

Мы перенесли 250 микросервисов в Kubernetes без простоев
17 ноября 2022 г.Здравствуйте, меня зовут Август Вилакиа
Я работаю старшим инженером-программистом в Альфа-Банке уже более года, работая над серверной частью мобильного приложения. Так почему же я говорю о переносе микросервисов с одной контейнерной платформы оркестрации на другую?
В АльфаБанке любому разработчику, который хочет заниматься чем-то другим, кроме бизнес-задач, разрешено тратить 20% своего времени на задачи инфраструктуры.
План:
- Почему мы решили переехать?
- С какими проблемами мы столкнулись и как мы их решили?
- Как организовать параллельную разработку и тестирование с помощью Istio?
Наше мобильное приложение насчитывает 5 миллионов пользователей в день и более 250 микросервисов.
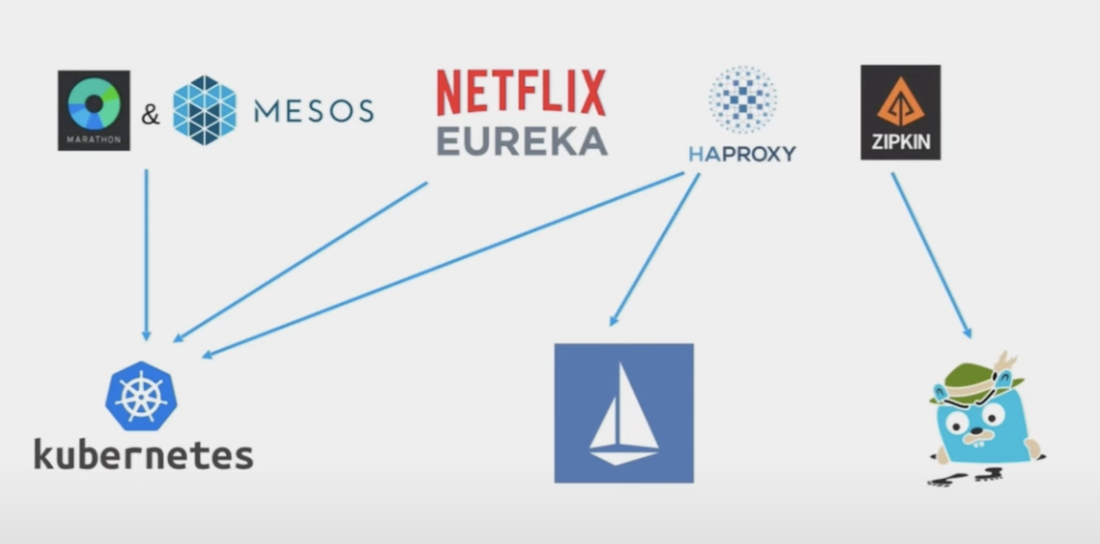
Весь наш кластер был сформирован в Месосе. Mesos — это менеджер кластера, который поддерживает другую нагрузку. Основа нашей архитектуры, хозяева и рабы Месоса, организованные Марафоном. Почти так же, как и в Kubernetes, приложение работает в Kubernetes, но с небольшими отличиями в организации кластера.
