

Где происходит контекстный перевод в больших языковых моделях: данные и настройки
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Заключение, благодарности и ссылки
- А. Приложение
2. Данные и настройки
МоделиМы используем GPTNEO2.7B (Black et al., 2021), BLOOM3B (Scao et al., 2022), LLAMA7B и LLAMA7Bchat (Touvron et al., 2023), вариант с настройкой инструкций, во всех наших экспериментах. GPTNEO2.7B имеет 32 слоя и 20 головок, BLOOM3B имеет 30 слоев и 32 головки, а LLAMA7B имеет 32 слоя и 32 головки. Контрольные точки, которые мы используем, взяты из библиотеки transformers (Wolf et al., 2019).
GPTNEO обучался на The PILE (Gao et al., 2020), текстовом наборе данных объемом 825 ГБ, который состоит примерно из 98% данных на английском языке. Несмотря на то, что The PILE в основном одноязычный, он содержит Europarl, на котором GPTNEO обучался на уровне документа (а не на уровне предложения). Напротив, BLOOM обучался на корпусе ROOTS (Laurençon et al., 2022), составной коллекции из 498 наборов данных, которые были явно выбраны как многоязычные, представляющие 46 естественных языков и 13 языков программирования. Обучающие данные LLAMA в основном состоят из Common Crawl, C4, Wikipedia, Stack Exchange в качестве основных источников. Насколько нам известно, не было никаких сообщений о параллельных корпусах на уровне предложений в обучающих наборах данных этих моделей.
Данные Мы тестируем наши модели с помощью FLORES (Goyal et al., 2021) en ↔ fr, о котором мы сообщаем в основной статье, и небольшого исследования по расширению Раздела 3 до en ↔ pt в Приложении. Примеры-подсказки взяты из набора для разработки. Мы оцениваем поколения с помощью оценок BLEU, следуя реализации из Post (2018).
Формат подсказкиНаши подсказки могут состоять из инструкций, примеров, того и другого или ни одной. Важно, что мы используем нейтральные разделители, "Q:" и "A:", чтобы отделить подсказку от начала машинного текста. Это гарантирует, что модели не получат никакой информации от разделителей о том, в чем заключается задача. [1]
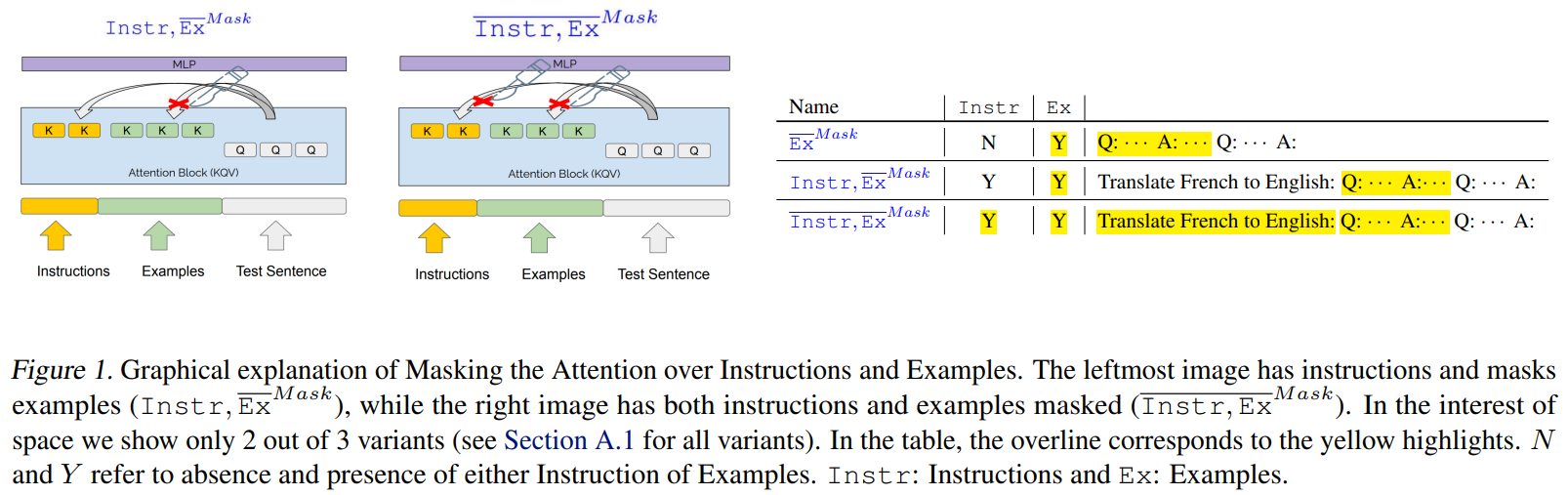
Если не используются инструкции на естественном языке, то входные данные модели будут Q: {source_sentence} A: Инструкции даются на естественном языке и имеют вид: Перевести с {L1} на {L2}: Q: {source_sentence} A:, где L1 = английский и L2 = французский, если исходный и целевой языки — английский и французский соответственно. Примеры приведены после инструкций и аналогичным образом разделены Q: и A:. См. Приложение: Таблица 1 для примера.
Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[1] В более раннем исследовании мы обнаружили, что предоставление модели только языковых индикаторов, например, «английский:», «французский:», было достаточным для того, чтобы сильные модели (llama7b, llama7b-chat) могли выполнить задачу без просмотра каких-либо инструкций или примеров в контексте.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27201)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)