
Мы создали современный стек данных для стартапов
27 апреля 2022 г.В настоящее время легкий доступ к данным является ставкой для высокоэффективных компаний.
Однако легкий доступ не предоставляется бесплатно: он требует инвестиций и тщательного выбора инструментов. Для таких молодых компаний, как мы, вопрос в том, сколько? И когда вы делаете эти инвестиции?
Когда мы выросли до десяти человек, некоторые из которых не имели инженерного образования, но нуждались в больших данных, мы решили, что 2022 год настанет этим временем.
Спустя две недели экспериментов и пару корпоративных семинаров мы очень довольны тем, что у нас получилось. Если вы представляете компанию со схожими потребностями и заботитесь о доступе к данным для всех, следуйте этому руководству, и мы гарантируем, что вы получите отличный результат.
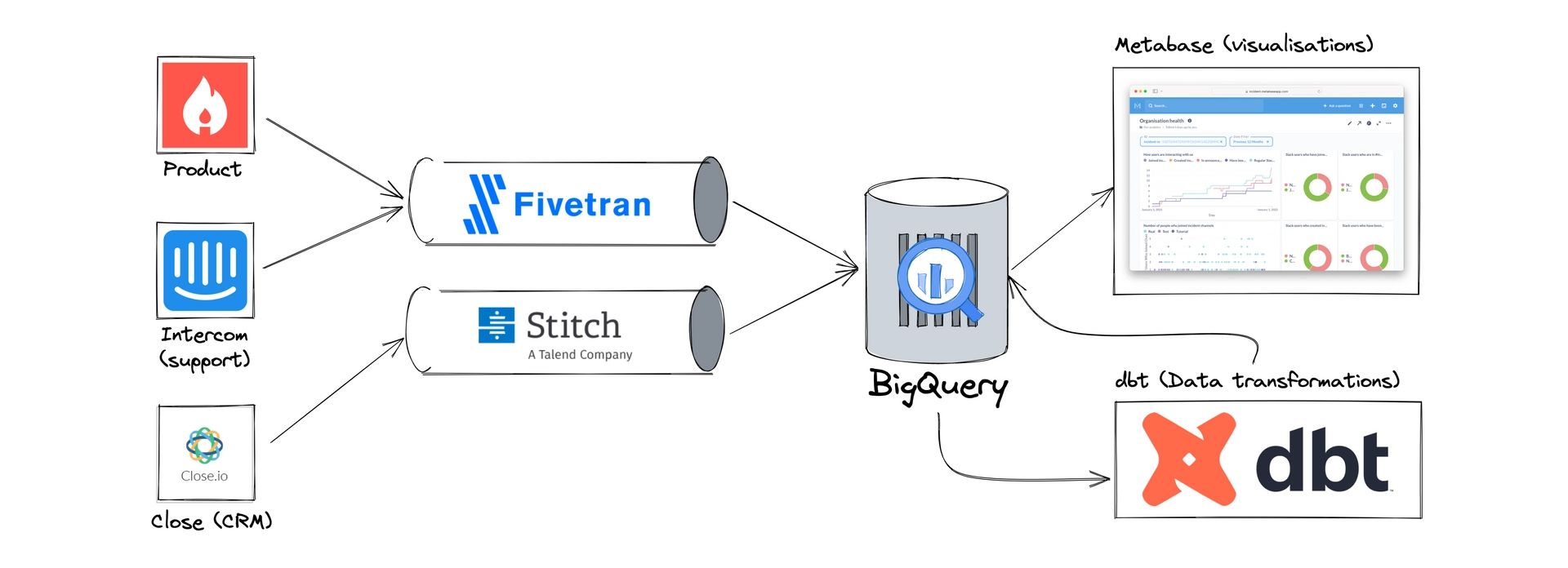
Обзор архитектуры
С помощью решений для хранилища данных (BigQuery, Snowflake, Redshift) становится мейнстримом, современные стеки данных становятся все более скучными — отличные новости, если вы начинаете с нуля!
В общем, вы хотите:
- Извлечение данных из различных инструментов (вашей CRM, бухгалтерской платформы и т. д.) в хранилище данных
- Выполните очистку и преобразование данных в исходных наборах данных
- Найдите инструмент визуализации, который может использовать хранилище для исследования и понимания
Найти дополнительные инструменты сложно, и мы поговорили с инженерами по данным из нескольких компаний, чтобы выяснить, что у них работает (а что нет). Мы пришли к следующему стеку:

Слева вы увидите источники данных (только образец, у нас их гораздо больше), инструменты, с помощью которых мы генерируем данные и работаем с ними. Одним из них является Product, база данных Postgres, на которой основан инцидент.io, а Intercom и Close являются SaaS мы используем для ведения нашего бизнеса.
Fivetran и Stitch – это инструменты ETL, предназначенные для передачи данных из различных источников в места назначения. Мы используем оба для загрузки данных в BigQuery, наше хранилище данных.