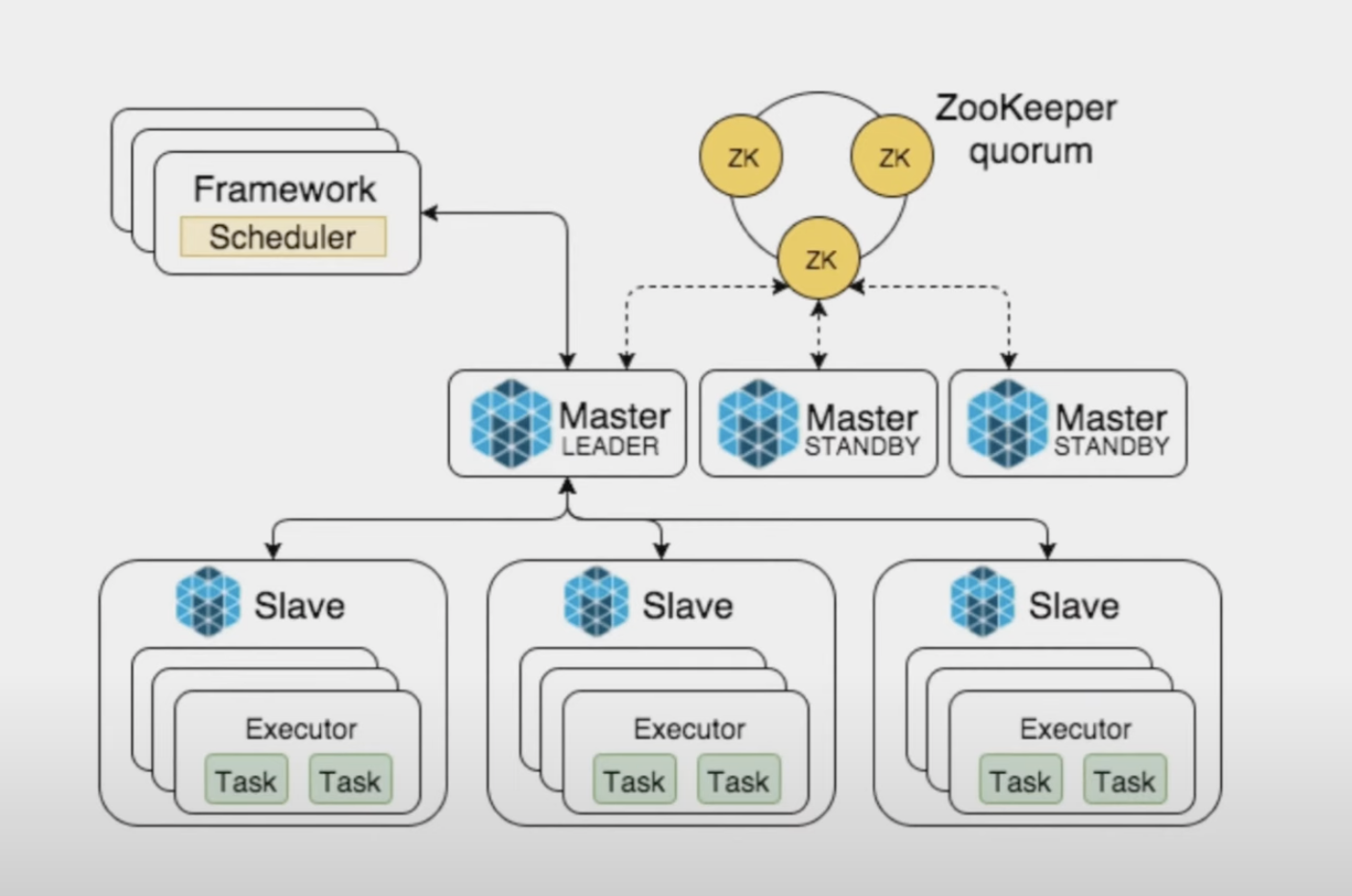
Выбор, куда переехать, был очевиден. Все слышали о Kubernetes и перешли на него давным-давно.
Причины, по которым мы решили переехать:
- Последний выпуск Mesos был выпущен 12 декабря 2019 г.
- Kubernetes стал слишком популярным и стал стандартом оркестровки, что упростило поиск разработчиков, которые что-то знают о k8s.
- Отказ от Netflix Eureka, который использовался в качестве Service Discovery.
- Удалите код, не связанный с бизнес-логикой (например, трассировку и т. д.)
- Сервисной сетке требовался способ управления тем, как разные части приложения обмениваются данными друг с другом.
Кроме того, у нас были проблемы с Mesos. Однажды у всех сервисов начались проблемы с тайм-аутами безо всякой причины.
