетнетПоддержка параллельного восстановления.
Меня больше всего интересовалось пользовательским форматом и форматом каталогов. Они поддерживают параллельную обработку резервных копий. Пользовательский формат не может создать резервную копию параллельно (только восстановить), но записывает его в один файл. Формат каталога может как резервным, так и восстановлением параллельно, но пишет все в каталог.
Для этих форматов поддерживаются следующие типы сжатия:
Gzip:
- Стандартный алгоритм сжатия
- Скорость сжатия: средняя;
- Скорость декомпрессии: высокая.
- Коэффициент сжатия: 2–3 ×.
LZ4:
- Алгоритм настроен на гораздо более высокую скорость, чем Gzip.
- Сжатие и декомпрессия: очень высокая.
- Коэффициент сжатия: 1,5–2 ×.
zstd:
- Относительно новый (2016) алгоритм из Facebook/Meta, уравновешивание скорости и сжатия.
- Скорость сжатия: высокая;
- Скорость декомпрессии: высокая.
- Коэффициент сжатия: 3–5 ×.
Описанные характеристики сжатия основанына идеально подготовленных данныхПолем В случае базы данных сжатие не занимает 100% случаев с использованием 100% использования ЦП. Есть много операций, специфичных для базы данных, которые, вероятно, замедлит сжатие (особенно «на лету»).
Перед тестированием я предположил, что пользовательский формат с сжатием GZIP будет лучшим вариантом для меня (как счастливой среды) и имел осторожные надежды на ZSTD (как более современный формат). Кстати, ZSTD начал поддерживать только в PostgreSQL 15.
PostgreSQL Конфигурация
Я запустил два экземпляра PostgreSQL в Docker Compose: один для создания резервных копий (с данными) и один для восстановления из них. Я не использовал стандартные порты, потому что они уже используются моими местными версиями PostgreSQL.
Docker-Compose.yml
version: "3.8"
services:
db:
image: postgres:17
container_name: db
environment:
POSTGRES_DB: testdb
POSTGRES_USER: postgres
POSTGRES_PASSWORD: testpassword
ports:
- "7000:7000"
command: -p 7000
volumes:
- ./pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -d testdb -p 7000"]
interval: 10s
timeout: 5s
retries: 5
restart: unless-stopped
db-restore:
image: postgres:17
container_name: db-restore
environment:
POSTGRES_DB: testdb
POSTGRES_USER: postgres
POSTGRES_PASSWORD: testpassword
ports:
- "7001:7001"
command: -p 7001
volumes:
- ./pgdata-restore:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -d testdb -p 7001"]
interval: 10s
timeout: 5s
retries: 5
restart: unless-stopped
depends_on:
- db
Затем я немного обновил postgresql.conf, чтобы использовать больше компьютерных ресурсов. У меня есть AMD Ryzen 9 7950x (16 ядер, 32 потока), 64 ГБ оперативной памяти и привод NVME 1 ТБ. Я настроил базу данных для использования 4 потоков и 16 ГБ памяти через PGTUNE.
postgresql.conf
# DB Version: 17
# OS Type: linux
# DB Type: web
# Total Memory (RAM): 16 GB
# CPUs num: 4
# Connections num: 100
# Data Storage: ssd
max_connections = 100
shared_buffers = 4GB
effective_cache_size = 12GB
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
effective_io_concurrency = 200
work_mem = 40329kB
huge_pages = off
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 4
max_parallel_workers_per_gather = 2
max_parallel_workers = 4
max_parallel_maintenance_workers = 2
listen_addresses = '*'
Подготовка данных
Для начала я создал базу данных с 3 таблицами и 9 индексами с общим размером ~ 11 ГБ. Данные максимально разнообразны. Я более чем уверен, что PG_DUMP работает лучше с некоторыми типами данных и хуже с другими. Но мой проект нацелен на широкую аудиторию, поэтому важно измерить «среднее по всем направлениям».
Ниже приведена структура таблицы.
Таблицы:
- laign_test_table:Сотрудники и пользователи с различными типами данных. 18 колонн, включая
nameВemailВaddressВsalary, и т. д. - Заказы:Заказ данных и их история изменений. 13 столбцов, включая
user_idВorder_numberВamounts, и т. д. - Activity_logs:Журналы активности пользователя с большими текстовыми полями. 13 столбцов, включая
user_idВactionВdetailsВtimestamps, и т. д.