В BigQuery мы очищаем и преобразовываем данные с помощью инструмента dbt. Это позволяет нам преобразовать необработанные исходные данные в идеальный формат «собственного хранилища данных», который можно легко использовать для анализа.
Наконец, Метабаза предоставляет уровень визуализации и аналитики, выполняющий запросы к BigQuery.
Вот и все, весь стек данных. Мы думаем, что эти инструменты — это все, что нам нужно для того, чтобы Incident.io превратилась в гораздо более крупную компанию, и, учитывая, что одной из наших целей (всегда, во всем!) является простота, мы рады, что список такой маленький.
Давайте более подробно рассмотрим, как это работает.
Извлечение: Fivetran и Stitch
Современные компании производят огромное количество данных с помощью все большего числа инструментов.
Хотя каждый инструмент предоставляет индивидуальное представление своих данных, я сильно верю в то, что объединение наборов данных раскрывает большую ценность, чем сумма их частей. Мы делаем это, объединяя наши данные в единое хранилище, что означает, что мы можем запрашивать все наши инструменты и получать информацию, которая объединяет данные интересными способами.
Раньше компании писали свои собственные хакерские скрипты для выполнения этого извлечения — в прошлом у меня были ужасные инциденты, вызванные триггерами базы данных ETL, и даже [создали несколько] (https://github.com/lawrencejones /pgsink) универсальные инструменты ETL.
Исходя из опыта, поверьте мне, когда я говорю, что вы не хотите их строить. К счастью, продукты ETL, такие как Fivetran и Stitch, запускают и поддерживают эти процессы извлечения для вас.
И в Fivetran, и в Stitch процесс одинаков:
- Выберите соединитель для доступа к исходным данным (ваша база данных Postgres или CRM)
- Настройте его с аутентификацией и выберите, какие данные синхронизировать
- Поместите данные в хранилище, обычно в наборе данных, специфичном для источника.
Вот вид разъемов, которые мы настроили в Fivetran:
!)
Стоит отметить разнообразие источников. Если вы создаете продукт SaaS, одним из наиболее важных источников данных будет любая база данных, на которой работает ваш продукт. incident.io есть монолитное приложение на базе Postgres, в котором мы храним такие таблицы, как:
- «Организации», строка для каждой организации, использующей продукт
users, каждый пользователь для организации
инциденты, каждый инцидент управляется в продукте
Эти данные буквально являются нашим продуктом, и ваш эквивалент, вероятно, является наиболее ценным активом данных, который можно разместить в вашем хранилище.
Ваша база данных будет ограничивать возможности репликации этих данных, но Fivetran предоставляет коннекторы, которые охватывают большинство случаев — например, наш Heroku Postgres не поддерживает логическую репликацию, поэтому Fivetran возвращается к периодическому сканированию таблиц и использованию xmin в качестве курсора вместо чтения WAL.
Fivetran будет автоматически управлять схемой хранилища от вашего имени, создавая таблицы в целевом наборе данных для каждой таблицы в источнике. В качестве примера, вот наборы данных BigQuery из нашей производственной базы данных:

Другие источники данных, такие как ваша CRM, будут получать доступ к этому инструменту через API. Для этих соединителей Fivetran будет разбивать ресурсы API на страницы, используя курсор, который устанавливается при каждом запуске, принимая эти ответы и отправляя их в пункт назначения.
Ожидайте, что эти данные будут низкого качества или их будет неудобно использовать без дополнительных усилий. Перевод ресурсов API в формат хранилища данных требует некоторых человеческих усилий, и именно здесь начинается наш шаг преобразования.
Почему два инструмента?
До сих пор вы, вероятно, задавались вопросом, почему у нас есть два инструмента ETL. Fivetran выглядит великолепно, разве мы не можем использовать его?
Ответ: мы хотели бы, поскольку Fivetran был исключительным там, где мы могли его использовать, и цены потрясающие - я думаю, что наш счет составляет около 100 долларов в месяц за все эти разъемы, что является выгодной сделкой для значение, которое мы получаем от него.
Однако мы ограничены доступностью разъемов. Stitch — продукт, аналогичный Fivetran, но основанный на открытом исходном коде Singer project — огромной коллекции сборов данных (источников) и целей (назначений).
Используя Singer в качестве базовой технологии, Stitch предлагает более полный набор разъемов, чем Fivetran. Из двух инструментов только Stitch поддерживает Close (наша CRM), что означает, что мы вынуждены использовать оба продукта, хотя бы для одного коннектора.
Помимо неудобств, я не думаю, что это плохая стратегия. Цель инструментов ETL — доставить ваши данные в хранилище, и при условии, что это происходит надежным образом, не должно иметь большого значения, как они туда попали.
По этой причине наша политика такова: «Предпочитаю Fivetran, а не Stitch». Это работает для нас!