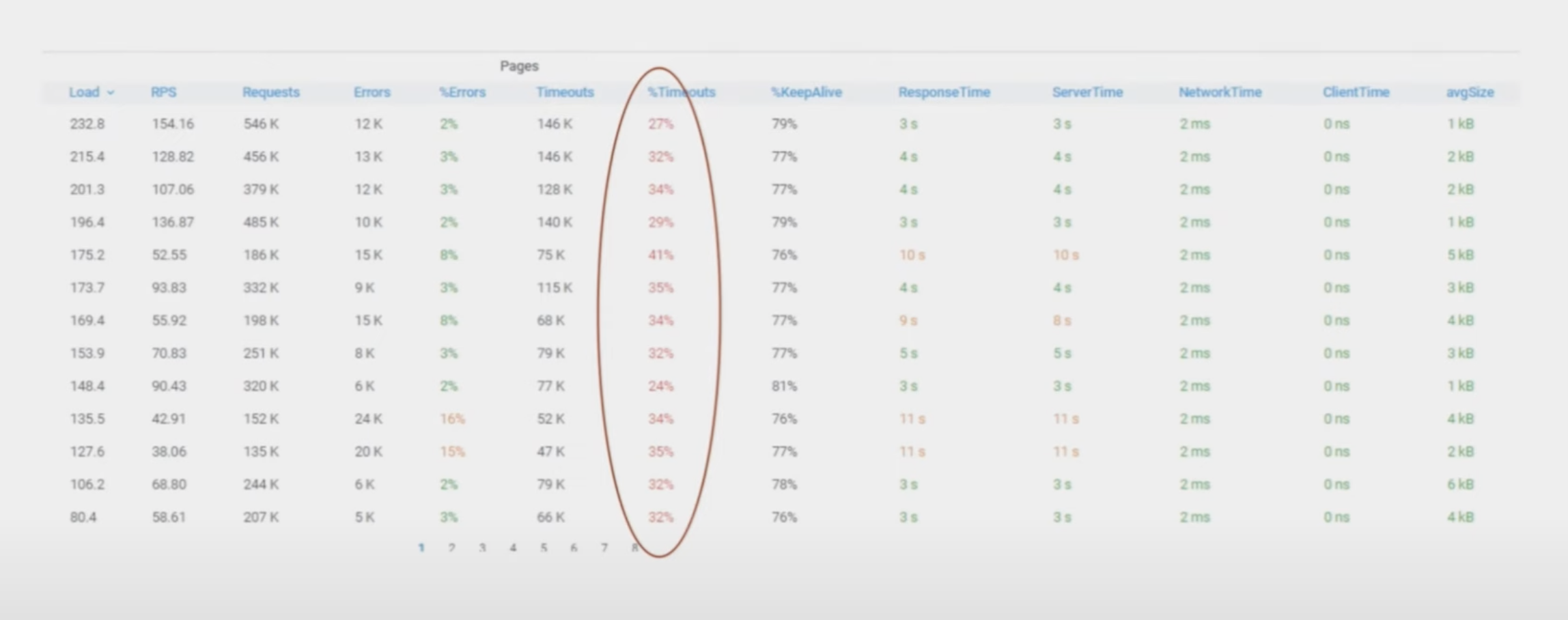
Мы не знали, что делать!!!

Затем мы заметили, что на некоторых хостах нагрузка на ЦП была очень высокой
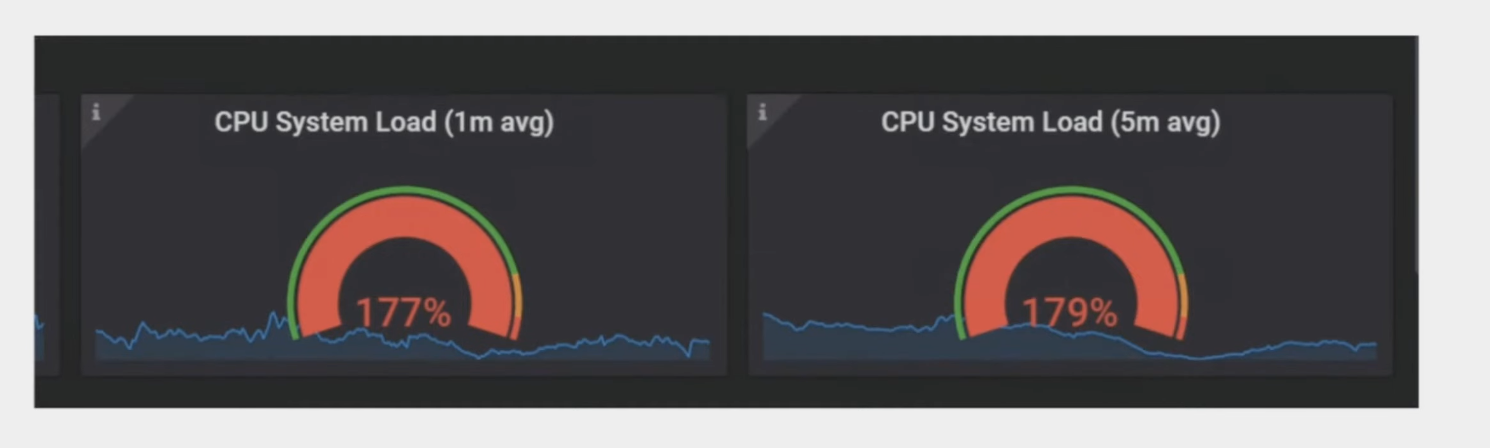
:::подсказка Давайте сначала объясним загрузку процессора. Загрузка ЦП — это количество процессов, которые выполняются ЦП или ожидают выполнения ЦП. Таким образом, средняя загрузка ЦП — это среднее количество процессов, которые выполняются или ожидают выполнения за последние 1, 5 и 15 минут.
:::
Выяснилось, что старые хосты были удалены из ДЦ, а новые поставлены, и оказалось, что у Mesos нет механизма ребалансировки ресурсов.
