

Где происходит контекстный перевод в больших языковых моделях: Приложение
2 сентября 2024 г.Авторы:
(1) Сюзанна Сиа, Университет Джонса Хопкинса;
(2) Дэвид Мюллер;
(3) Кевин Да.
Таблица ссылок
- Аннотация и 1. Фон
- 2. Данные и настройки
- 3. Где происходит контекстный машинный перевод?
- 4. Характеристика избыточности в слоях
- 5. Эффективность вывода
- 6. Дальнейший анализ
- 7. Заключение, благодарности и ссылки
- А. Приложение
А. Приложение
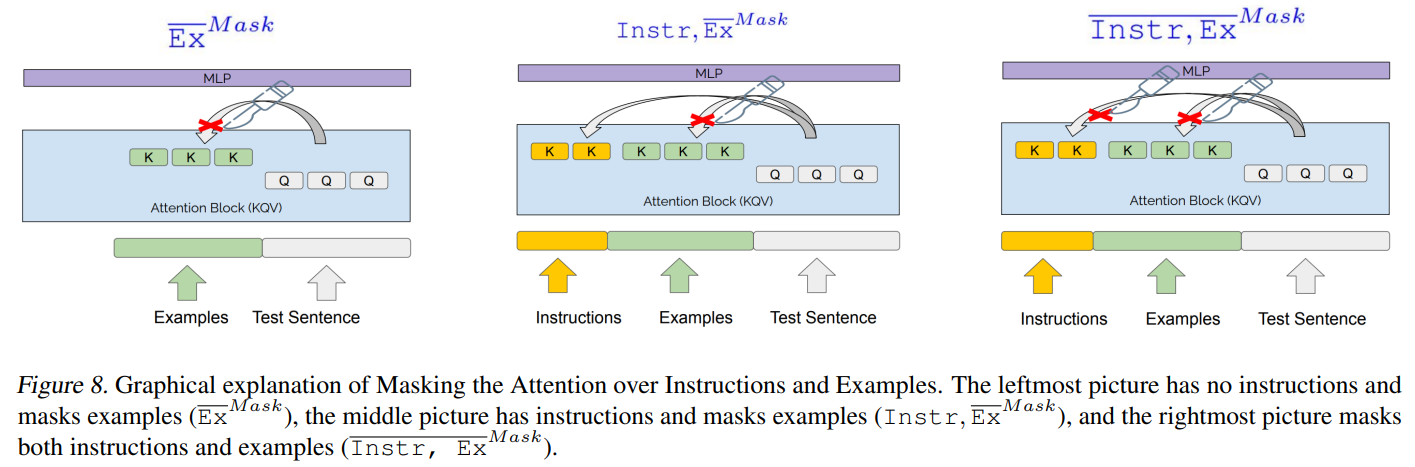
A.1. Графическое представление экспериментов по маскировке контекста
A.2. Формат подсказки
A.3. Дополнительные результаты по английскому и испанскому языкам
В дополнение к языковым парам en → fr и fr → en, мы также проводим эксперименты с английскими и испанскими языковыми парами, как en → es, так и es → en. Из-за ограничений по пространству мы представляем здесь результаты этих экспериментов. В целом, мы видим в значительной степени идентичные тенденции в обоих направлениях английского и испанского языков по сравнению с тем, что мы наблюдаем в задачах по переводу английского и французского языков, что приводит нас к выводу, что наши выводы обобщаются для различных задач по переводу.
A.4. Авторегрессивный декодер только трансформатор
Трансформатор состоит из сложенных блоков самовнимания, которые сами состоят из меньших единиц головок самовнимания, которые объединяются перед подачей через полностью связанный слой. В авторегрессионных декодерных трансформаторах обучение и вывод принимают каузальную маску, где текущие позиции могут обслуживать только предыдущие временные шаги, вместо того, чтобы обслуживать всю входную последовательность. В отличие от моделей NMT кодировщика-декодера, где исходное и целевое предложение имеют отдельные блоки обработки преобразователя, декодер-только означает, что одни и те же веса модели используются как для «кодирования» исходного предложения, так и для «декодирования» целевого предложения в одной непрерывной последовательности.