Преобразование: дбт
Теперь у нас есть данные в хранилище, нам нужно преобразовать их в соответствующую форму для запросов и анализа. Это означает превращение необработанных исходных данных в узнаваемые бизнес-концепции, а также очистку артефактов процесса ETL (удаление удаленных строк и т. д.).
Очевидно, что на данном этапе есть правильный выбор инструментов: dbt. Создав огромное сообщество заядлых инженеров по обработке данных, dbt представляет собой решение для работы с хранилищами данных, и оно должно быть совместимо с остальной отраслью.
Хотя выбор инструмента очевиден, вопрос о том, как использовать dbt, будет более спорным. Существует множество отличных ресурсов на передовом опыте работы с dbt, но, как видно из моих вопросов Slack, здесь достаточно двусмысленности, чтобы связать вас.
Мы пришли к структуре, которая сводит к минимуму количество моделей dbt (и их файлов схем, что является реальным бременем обслуживания) и классифицирует таблицы по качеству и предполагаемому использованию.
Нижеследующее взято из нашего руководства «Введение в данные»:
Какие данные следует использовать?
Не все данные созданы одинаковыми, и полезно понимать различные типы моделей, которые вы можете запрашивать из метабазы, чтобы использовать их наилучшим образом.
Во-первых, мы ожидаем, что люди будут запрашивать данные, которые мы получаем из dbt. Все таблицы, созданные dbt, находятся в наборе данных All (dbt) в метабазе.
Этот набор данных содержит много таблиц, и каждая таблица будет:
- Размер ⇒ Таблица размеров
- Fct ⇒ таблица фактов
- Stg ⇒ промежуточная таблица
В общем, предпочтительнее использовать (в таком порядке):
Таблицы измерений (dim) и фактов (fct)
Обычно описываемые как «витрины», эти таблицы представляют собой ключевые бизнес-данные и были разработаны для простоты использования при запросах.
Примером таблицы измерений является dim_organisations. Как правило, в таблицах измерений есть одна строка для каждой сущности, которую они описывают (т. е. организация), и большое количество столбцов, которые можно использовать для фильтрации и группировки этих сущностей.
В нашей таблице dim_organisations есть такие столбцы, как:
idиname, идентифицирующие организацию
in_setup_flow, завершили ли они настройку
is_paying, если есть активная подписка на Stripe
lead_id, идентификатор лида в закрытии (CRM)
Обратите внимание, что большая часть тяжелой работы по обогащению организации данными из других источников (таких как Close) уже выполнена, что упрощает фильтрацию по любому из доступных измерений без сложных объединений.
Таблицы фактов дополняют таблицы параметров и могут рассматриваться как список произошедших событий (также называемый «потоком событий»). Там, где в таблицах измерений есть одна строка для каждой сущности, вы найдете много строк (событий) для каждой из этих сущностей в таблице фактов, и вам придется объединиться с соответствующей таблицей измерения для выполнения фильтрации.
Например, у нас есть таблица fct_organisation_statistics. Он содержит строку для каждого дня существования организации, а также ряд измерений, таких как общее количество пользователей Slack, количество инцидентов, количество пользователей, создавших инциденты, и т. д.
Это таблицы данных самого высокого качества, которые мы предлагаем, и вы должны предпочесть использовать их, когда они существуют.
Промежуточные (stg) таблицы
Исходные данные, которые генерируют Fivetran и Stitch, нестабильны и часто неудобны в использовании.
Например, исходные данные закрытия не имеют концепции возможностей, поскольку они существуют в модели данных интереса и не моделируются как первоклассные объекты.
Вместо того, чтобы заставлять людей запрашивать неудобные исходные таблицы, мы решили создать промежуточные таблицы из исходных данных, которые:
- Переименовывает столбцы, чтобы они были согласованными (все столбцы true/false начинаются с
is_илиhas_)
- Приводит столбцы к нужному типу (строки временных меток анализируются как временные метки)
- Извлекает глубоко вложенные данные в подходящую форму (настраиваемые поля становятся столбцами)
И все, что нужно, чтобы превратить исходные данные в «идеальные» данные для запросов.
Возвращаясь к нашему примеру Close, у нас есть следующие таблицы:
stg_close__leads, который очищает исходные данные потенциальных клиентов и упрощает использование настраиваемых полей.
stg_close__opportunities, полностью созданный из вложенных данных возможностей в источнике потенциальных клиентов, представленных так, как вы хотели бы запросить их.
Возврат к промежуточным данным, когда нет измерения или таблицы фактов, которые могли бы лучше соответствовать вашему варианту использования.
Работа с БДТ
Эти последние несколько разделов взяты из нашего руководства по данным, и именно так мы учим выбирать правильные таблицы данных.