Как Kubernetes решает эту проблему?
- Он использует проверки живости, готовности + Scheduler, чтобы узнать текущее состояние контейнера.
- Сходство и анти-сходство Pod организует микросервисы по хостам.
- HorizontalPodAutoscaler проверит текущую нагрузку и масштабирует ее. Descheduler — дополнительный модуль, который удаляет модули с узлов с помощью различных настраиваемых политик, а затем Scheduler распределяет модули.
Следующая проблема заключалась в том, что при развертывании служб мы обнаружили ошибку 503, хотя все проверки работоспособности были пройдены. Как будто кто-то удалил маршруты. Но, через 1-2 минуты все было в порядке. Возможно, наша конфигурация была слишком большой или что-то не так с шиной событий, которая запускала обновления.
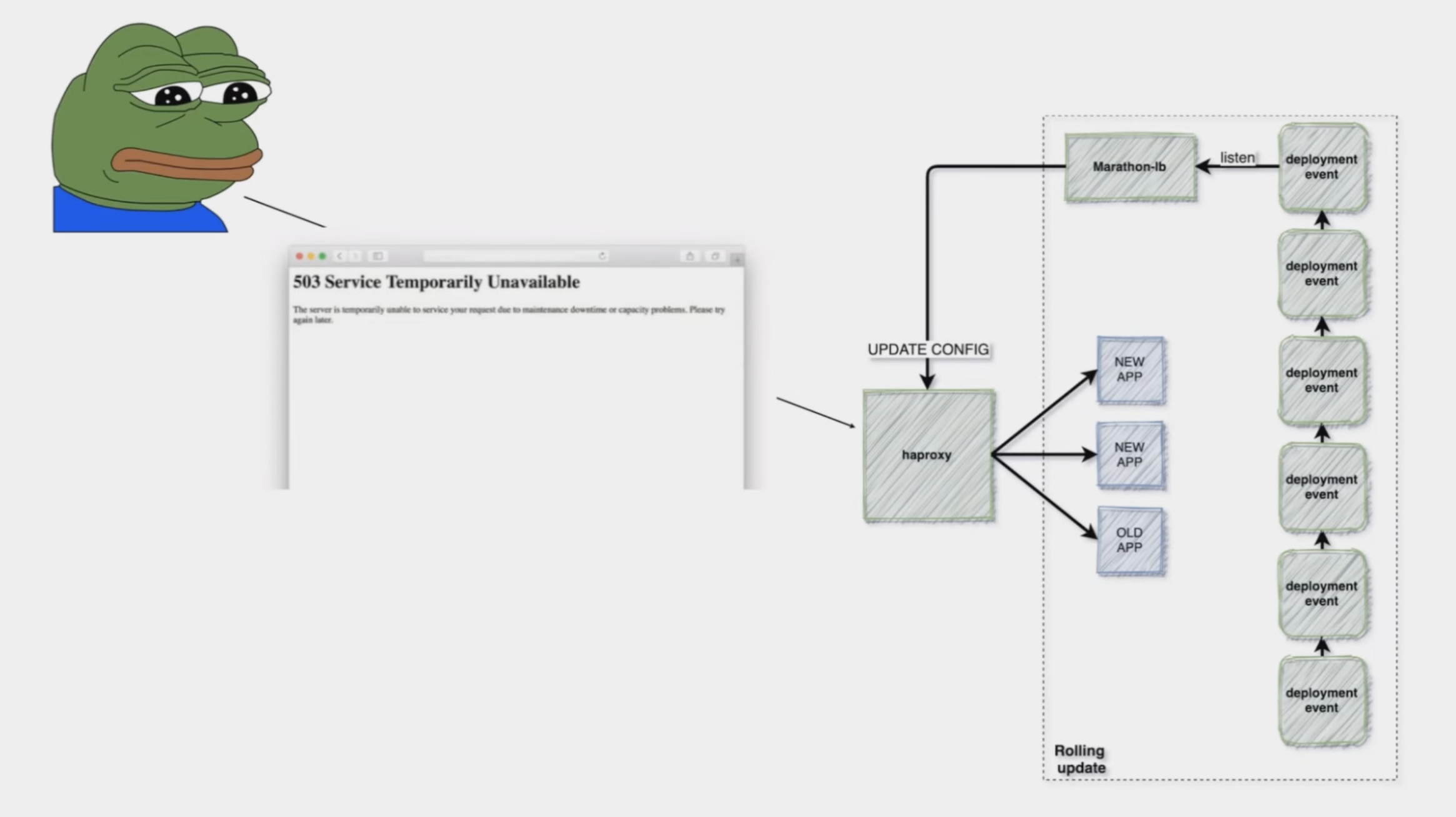
Какие трудности возникли при переходе на Kubernetes?
Адская зависимость от сервисов, все зависело друг от друга и работало как единое целое
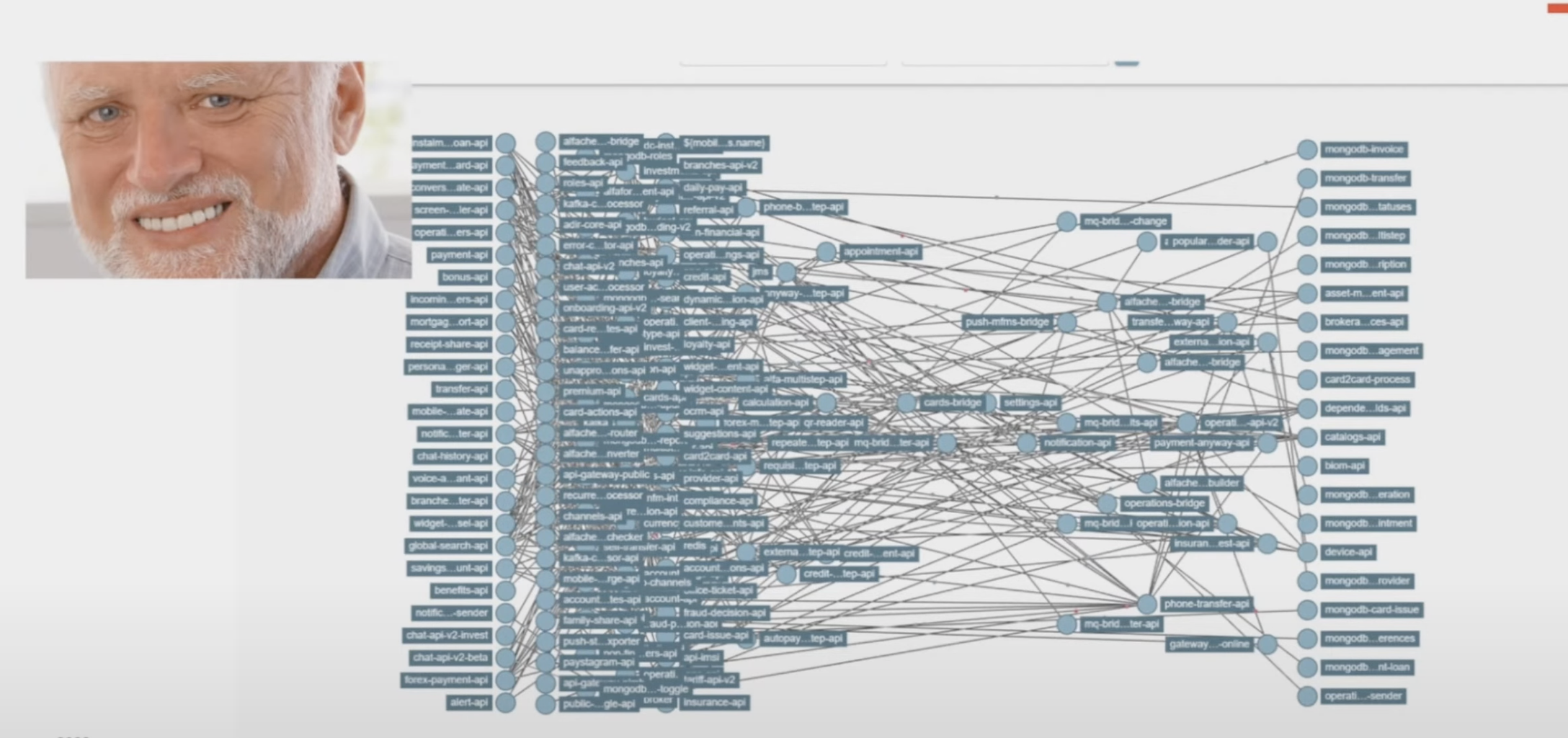
Итак, как двигаться без простоев? Сделать дополнительный кластер, переместить туда все и потом просто перенаправить