Индексы:
- big_test_table-
idx_large_test_nameнаname: 🔍 Поиск по имени. - big_test_table-
idx_large_test_emailнаemail: 🔍 Поиск по электронной почте. - big_test_table-
idx_large_test_created_atнаcreated_at: 🕒 Поиск по временному диапазону. - big_test_table-
idx_large_test_departmentнаdepartment: 🗂 Фильтр по департаменту. - приказ-
idx_orders_user_idнаuser_id: 🔍 Поиск заказов пользователя. - приказ-
idx_orders_order_dateнаorder_date: 🕒 Поиск по дате заказа/времени. - приказ-
idx_orders_statusнаstatus: 🔍 Поиск по статусу. - Activity_logs-
idx_activity_user_idнаuser_id: 🔍 Поиск по идентификатору пользователя. - Activity_logs-
idx_activity_timestampнаtimestamp: 🕒 Поиск по дате. - Activity_logs-
idx_activity_actionнаaction: 🔍 Поиск по действию.
Данные генерируются и вставляются в базу данных с использованием сценария Python. Алгоритм выглядит следующим образом:
- 25 000 рядов данных генерируются;
- 100 000 рядов вставляются в каждую таблицу по очереди с использованием копии;
- Когда база данных достигает размера 10 ГБ, создаются индексы.
Результаты измерения
После 21 создания и восстановления я получил следующую таблицу с данными, которые включают:
- Скорость создания резервного копирования;
- восстановить скорость из резервной копии;
- общее время;
- Размер резервного копирования по сравнению с исходным размером базы данных.
Таблица с необработанными данными CSV:
tool,format,compression_method,compression_level,backup_duration_seconds,restore_duration_seconds,total_duration_seconds,backup_size_bytes,database_size_bytes,restored_db_size_bytes,compression_ratio,backup_success,restore_success,backup_error,restore_error,timestamp
pg_dump,plain,none,0,100.39210295677185,735.2188968658447,835.6109998226166,9792231003,11946069139,11922173075,0.8197031918249641,True,True,,,2025-07-29T09:56:20.611844
pg_dump,custom,none,0,264.56927490234375,406.6467957496643,671.216070652008,6862699613,11946069139,11943709843,0.5744734550878778,True,True,,,2025-07-29T10:07:37.226681
pg_dump,custom,gzip,1,214.07211470603943,383.0168492794037,597.0889639854431,7074031563,11946069139,11943611539,0.5921639562511493,True,True,,,2025-07-29T10:17:39.801883
pg_dump,custom,gzip,5,260.6179132461548,393.76623010635376,654.3841433525085,6866440205,11946069139,11943718035,0.5747865783384196,True,True,,,2025-07-29T10:28:40.167485
pg_dump,custom,gzip,9,272.3802499771118,385.1409020423889,657.5211520195007,6856264586,11946069139,11943619731,0.5739347819121977,True,True,,,2025-07-29T10:39:42.912960
pg_dump,custom,lz4,1,84.0079517364502,379.6986663341522,463.7066180706024,9146843234,11946069139,11943685267,0.765678075990583,True,True,,,2025-07-29T10:47:32.131593
pg_dump,custom,lz4,5,150.24981474876404,393.44346714019775,543.6932818889618,8926348325,11946069139,11943718035,0.7472205477078983,True,True,,,2025-07-29T10:56:41.333595
pg_dump,custom,lz4,12,220.93980932235718,418.26913809776306,639.2089474201202,8923243046,11946069139,11943767187,0.7469606062188722,True,True,,,2025-07-29T11:07:26.574678
pg_dump,custom,zstd,1,87.83108067512512,419.07846903800964,506.90954971313477,6835388679,11946069139,11943767187,0.5721872692570225,True,True,,,2025-07-29T11:15:59.917828