A.5. Обучение с помощью авторегрессионного перевода
Первоначальная цель моделирования языка в обучении GPT включает в себя прогнозирование всей последовательности входных токенов, которая состоит как из исходного, так и целевого предложения (смещенного на 1 позицию). Мы обнаружили, что это дает немного худшие результаты, чем только минимизация отрицательного логарифмического правдоподобия прогнозирования целевого предложения для перевода, а не всей последовательности. Мы рассматриваем это обучение авторегрессионному переводу.
A.6. Тренировка внимания L0
Подробности обучения Для раздела 6.5 мы обучаемся с помощью Adam Optimizer (β1 = 0,9, β2 = 0,999) с размером партии 32 и скоростью обучения 0,001, терпением ранней остановки 10 и порогом 0,01. Мы инициализируем ворота внимания как 1 вместо случайного или 0,5, так как это приводит к более быстрой сходимости. Мы экспериментируем с двумя различными настройками обучения: настройка обучения с 0 подсказками и настройка обучения с 5 подсказками. Как описано в разделе A.5, мы обучаем модель, предсказывая только целевое предложение, обусловленное контекстом. В настройке с 0 подсказками контекст состоит из инструкций и исходного предложения для перевода. В настройке с 5 подсказками контекст состоит из инструкций, 5 примеров подсказок и исходного предложения для перевода.
В настройке 0-prompt условный префикс состоит из инструкций и исходного предложения для перевода. В настройке 5-prompt условный префикс состоит из инструкции, 5 пар исходных целевых предложений и исходного предложения для перевода.
ДанныеМы использовали первые 10 000 строк en → fr из WMT06 Europarl (Koehn, 2005) для обучения.[7] Чтобы проверить обобщаемость обученных ворот внимания, мы используем другой тестовый домен, FLORES (Goyal et al., 2021), чтобы отразить дефицит данных в домене. Мы также тестируем дополнительное языковое направление en→pt в FLORES, чтобы увидеть, может ли обучение обобщаться между языками.
Подробности обученияМы обучаемся с помощью Adam Optimizer (β1 = 0,9, β2 = 0,999) с размером партии 32 и скоростью обучения 0,001. Мы используем большое терпение ранней остановки 10 и порог 0,01 и обучаемся до 100 эпох. Это связано с природой обучения L0; мы не ожидаем улучшения производительности за много итераций и хотели бы, чтобы шлюзы внимания продолжали обучение до тех пор, пока не будет большой потери производительности. Мы инициализируем шлюзы внимания как 1 вместо случайных или 0,5, так как это приводит к гораздо более быстрой сходимости и лучшей производительности. Для веса регуляризации λ мы ищем по набору гиперпараметров {0,1, 0,01, 0,001, 0,0001} и обнаружили, что 0,01 работает лучше всего на проверочном наборе.
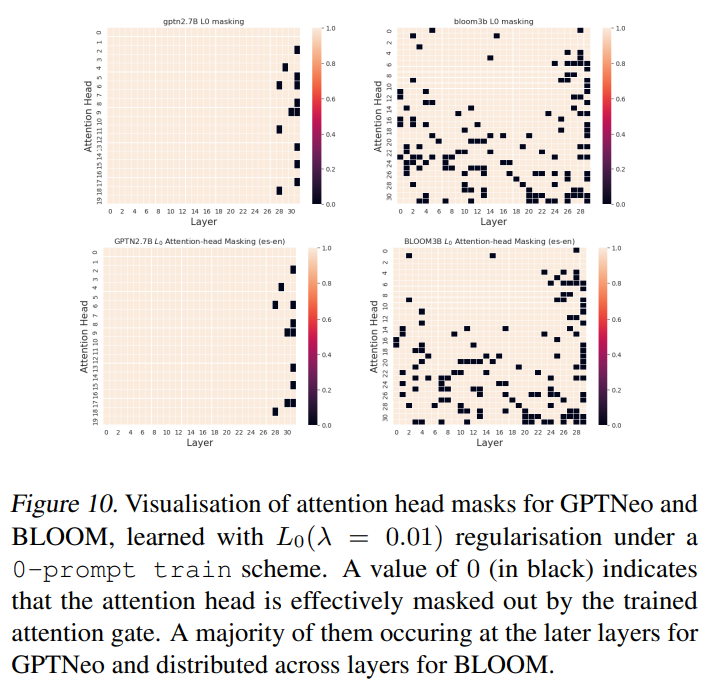
А.7. Эксперименты с маскировкой головы L0.
