

Где происходит контекстный перевод в больших языковых моделях: Где происходит контекстный машинный перевод?
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Conclusion, Acknowledgments, and References
- А. Приложение
3. Где происходит контекстный машинный перевод?
3.1 Маскирование по слою из контекста
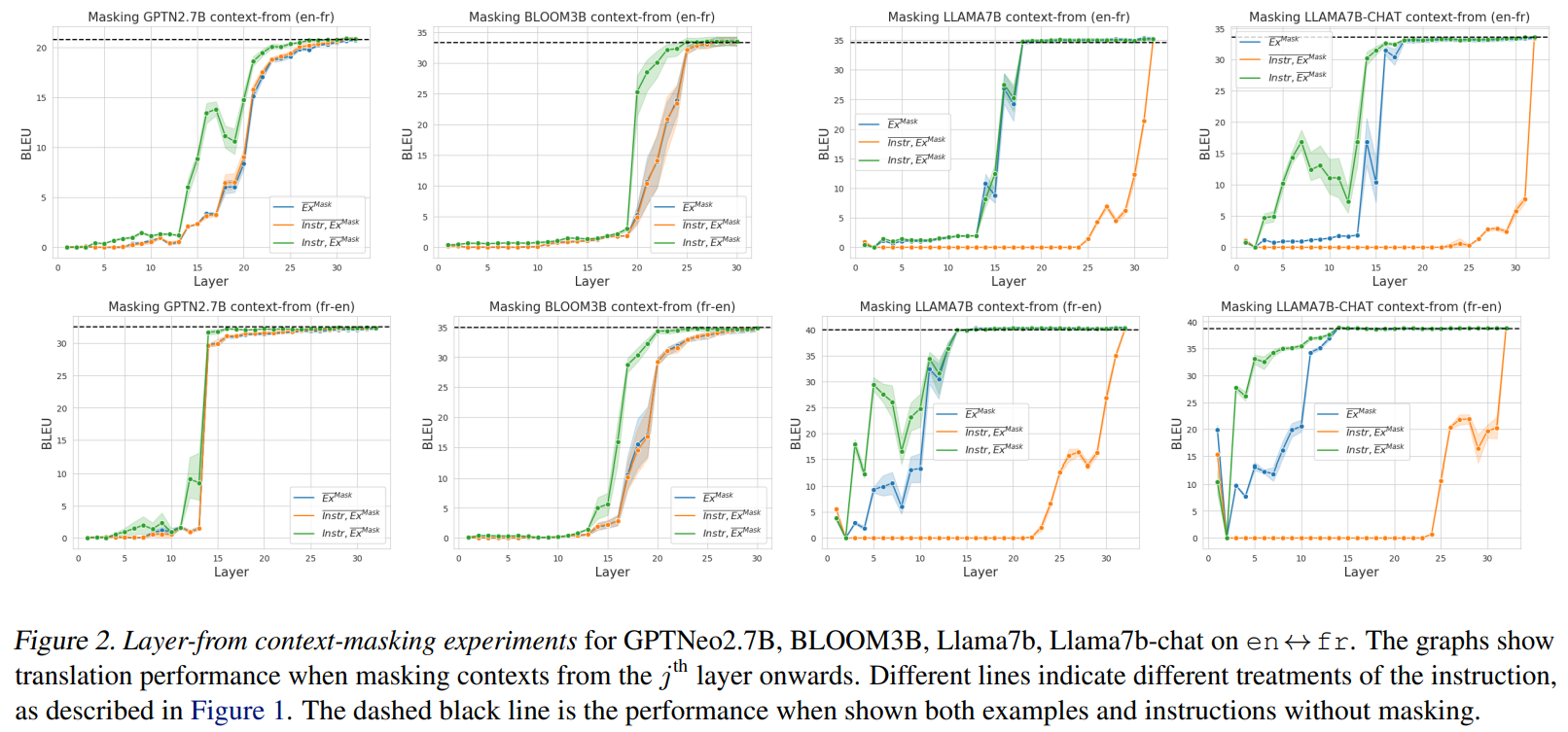
Обучение в контексте отличается от контролируемого обучения, ориентированного на конкретные задачи, тем, что во время тестирования желаемая задача должна быть сначала идентифицирована из контекста, а затем выполнена. На каком этапе вычисления прямой связи модель в стиле GPT переходит от обучающегося в контексте к модели перевода? Чтобы исследовать этот вопрос, мы вводим маскировку слоя из контекста, которая маскирует все веса внимания к контексту (инструкции или подсказки) с определенного слоя и далее (см. рисунок 1 для графического описания).

При таком методе маскирования причинно-следственных связей, маскирующего данные из слоя ℓ, модель должна полагаться только на представления целевого входного предложения из слоя ℓ + 1 для выполнения задачи; если представления целевого предложения еще не кодируют целевую задачу (перевод на определенный язык), то модель не сможет сгенерировать переводы.