Это нормально, что это отражает то, как мы структурируем наш репозиторий dbt:
```javascript
дбт/модели
├── витрины
│ └── ядро
│ ├── core.yml
│ ├── dim_incidents.sql
│ ├── dim_organisations.sql
│ ├── dim_users.sql
│ ├── fct_organisation_statistics.sql
│ └── fct_user_incident_graph.sql
└── постановка
├── закрыть
│ ├── README.md
│ ├── src_close.yml
│ ├── stg_close.yml
│ ├── stg_close__activities.sql
│ ├── stg_close__leads.sql
│ └── stg_close__opportunities.sql
└── продукт
├── README.md
├── src_product.yml
├── stg_product.yml
├── stg_product__actions.sql
├── stg_product__announcement_rules.sql
└── stg_product__workflows.sql
Пока я быстро запускал учебники по dbt, мне бы очень хотелось увидеть эту структуру, чтобы придать некоторую уверенность, что мы движемся в правильном направлении.
С той оговоркой, что я всего лишь dbt'ист-любитель, стоит отметить некоторые решения, которые вошли в эту структуру:
- Вы увидите упоминания 'базовые' таблицы в литературе по dbt описывается как первое преобразование после источника и появляется перед стадией. Мы решили не создавать их и перейти сразу к промежуточным таблицам — это позволяет избежать поддержки еще одного уровня схем dbt, и многие наши данные (особенно продукт) в любом случае близки к промежуточному формату в источнике.
