

Где происходит контекстный перевод в больших языковых моделях: характеристика избыточности в Laye
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Заключение, благодарности и ссылки
- А. Приложение
4. Характеристика избыточности в слоях
Недавно Саджад и др. (2023) обнаружили, что многие слои в предварительно обученных трансформаторах могут быть удалены с небольшим ущербом для последующих задач; более того, хорошо известно, что нейронные модели трансформаторов MT имеют несколько избыточных головок, которые не нужны во время тестирования (Voita et al., 2019b; Michel et al., 2019; Behnke & Heafield, 2021). Однако неясно, сохраняются ли те же тенденции для контекстных моделей MT, и как эта избыточность связана с местоположением задачи по сравнению с ее выполнением.
Мы изучаем вклады отдельных слоев внимания, выполняя простую послойную маскировку всех головок собственного внимания для одного слоя. Когда мы маскируем слой j, мы маскируем механизм внимания слоя j, то есть MLP слоя j действует непосредственно на выход слоя j − 1, а не на выход головки внимания слоя j. Это позволяет нам изучить, насколько критичным является каждый слой, где критические слои в общих чертах определяются как те, которые оказывают большое негативное влияние при маскировке.
Мы строим графики результатов для каждого слоя всех моделей, используя три комбинации {0 примеров, нет инструкций}, {5 примеров, инструкции}, {5 примеров, нет инструкций} на рисунке 4. [3]
4.1. Являются ли «критическими» слои задачей определения местоположения слоев?
В разделе 3 мы наблюдали, что существуют слои для локализации задач. В этом разделе мы наблюдаем доказательства того, что существуют критические слои, которые соответствуют слоям локализации задач, что подтверждает наши предыдущие наблюдения.
Например, для LLAMA7B en → fr, даже в сценариях, где приведены примеры, мы можем видеть падение производительности около слоя 15–18. Возвращаясь к рисунку 2, мы видим, что именно здесь произошло большинство задач с большими скачками производительности.
Для GPTNeo мы наблюдаем большой набор смежных слоев, которые значительно снижают производительность на уровне примерно с 10 по 15. Это также соответствует месту, где для этой модели на рисунке 2 наблюдалось большинство задач (большие скачки производительности).
Мы отмечаем, что критические слои в разных моделях имеют разную степень серьезности. Не сразу понятно, почему GPTNEO имеет такие критические слои и страдает по сравнению с другими моделями, хотя мы отмечаем, что это вряд ли связано с размером или архитектурой модели, поскольку BLOOM также примерно того же размера, что и GPTNEO, и работает более похоже на LLAMA. Мы подозреваем, что это может быть связано с данными обучения или каким-то другим фактором, связанным с динамикой обучения, но оставим это для будущей работы.
Что касается избыточности, мы обнаружили, что слои можно более безопасно удалять ближе к концу без заметной потери производительности. Мы наблюдаем, что для менее стабильных моделей
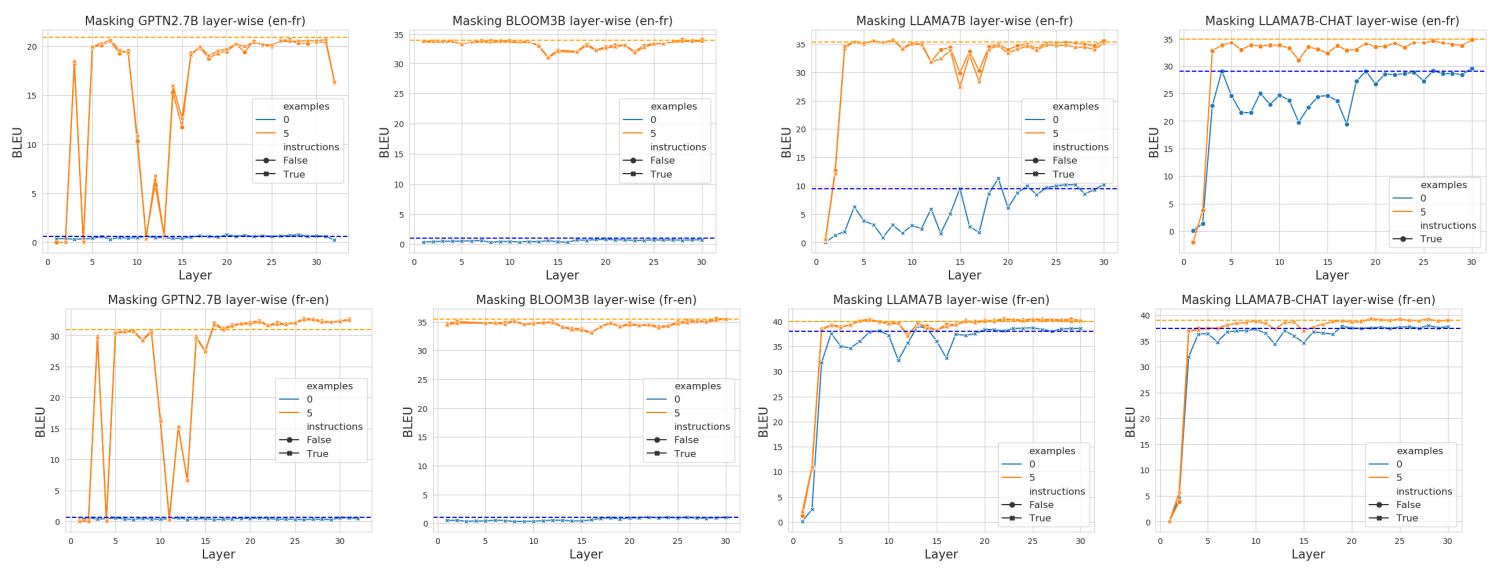
Модель достигает производительности, близкой к базовой, с помощью послойного маскирования от ℓ15 для GPTNEO, ℓ26 для BLOOM и ℓ20 для LLAMA. Это говорит о том, что эти более поздние слои содержат избыточность для перевода.
В целом, наблюдение избыточности в слоях не является удивительным, и наш главный вклад заключается в характеристике различий между избыточными и критическими слоями. Чтобы объяснить, почему модели могут иметь избыточные слои, мы ссылаемся на Кларка и др. (2019), которые идентифицируют явление, при котором головы внимания уделяют почти исключительно разделительным и разделительным токенам, таким как [SEP], точки и запятые. Считается, что это действует как «пустая операция», поскольку ценность таких токенов в изменении текущего скрытого представления очень мала. Обратите внимание, что тогда можно замаскировать целые слои Transformer и по-прежнему получать разумный вывод из-за остаточных соединений в архитектуре Transformer на каждом слое.
Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[3] Комбинация {0 примеров, нет инструкций} не имеет смысла, поскольку модель получает только «В: О:» в качестве входных данных и не должна выполнять задачу перевода.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27188)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)