pg_dump,custom,zstd,5,102.42366409301758,413.64263129234314,516.0662953853607,6774137561,11946069139,11944357011,0.567059966100871,True,True,,,2025-07-29T11:24:42.075008
pg_dump,custom,zstd,15,844.7868592739105,388.23959374427795,1233.0264530181885,6726189591,11946069139,11943636115,0.5630462633973209,True,True,,,2025-07-29T11:45:17.885163
pg_dump,custom,zstd,22,5545.566084384918,404.1370210647583,5949.7031054496765,6798947241,11946069139,11943750803,0.5691367731000038,True,True,,,2025-07-29T13:24:30.014902
pg_dump,directory,none,0,114.9900906085968,395.2716040611267,510.2616946697235,6854332396,11946069139,11943693459,0.5737730391684116,True,True,,,2025-07-29T13:33:05.944191
pg_dump,directory,lz4,1,53.48561334609985,384.92091369628906,438.4065270423889,9146095976,11946069139,11943668883,0.7656155233641663,True,True,,,2025-07-29T13:40:30.590719
pg_dump,directory,lz4,5,83.44352841377258,410.42058181762695,493.86411023139954,8925601067,11946069139,11943718035,0.7471579950814815,True,True,,,2025-07-29T13:48:50.201990
pg_dump,directory,lz4,12,114.15110802650452,400.04946303367615,514.2005710601807,8922495788,11946069139,11943758995,0.7468980535924554,True,True,,,2025-07-29T13:57:30.419171
pg_dump,directory,zstd,1,57.22735643386841,414.4600088596344,471.6873652935028,6835014976,11946069139,11943750803,0.5721559867493079,True,True,,,2025-07-29T14:05:28.529630
pg_dump,directory,zstd,5,60.121564865112305,398.27933716773987,458.4009020328522,6773763858,11946069139,11943709843,0.5670286835931563,True,True,,,2025-07-29T14:13:13.472761
pg_dump,directory,zstd,15,372.43965554237366,382.9877893924713,755.427444934845,6725815888,11946069139,11943644307,0.5630149808896062,True,True,,,2025-07-29T14:25:54.580924
pg_dump,directory,zstd,22,2637.47145485878,394.4939453601837,3031.9654002189636,6798573538,11946069139,11943660691,0.5691054905922891,True,True,,,2025-07-29T15:16:29.450828
pg_dump,tar,none,0,126.3212628364563,664.1294028759003,790.4506657123566,9792246784,11946069139,11942759571,0.8197045128452776,True,True,,,2025-07-29T15:29:45.280592
Мне пришлось удалить результаты для ZSTD с уровнем сжатия 15 и ZSTD с уровнем сжатия 22 с графиков. Они значительно искажали графики из -за длительного времени сжатия, не обеспечивая никакого заметного увеличения сжатия.
Итак, измерения.
Скорость резервного копирования за секунды (ниже лучше):
Увеличение изображения будет отображаться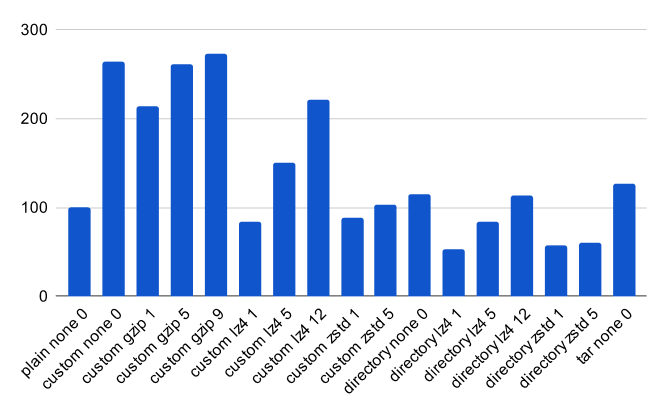
Восстановить скорость из резервного копирования за считанные секунды (лучше лучше):
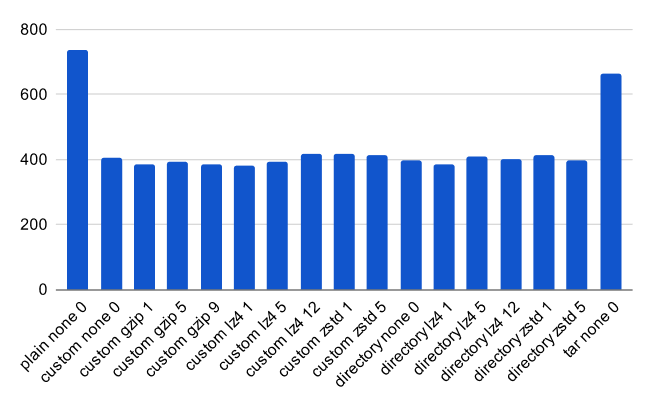
Общее время для создания и восстановления из -за резервной копии за считанные секунды (ниже лучше):
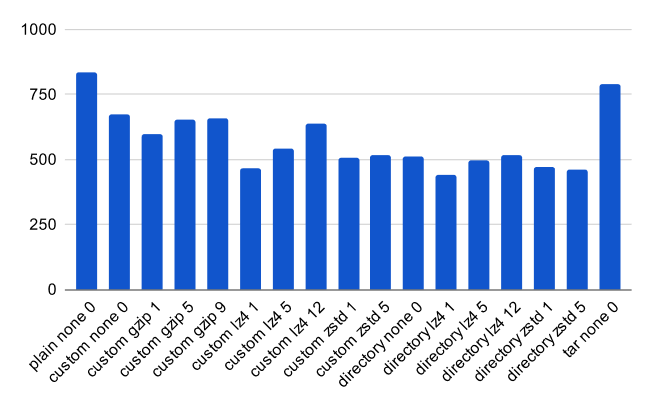
Общий размер резервного копирования в процентах от исходного размера базы данных (меньше лучше):
Увеличение изображения будет отображаться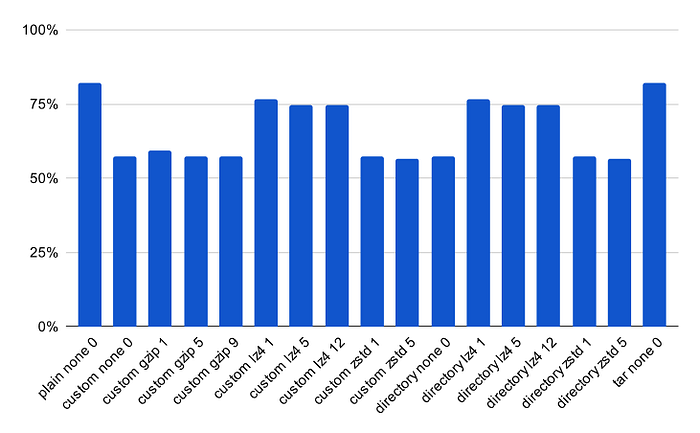
Выводы, основанные на измерениях
Прежде чем говорить о выводах, я хотел бы сделать важный отказ от ответственности:Тест был выполнен на синтетических данных, и результаты с данными «реального мира» будут значительно различатьсяПолем Тенденция будет такой же, но разница во времени будет больше.