трафик. Решили разделить трафик с помощью Headers и load balance traffic и, если сервис работает нормально, увеличить нагрузку до k8s. После перевода 100% трафика на k8s отключаем сервис в Mesos.
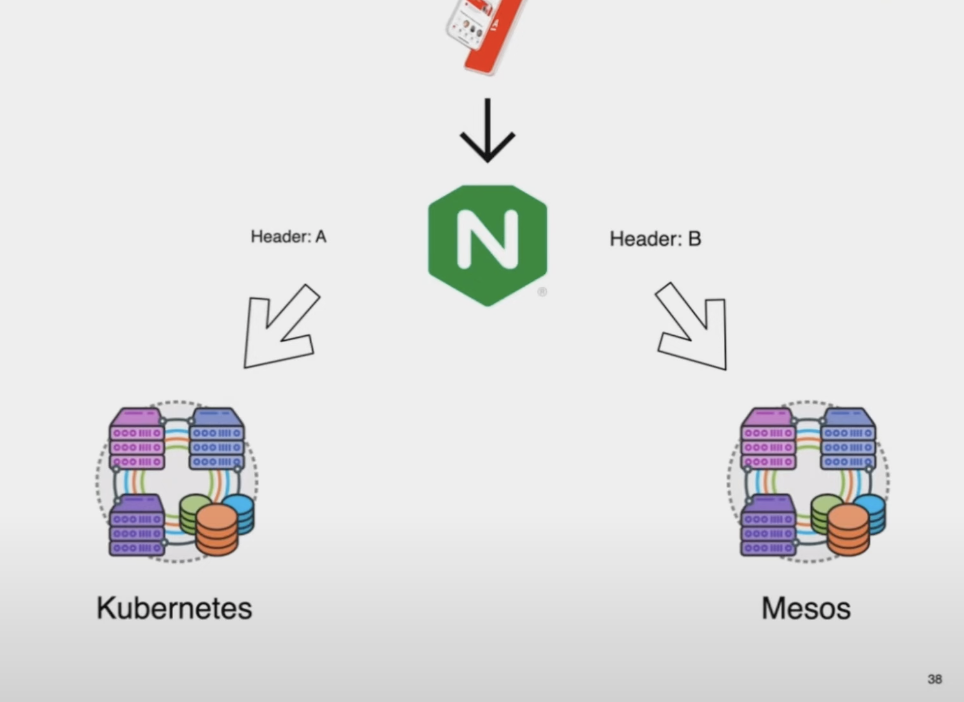
В наших кластерах использовалось другое обнаружение служб, поэтому они не могли найти своих фиктивных клиентов в другом кластере. Мы не хотели иметь в репозитории несколько веток, зависящих от оркестратора. Мы также решили не использовать определенные зависимости, потому что нам нужно будет предоставить доступ к Kubernetes API.