3.2 Результаты
Мы обсуждаем основные выводы статьи:Для выполнения задачи моделям не нужно удерживать внимание на всем контексте на каждом уровне.

Различные модели достигают этой точки плато на разных слоях. В GPTNEO эта точка происходит около слоя 25, в BLOOM эта точка происходит около слоя 15-20, а в моделях LLAMA это происходит около слоя 13-15. Поскольку английский язык является доминирующим, как и ожидалось, модели могут успешно выполнять перевод на английский на более ранних слоях маскировки, чем перевод с английского.
На этом этапе модели получают лишь незначительную выгоду, если вообще получают, от учета контекста, что предполагает, что большая часть «локации» задачи уже выполнена.
Существуют критические слои для локализации задач.До точки распознавания задачи, около средних слоев моделей, перемещение маски контекста на один слой вверх приводит к значительному увеличению производительности. Мы рассматриваем эти критические слои, так как вместо постепенного увеличения производительности мы наблюдаем очень крутые скачки более чем на 20 точек bleu по разным моделям. Мы предполагаем, что модель находит правильную задачу во время обработки в этих средних слоях, после чего контекст больше не нужен для выполнения задачи перевода.
В целом, наши результаты показывают, что процесс обучения в контексте состоит из 3 фаз: на первой фазе перемещение маски вверх не оказывает существенного влияния на производительность, которая близка к 0. Это говорит о том, что контекст вообще не повлиял на местоположение задачи. На второй фазе перемещение маски вверх существенно влияет на производительность машинного перевода, что говорит о том, что модель начала определять местоположение задачи, но может значительно улучшиться при более глубокой обработке контекста. Наконец, на третьей фазе повторное перемещение маски вверх практически не оказывает влияния на производительность машинного перевода, что говорит о том, что модель полностью распознала задачу как перевод и больше не требует контекста для ее интерпретации.
Дальнейшие наблюдения и абляции представлены в следующих разделах.
3.3 Модели, настроенные на инструкции и не настроенные на инструкции

В целом мы обнаружили, что наблюдение за слоями распознавания задач и точкой распознавания задач присутствует как в моделях без настройки на инструкции, так и в моделях с настройкой на инструкции, и что это проявляется одинаково в обоих типах моделей.
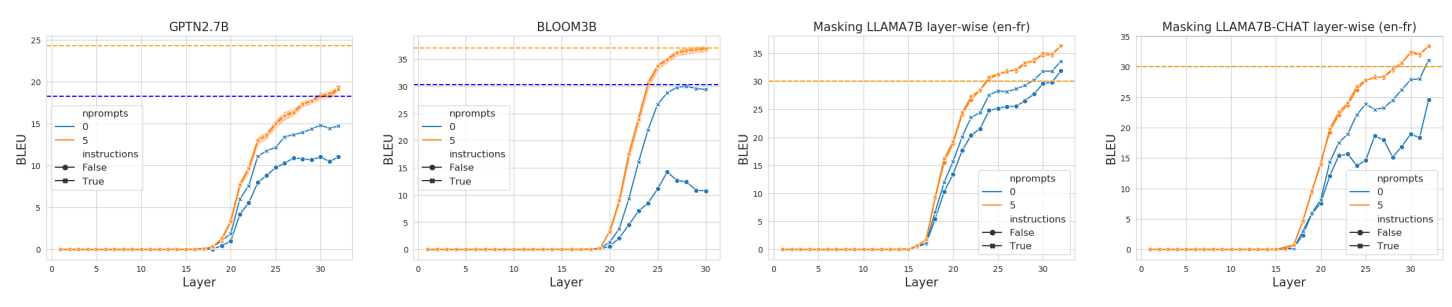
3.4 Роль инструкций и примеров

3.5. Внимание к контексту против внимания к вводу
Одно из возможных объяснений результатов на рисунке 2 заключается в том, что вместо определения точки, в которой задача распознается, мы определили точку, в которой модели больше не требуется уделять внимание никаким другим входным токенам. Чтобы исследовать это, мы проводим эксперименты в направлении en → fr, где мы маскируем внимание ко всем входам, начиная с определенного слоя. Это не включает маскирование текста, сгенерированного моделью.
Мы отображаем результаты на рисунке 3; мы обнаружили, что для всех моделей слой, на котором внимание может быть полностью удалено, намного выше слоя, на котором мы можем удалить внимание на контекст. Для GPTNEO и LLAMA производительность перевода никогда не сопоставима с базовой линией без маскирования. Наоборот, при маскировании только контекста производительность перевода улучшается уже на слое 10 и выходит на плато на базовой линии без маски гораздо раньше. Это подтверждает интерпретацию того, что кривые, которые мы наблюдаем на рисунке 2, обусловлены тем, что модель все еще требует внимания к исходному предложению.
Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[2] Читателям следует обратить внимание на то, что для каждого слоя и каждой точки внимания существует матрица весов Wk и Wq, но мы опускаем это обозначение для удобства чтения.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Как начать дружбу с Selenide
30 марта 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
Categories
- Технологии и IT (26906)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)