Измерения показывают, что не существует радикальной разницы в скорости между обычным форматом, пользовательским форматом и форматом каталогов на синтетических данных. Несмотря на то, что пользовательский формат восстанавливается в параллельном режиме по сравнению с простым, и формат каталога также создает саму копию параллельно.
Разница в скорости между пользовательским форматом и равниной составляет ~ 30%. Между пользовательскими и форматами каталогов это составляет всего ~ 20%. Я бы предположил, что в данных тестирования отсутствовали достаточное количество независимых таблиц и объектов - в противном случае разрыв между форматами был бы в несколько раз больше.
Итак, на основе измерений, я могу сделать следующие выводы:
- ** Самый быстрый формат резервного копирования основан на каталогах.
\ Пользовательский формат быстрее, чем простой, и смол с точки зрения общего времени при любых обстоятельствах. Формат каталога быстрее, чем пользовательский при любых обстоятельствах. Если параллельный режим включен, конечно.
Более того, с точки зрения скорости создания резервного копирования формат каталогов более чем в два раза быстрее, чем пользовательский формат. Это очень важно, учитывая, чтоМы делаем резервные копии чаще, чем мы восстанавливаем из нихПолем - ** Наиболее полезным с точки зрения соотношения «скорость и уровня сжатия» был ZSTD с уровнем сжатия 5. \ С точки зрения скорости создания резервного копирования, оно превзойдет только несжатые форматы. С точки зрения скорости восстановления, он в среднем на 4% медленнее, чем другие форматы. В то же время он имеет максимальное сжатие, сравнимое с GZIP с уровнем сжатия 9, но превосходит его на скорости на ~ 18%. Принимая во внимание маржу ошибки на синтетических данных.
- ZSTD 15 и ZSTD 22 оказались бесполезными в этом конкретном тесте.Они дали уровни сжатия примерно так же, как GZIP 9, но для получения результата потребовалось в 2-8 раза дольше.
Я думаю, что с базой данных не менее 1 ТБ без синтетических данных и холодного хранения они будут показывать совершенно разные результаты и могут оказаться очень экономически эффективными (особенно если вам нужно сделать сотни резервных копий и хранить их в течение длительного времени).
Заключение
Измерение показало, что наиболее оптимальным форматом для моей задачи был пользовательский формат с сжатием ZSTD и уровнем сжатия 5. Я получаю максимальную общую скорость с почти максимальной сжатием и одним файлом резервного копирования.
После реализации ZSTD 5 вместо GZIP 6 в проекте размер резервного копирования был уменьшен почти наполовину с немного более коротким временем резервного копирования. В то же время, в отличие от синтетических данных, база данных 4,7 ГБ была сжата до 276 МБ (в 17 раз меньше!):
Увеличение изображения будет отображаться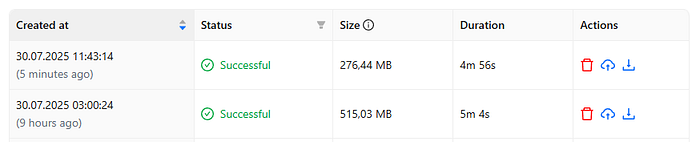
Я надеюсь, что мой тест будет полезен для тех, кто разрабатывает инструменты резервного копирования или регулярно сбрасывает базы данных, используя сценарии PG_DUMP. Возможно, в будущем я проведу тот же тест, но с более разнообразным набором данных.
И еще раз, если вам нужно создавать регулярные резервные копии, у меня есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)