У нас есть Spring Starter с каждым клиентом feigns, поэтому мы добавили их специальный bean-компонент с условием запуска контекста приложения. Этот bean-компонент проверяет каждого клиента и добавляет параметр URL, если eureka отключена или eureka отсутствует в пути класса.

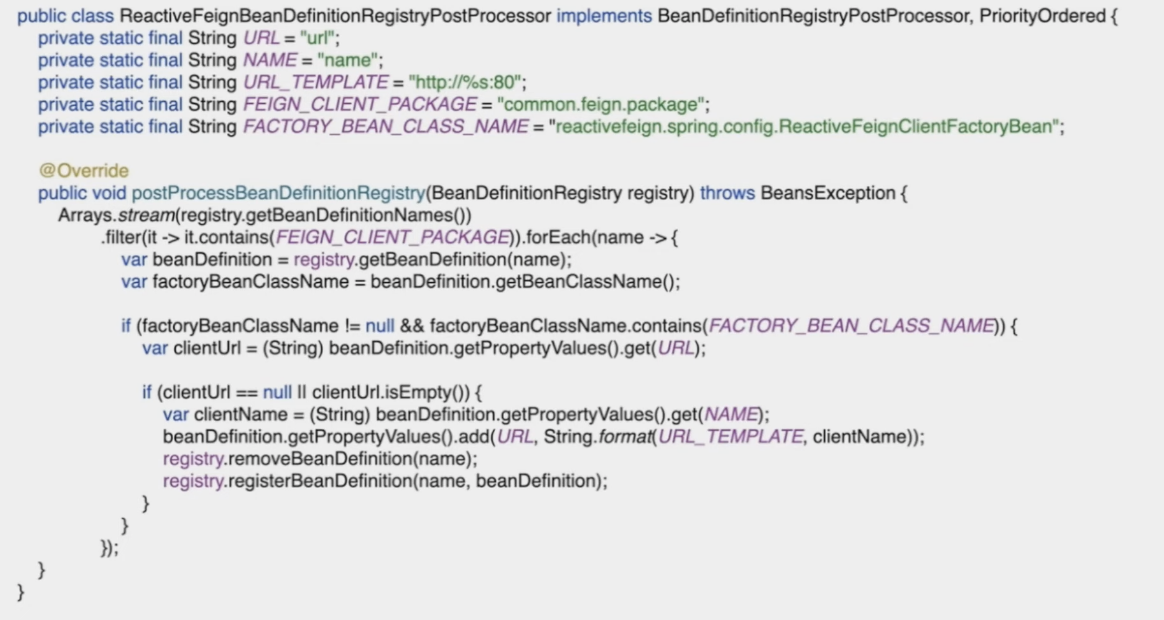
Мы извлекаем каждое определение Bean с помощью Factory Bean. В нашем случае это ReactiveFeignClientFactoryBean. После этого нам нужно получить параметр clientUrl и с помощью String.format() изменить его в соответствии с Kubernetes. Проблема решена.
Как организовать параллельную разработку и тестирование с помощью Istio?
Проблемы возникают, когда много команд разрабатывают и некоторые команды меняют схожие функции, поэтому они создают общую ветку, наблюдая за тем, когда другая команда заканчивает работу, а QA тоже не может правильно протестировать. Несколько стендов для разработки/тестирования обходятся дорого, так что же делать? Нам помогло управление трафиком Istio. Istio — это сервисная сетка, используемая поверх бизнес-сервисов для шифрования, трассировки и канареечного развертывания. Практически каждый бизнес-сервис имеет дополнительный прокси-сервис, который перехватывает трафик и что-то с ним делает. Он использует виртуальную службу (которую можно использовать для описания всех свойств трафика соответствующих хостов, в том числе для нескольких портов HTTP и TCP), а также определяет, куда отправлять трафик и правила назначения для разделения трафика.