- Мы не создаем витрины из промежуточных моделей, если не объединяем их между схемами (как в случае с таблицами измерений) или не выполняем над ними сложные преобразования (таблицы фактов). Опять же, это сделано для уменьшения количества схем dbt.
- Сейчас у нас есть только основные витрины. Пока мы не добавим больше витрин, нет особого смысла внедрять более сложную структуру (например, группировать витрины по бизнес-единицам), которую лучше адаптировать по мере роста.
Что касается разработки с использованием dbt, у каждого инженера есть отдельный набор данных BigQuery (например, dbt_lawrence), на который они ориентируются при локальной разработке для тестирования. Запуск полной сборки (dbt build) сейчас выполняется быстро, что делает локальную разработку приятной.
Хотя эта настройка делает компромиссы подходящими для контекста инцидента.io, я думаю, что любой, кто настраивает стек данных, может принять это без особых проблем, и легко настроить вещи, как только вы лучше ознакомитесь с инструментами.
Визуализация: метабаза
Теперь наши данные очищены, преобразованы и преобразованы в идеальный формат для анализа, пришло время выбрать инструмент визуализации.
Этот выбор имеет решающее значение, поскольку все, что мы выберем, будет зависеть от того, как люди взаимодействуют с нашими данными. Одной из наших ключевых целей для этого стека было то, чтобы сотрудники, не имеющие технической подготовки, могли извлечь выгоду, и прошлый опыт работы с такими инструментами, как Looker, показал, что это возможно только при значительной помощи со стороны команды BI, чего мы хотели избежать.
Мы выбрали Metabase как наиболее интуитивно понятный вариант с визуализацией, которую можно создавать без каких-либо знаний SQL.
Является ли инструмент интуитивно понятным, субъективно, но Metabase, безусловно, так считает. В качестве примера давайте попробуем составить график количества элементов временной шкалы инцидентов, созданных за месяц, и посмотрим, как выглядит этот процесс:
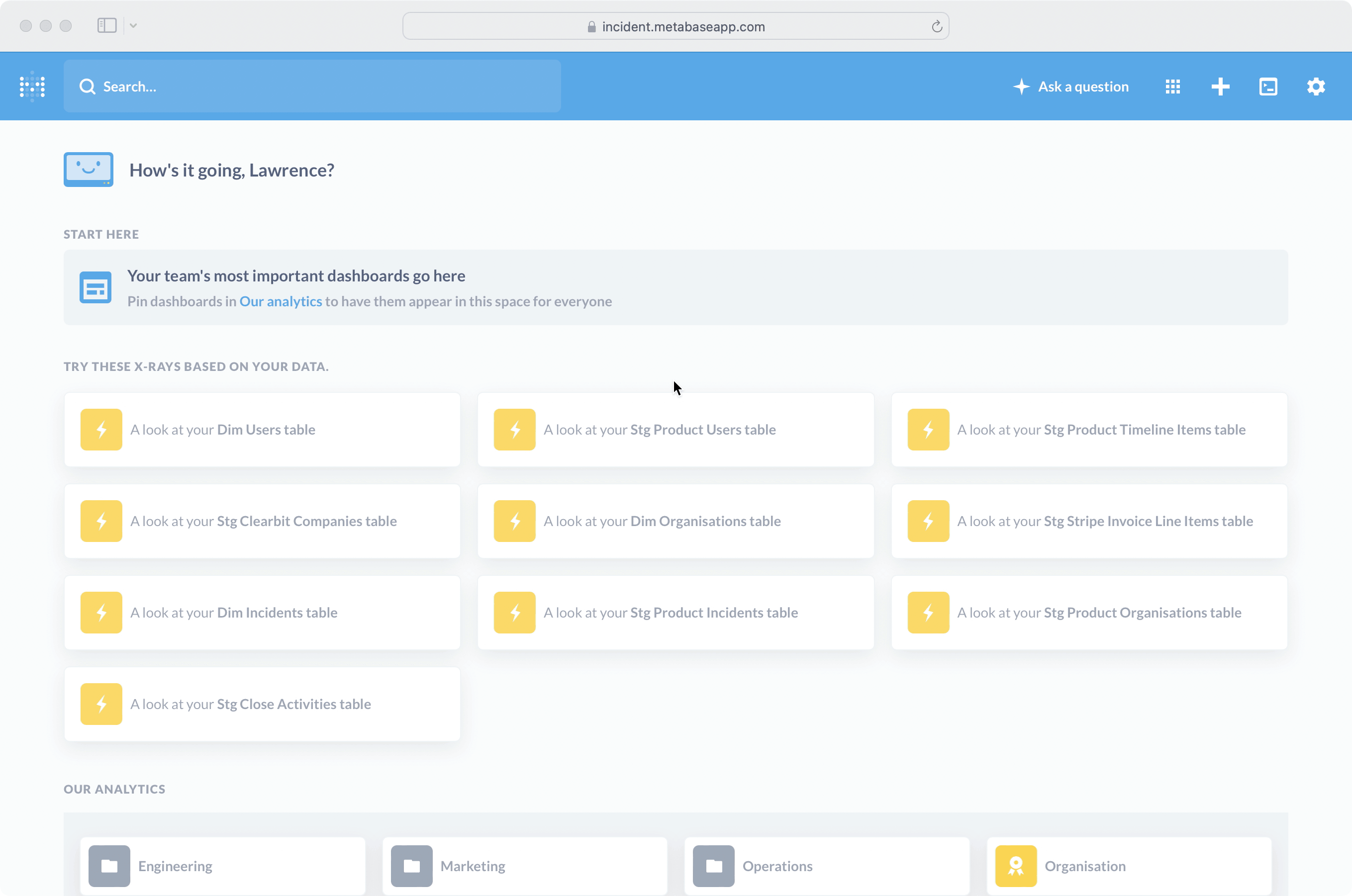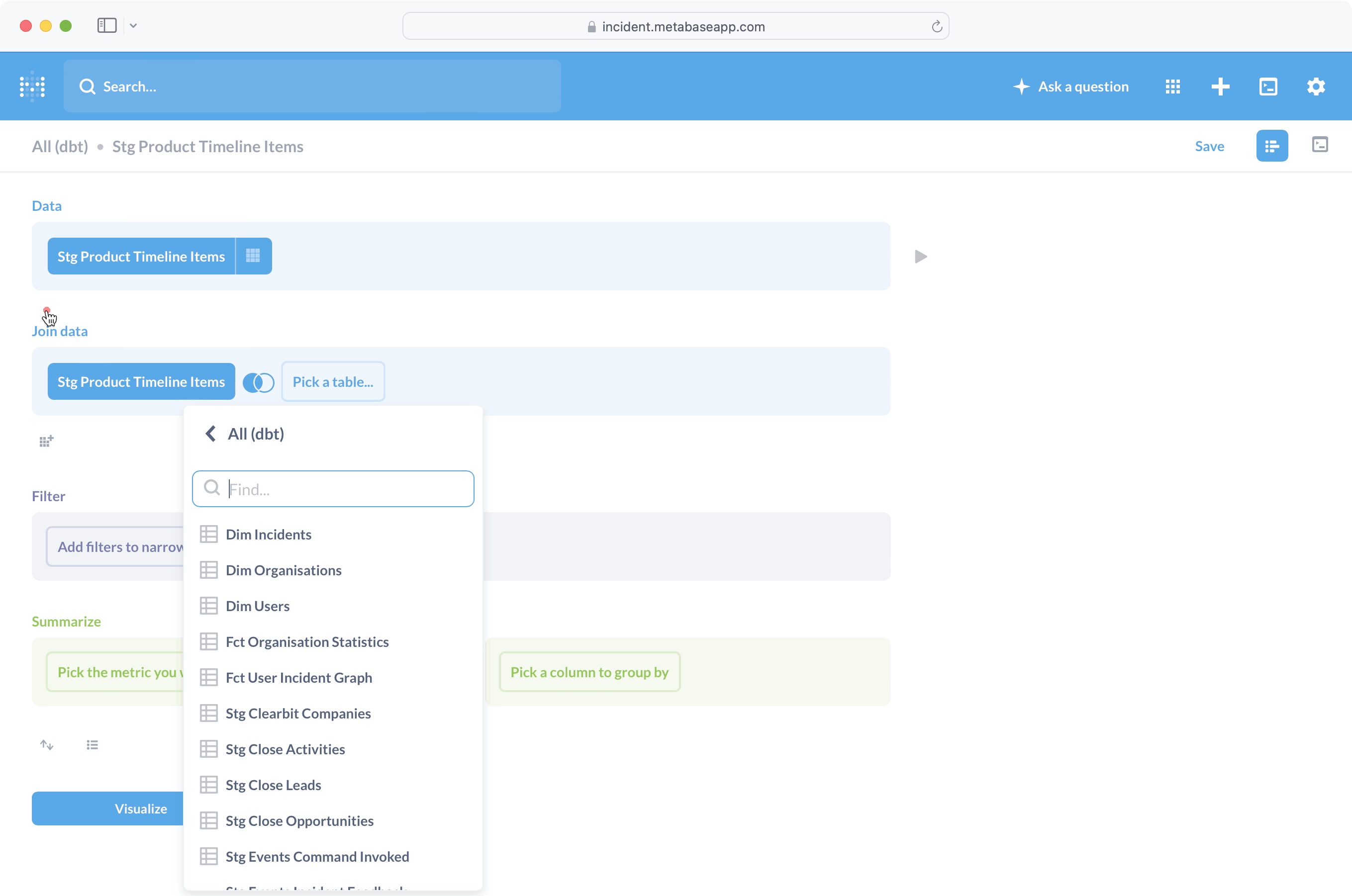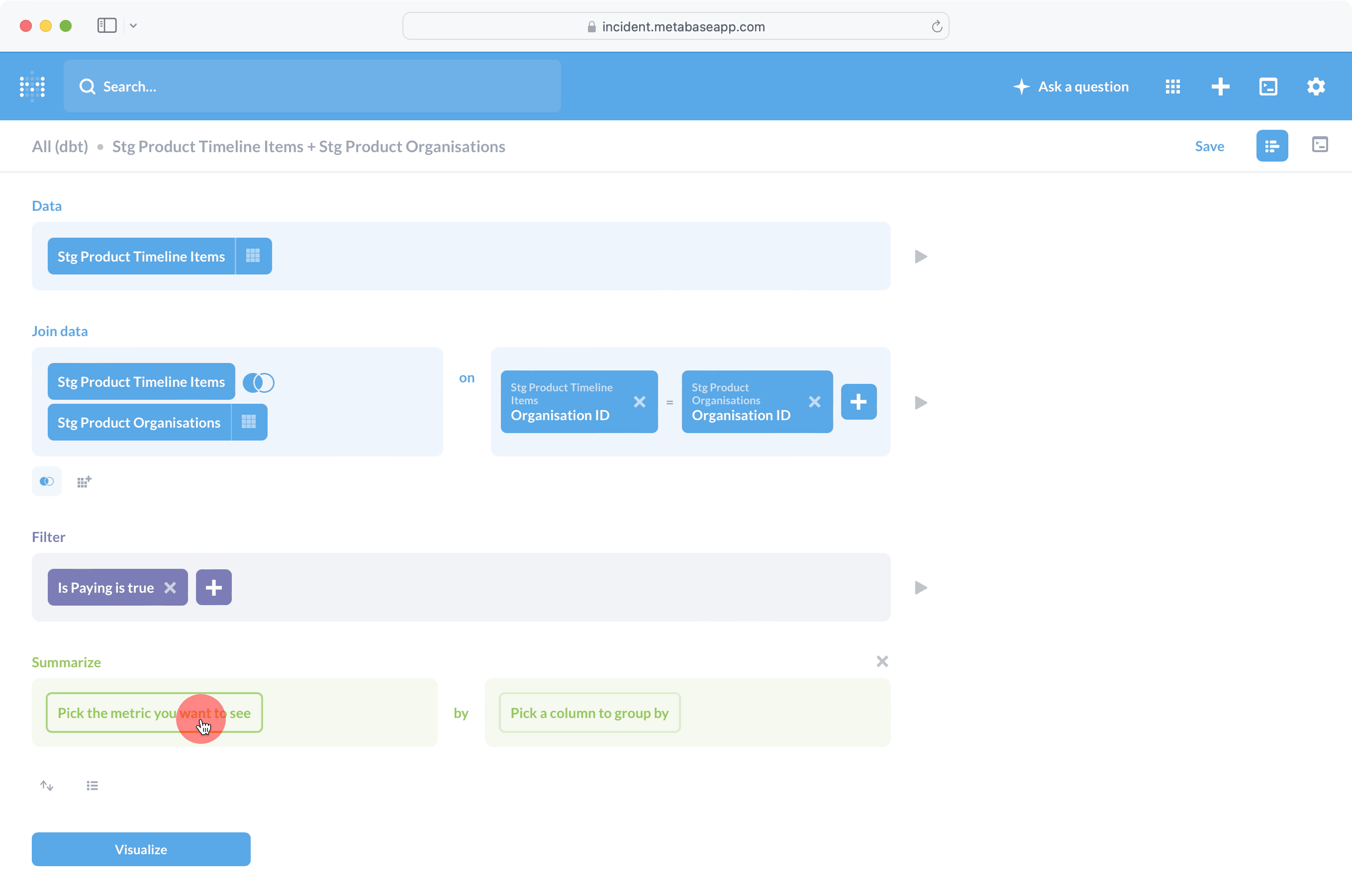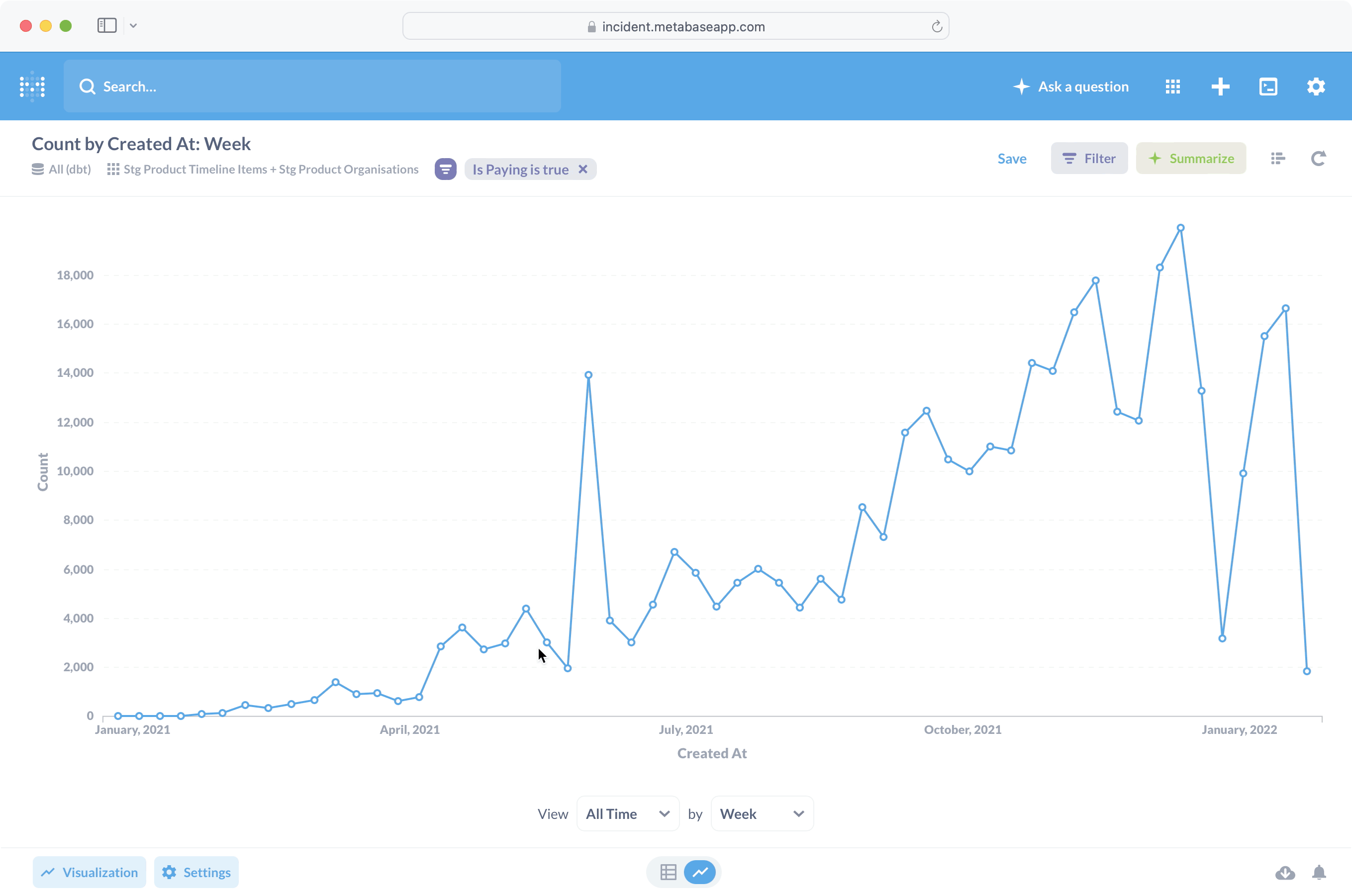
На что следует обратить внимание:
- SQL не требовался, хотя мы построили визуализацию с нуля (а не из существующего вопроса).
- Соединение таблицы Stg Product Timeline Items с Stg Product Organizations было очень простым, отчасти потому, что Metabase может автоматически определять ключи соединения (подробнее об этом позже).
- Интерфейс был очень чистым, гораздо ближе к мастеру или существующим инструментам работы с электронными таблицами, чем к традиционной цепочке инструментов для работы с данными.
Все это очень помогает при адаптации, особенно для нетехнического персонала.
Синхронизация схем dbt с метабазой
Метабаза действительно может помочь снизить барьер для доступа к вашим данным, но она ограничена тем, насколько хорошо она знает схему.
Один пример виден в предыдущей записи экрана, где при объединении элементов Stg Product Timeline с Stg Product Organizations предварительно вводится ключ соединения (идентификатор организации). Метабаза может использовать это по умолчанию только в том случае, если она знает, что идентификатор организации в элементах временной шкалы Stg Product является внешним ключом Stg Product Organizations и на какое поле он ссылается.