Дополнительные эксперименты по маскировке головы L0 в направлениях fr→ en и es→ en.
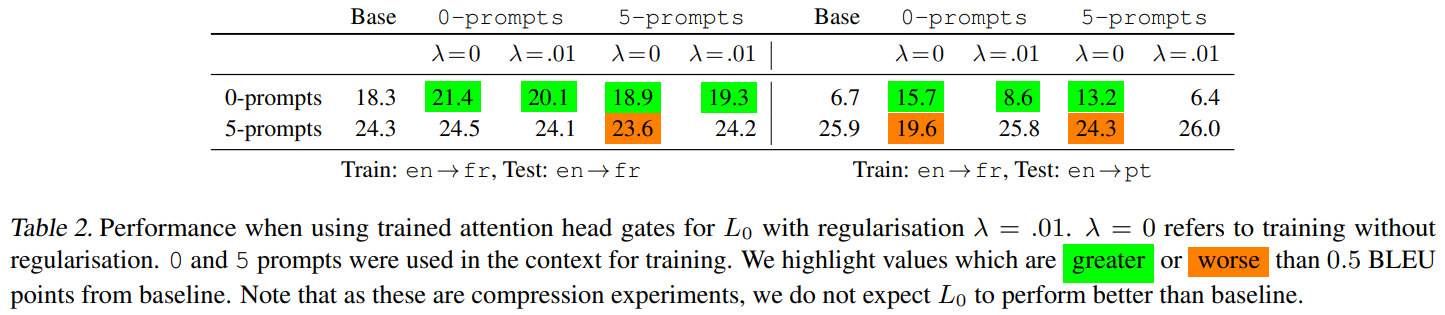
A.8. Обобщенность обучения L0-ворот
Мы экспериментируем с 0-подсказками и 5-подсказками в обучении и используем λ = 0 (без регуляризации) и λ = 0,01. Обучение L0 для 0-подсказок показывает некоторые улучшения для тестового случая с 0-подсказками и без потерь для тестового случая с 5-подсказками (таблица 2). Примечательно, что это сохраняется в en→pt, другом языковом направлении от обучения.
Надежность производительности перевода в условиях множественного тестирования (количество подсказок, наборы данных, языковые указания) дает некоторую уверенность в том, что обученные дискретные шлюзы внимания из L0 поддерживают общую способность переводить (таблица 2). Напротив, мягкие шлюзы внимания без регуляризации (λ = 0) кажутся переобученными, поскольку они хорошо работают в одних условиях, но ухудшаются в других.