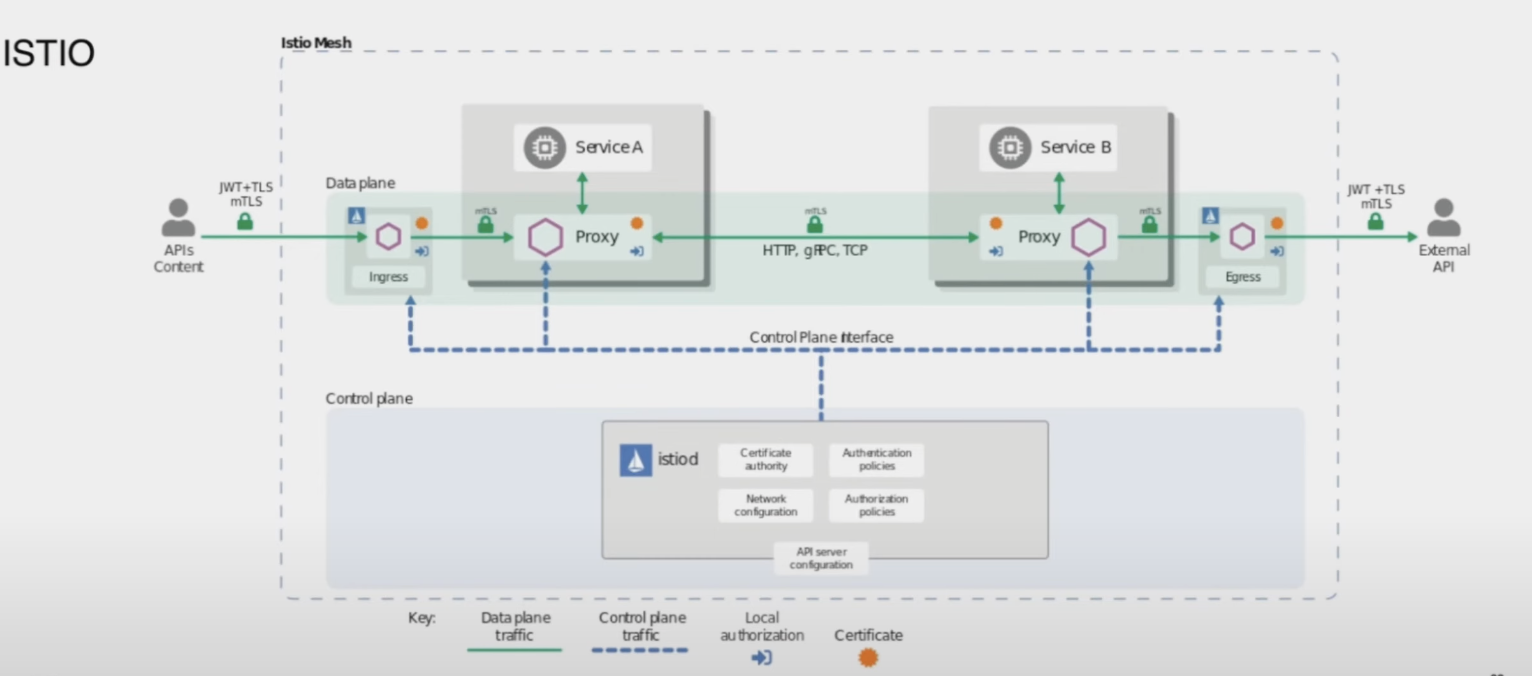
Всем доволен, все работает)). Как было и как есть, верхняя часть "до" и нижняя часть фото "после". Теперь наш стек инфраструктуры — это Kubernetes, Istio и Fluentbit.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
20 самых популярных статей TechRepublic в 2023 году
23 декабря 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27702)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)