Как оказалось, наши схемы dbt уже знают эту информацию через тесты столбцов. Вот схема для поля organization_id элементов хронологии Stg Product:
```javascript
модели:
- имя: stg_product__timeline_items
столбцы:
- название: организация_id
описание: "ID организации"
тесты:
- ненулевой
- отношения:
кому: ref('dim_organisations')
поле: ID_организации
Всякий раз, когда у нас есть столбец, определяющий тест отношения, мы можем вывести связь внешнего ключа с родительской таблицей.
Итак, как мы можем получить это в метабазе? Существует инструмент под названием dbt-metabase , который может вывести информацию о семантическом типе метабазы из схемы dbt и передать ее в метабазу. Мы запускаем его всякий раз, когда завершаем dbt. build, помогая синхронизировать метабазу с любыми новыми полями, которые мы могли добавить.
Вывод внешних ключей — это только одно из применений этого инструмента — вы также можете указать типы столбцов вручную.
В качестве примера того, где это может быть полезно, аннотирование столбцов как «имени» позволяет Metabase использовать опережение ввода для первичного ключа этой сущности по значению имени, например, используя имя клиента в фильтре идентификатора клиента.
Вот пример установки типа:
```javascript
столбцы:
- имя: имя
описание: "Название организации"
мета:
metabase.semantic_type: тип/имя
- имя: archived_at
decription: "Когда ресурс был заархивирован"
мета:
metabase.semantic_type: тип/Временная метка удаления
- имя: возможность_годовое_значение
мета:
metabase.semantic_type: тип/валюта
description: "Если событие возможности, годовая стоимость в обычной валюте"
Адаптация и развертывание
Это покрывает весь стек. В качестве сводки:
- dbt для выполнения очистки и преобразования для облегчения анализа
- Метабаза для визуализации с [dbt-metabase][tools/dbt-metabase] для синхронизации схемы
Потребовалось около двух недель, чтобы разобраться во всем этом и открыть большую часть наших источников данных с помощью dbt и открыть их в Metabase. Это был единственный инженер, который никогда раньше не использовал dbt, и ему приходилось принимать множество таких решений на лету. Я ожидаю, что кто-то, следуя этому руководству, сможет сделать это намного быстрее.
После того, как мы запустили стек, мы провели два семинара для разных аудиторий:
- Введение в dbt для инженеров, которые будут строить модели dbt.
Мы пока не можем нанять команду BI на полный рабочий день и думаем, что сможем обойтись инженерами, добавляющими более сложные функции данных в метабазу, определяя их в dbt. На этом сеансе была рассмотрена наша настройка dbt, и мы собрались добавить функцию в модель dbt, вручную запустив синхронизацию схемы в метабазе.
- Введение в данные для всей компании.
Ожидается, что каждый будет использовать данные в своей работе, поэтому каждый должен быть знаком с Metabase. Эта сессия включала краткое изложение стека, а затем работу в группе над визуализацией нескольких ключевых бизнес-показателей.
Наконец, мы взяли список вопросов, на которые нам не терпелось получить ответы, и разделили его между собой, и люди попытались ответить на них парами.
Оба семинара прошли отлично, но вся корпоративная сессия была моей любимой. Две недели — это целая вечность для такой компании, как наша, и большинство моих решений было принято с четкими целями, но с небольшим опытом.
Это был важный момент, когда кто-то без опыта работы с SQL пришел показать мне воронку конверсии для нашего руководства по продукту, и это было совершенно правильно:
Прощальные мысли
Данные — это валюта в большинстве компаний, и крайне важно, чтобы все имели к ним равный доступ. Очень легко — особенно когда компании начинают с высокотехнологичных команд — заканчивать несколькими людьми, знающими все ответы, подрывая причастность и автономию тех, кто не входит в эту группу.
Я очень доволен нашей текущей настройкой, в первую очередь потому, что она обеспечивает равенство доступа, которого я раньше не видел.
Наконец, стоит повторить момент, который может легко остаться незамеченным: этот стек позволяет легко консолидировать данные из разных источников в единое хранилище, а это означает, что вы можете комбинировать их, чтобы получить значительно больше пользы, чем данные, которые предлагают по отдельности.
Подключение этих данных означает, что ваша деятельность по продукту может быть объединена с вашими инструментами продаж, а ваши отчеты об успехах клиентов могут учитывать такие вещи, как то, как часто клиент связывался с Intercom или есть ли у него задолженность в Stripe.
То, что описывает этот пост, является основой для извлечения выгоды из этого изменения в масштабах всей отрасли. Если вы представляете небольшую компанию, стремящуюся превзойти себя, вы сойдете с ума, если не воспользуетесь этой возможностью.
Также опубликовано [здесь] (https://incident.io/blog/data-stack).
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)