

Что могут рекуррентные нейронные сети в НЛП?
16 апреля 2022 г.Надеюсь, вы уже знакомы с основами рекуррентных нейронных сетей (RNN). Если нет, не стесняйтесь ссылаться на [эту статью] (https://medium.com/mlearning-ai/introduction-to-recurrent-neural-networks-f8615c113019). В обработке естественного языка (NLP) RNN сыграли важную роль в моделировании последовательности. Давайте посмотрим, на что способны RNN и каковы их слабые места. Не углубляясь в тему, давайте потихоньку!
В RNN мы подаем выходные данные предыдущего временного шага в качестве входных данных для следующего временного шага. Мы обнаружили, что они хорошо работают с последовательной информацией, такой как предложения.
Для наглядности посмотрите на пример ниже:
Если мы рассмотрим пример предсказания следующего слова на основе предыдущих слов в предложении с использованием RNN, на изображении ниже показано, как RNN ведет себя на каждом временном шаге. Все скрытое состояние изображается прямоугольником желтого цвета.
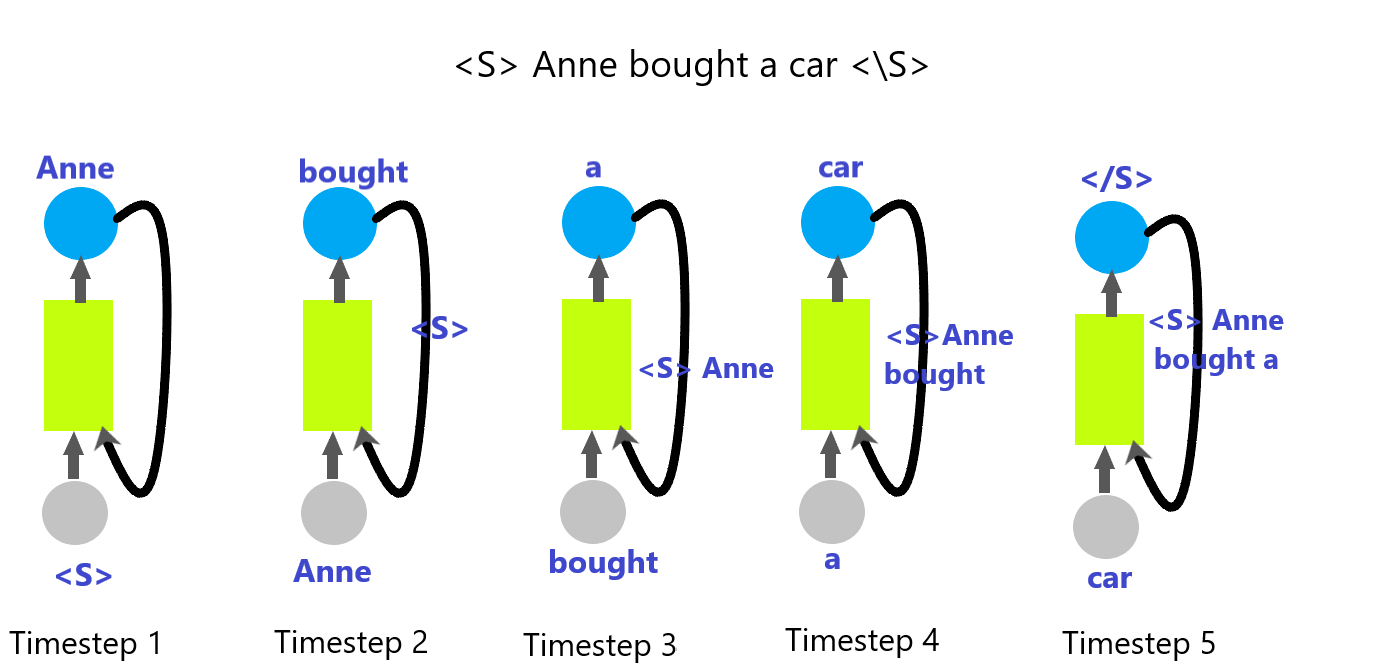
Вы можете видеть, что, наконец, скрытое состояние содержит краткое изложение предложения.
Так соединяются нейроны и появляется RNN.
![Рекуррентная нейронная сеть для данного примера — изображение Русири Иллесингхе] (https://cdn.hackernoon.com/images/eYWkxDqBywhhLUv1HmIFB7KBZKx1-4ec3klk.png)
Но на каждом временном шаге у них есть индивидуальные потери. (Вы можете суммировать их вместе, чтобы получить единое значение потерь).
Если рассматривать обратное распространение, в RNN у нас есть дополнительный параметр, называемый «время», отличный от матрицы весов. Временной шаг 5 будет распространять градиент обычным образом. На временном шаге 4 мы также должны учитывать градиент временного шага 5. На временном шаге 3 мы должны учитывать градиенты всех временных шагов от последнего временного шага.
Таким образом, при обратном распространении RNN для временного шага r мы должны распространить градиенты последнего временного шага на временной шаг r-1.
Что вы могли увидеть из вышеизложенного?
✔ Вместо того, чтобы использовать одно или два предыдущих слова для предсказания следующего слова в предложении, этот подход сохраняет зависимость!
Рассматривая только предыдущее слово, например, «а» в приведенном выше контексте, нейронная сеть может иметь много возможностей для предсказания: река, студент, машина и т. д. (Возможности зависят от слов в ее «корпусе»).
Но в этом подходе, основанном на RNN, у нас есть последовательность «Энн купила», чтобы предсказать следующее слово. Так что теперь вероятность того, что следующим словом станет «река» или «студент», очень мала.
Это важный результат, который можно получить с помощью RNN.
Итак, что не так? Просто вспомните теоретический материал, который я только что объяснил на примере.
- Распад информации: Хотя мы обсуждаем, что RNN запоминает предыдущее содержимое, все внутренние выполнения происходят в математически ограниченных средах. Выход скрытого слоя — это вектор максимального размера. Так что, когда информация превышает этот размер, RNN начинает забывать материал. Это происходит на дальних дистанциях. Например, если вы посмотрите на данный пример, на временном шаге 2 в скрытом состоянии не было слова для запоминания, на временном шаге 2 это было только одно слово. Но на шаге 5 у него было 4 слова. Если это превышает емкость выходного вектора, информация будет распадаться.
- Исчезающий градиент: В процессе обратного распространения, если градиент функции активации имеет значение от 0 до 1 (пример: 0,3), градиенты последних временных шагов будут многократно умножаться на это значение. (Для понимания просто возьмите градиент последнего временного шага за 1 и на временных шагах 4,3,2,1 умножьте его на градиент функции активации (0,3): 1 x 0,3 x 0,3 x 0,3 x 0,3 = 0,0081. Итак, теперь вы можете понять, что в более длинной последовательности он может достигать 0. Градиент на время исчезает!
- Взрывной градиент : Это противоположность исчезающему градиенту. Просто представьте градиент вашей функции активации как 4,75 и градиент последнего временного шага как 1 . Что происходит при обратном распространении более 4 временных шагов? 1 х 4,75 х 4,75 х 4,75 х 4,75 = 509,06. Градиент быстро растет со временем и в настоящее время может иметь очень большое значение. Если последовательность очень велика, градиент может выйти за пределы диапазона значений используемого типа данных, и значение может быть помечено как «NaN», что сделает всю работу беспорядочной!
На данный момент была введена LSTM (долговременная кратковременная память), которая способна устранить подводные камни RNN!
Главное изображение от chenspec с Pixabay
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27399)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)