Мы наблюдаем, что 0-подсказочное обучение для L0(λ = 0,01) также

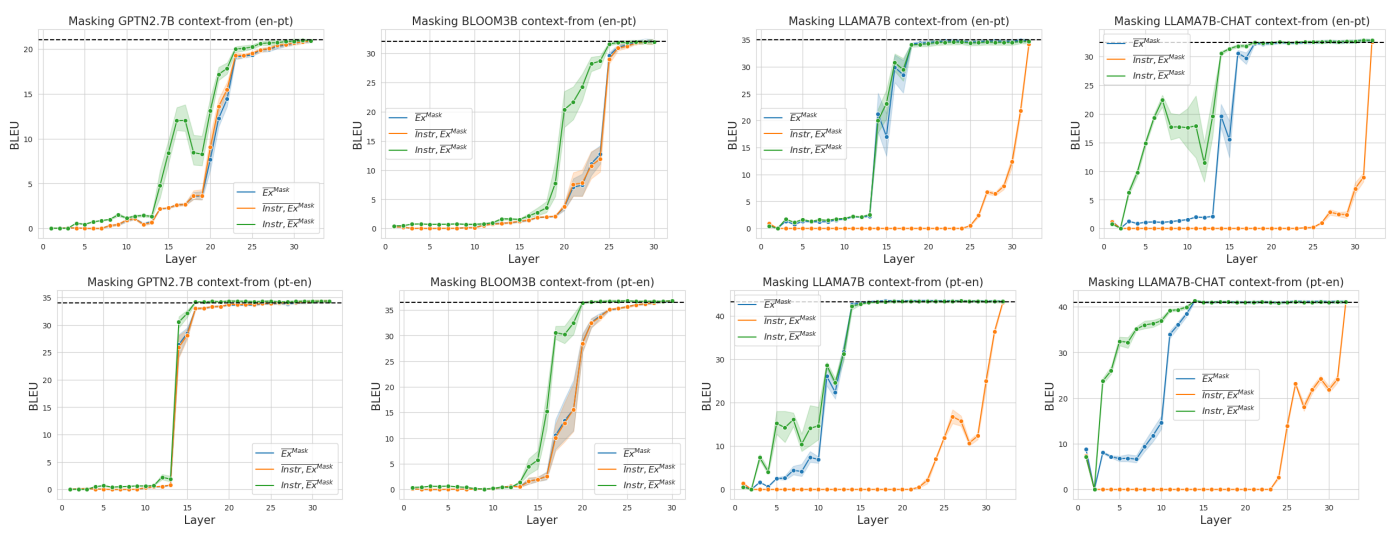
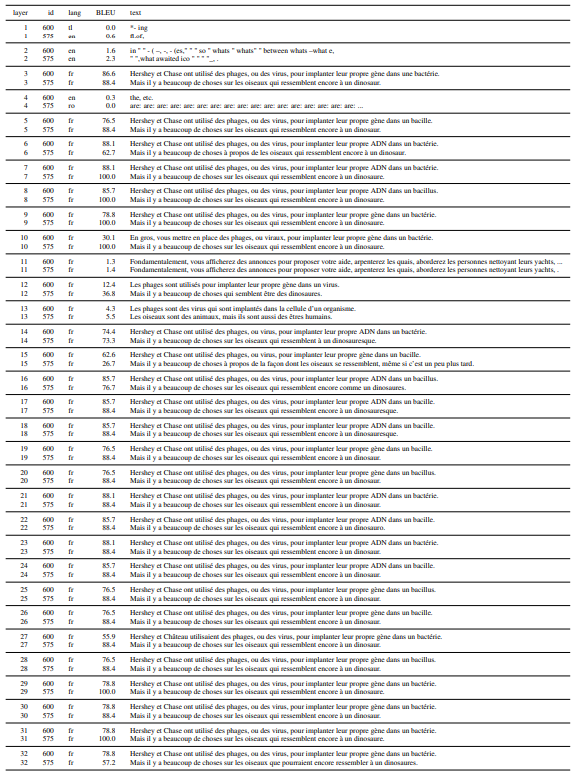
A.9 Качественный анализ послойного маскирования

ЦВЕСТИнаблюдается большая устойчивость к маскированию слоев; это говорит о том, что местоположение задач более распределено.
Для настройки с 5 подсказками производительность снижается лишь незначительно. Для настройки с 0 подсказками мы наблюдаем, что, как и в случае с GPTNEO, производительность падает при маскировании средних слоев. На совокупном уровне BLOOM, похоже, все еще переводит (> 0 BLEU), даже когда слои маскируются. Однако мы наблюдаем, что падение производительности связано с тем, что около 40–50 % тестовых предложений набрали < 5 баллов BLEU. Налицо явная неудача в переводе, а не просто худшие переводы.



Эта статьядоступно на arxivпо лицензии CC BY 4.0 DEED.
[7] Данные доступны по адресу https://www.statmt.org/europarl/
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27385)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)