TLDR 1: набор данных больше не является жестким требованием
:::подсказка Идея о том, что для создания текстового ИИ нужны тонны данных, теперь частично устарела.
Даже очень маленький набор данных может дать ценные результаты (1 предложение ~ 1 ГБ).
То, на чем почти все стартапы сидят или могут производить вручную.
:::
TLDR 2: очень широкие варианты использования
:::подсказка Вы можете думать о GPT 3.5 как о удаленном & оплачиваемый «стажер в колледже по требованию»
Вы никогда не можете быть уверены, что стажеры правы на 100 %, но они могут принести пользу при надлежащем контроле, руководстве и планировании.
Ценность, которая теперь может плавно расти и масштабироваться (в отличие от реальных стажеров)
:::
TLDR 3: Стоимость и ограничения
:::подсказка Классическая модель юнит-экономики для SaaS и онлайн-сервисов будет сложной задачей из-за чрезвычайно высоких эксплуатационных расходов большинства LLM
OpenAI также имеет (временную) эффективную монополию на инфраструктуру в этом пространстве и может одновременно быть как партнером, так и непреднамеренным будущим конкурентом
:::
Если вы были в отпуске и понятия не имеете, что такое ChatGPT или LLM (большие языковые модели) - брифинг о технологии можно найти здесь:
https://hackernoon.com/how-aichatgpt-dreams-in-2022?embedable =правда
Итак, что я имею в виду в более длинной форме?
Выпейте чашечку кофе и немного отдохните…

Часть 1. Данные больше не являются обязательным требованием
Ускоренный курс по традиционным требованиям к текстовым данным ИИ
:::информация Примечание. В этой статье обсуждаются только требования к данным для текстовых моделей, и во многих случаях она не применяется к моделям изображений (например, компьютерному зрению).
:::
Раньше для создания модели ИИ обычно требовался сбор достаточно большого набора данных для конкретного варианта использования. Существовали различные методы и инструменты обучения модели ИИ для оптимизации процесса обучения или его вычислительных затрат.
Однако размер и качество набора данных по-прежнему были одним из основных факторов при обучении ИИ.
В результате получится примерно следующий график:
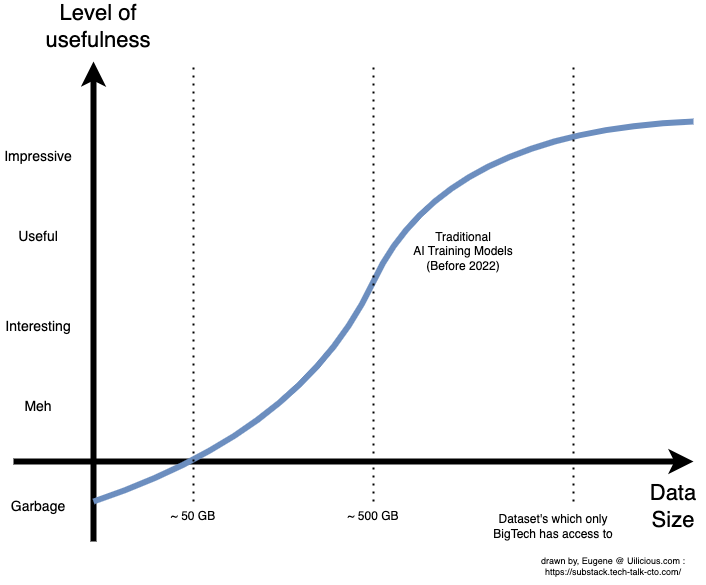
:::информация Все цифры являются большими приближениями и будут сильно меняться в зависимости от варианта использования, модели ИИ и качества данных. Шкалы на осях намеренно расплывчаты и неточны, потому что они субъективны. Чтобы узнать технические номера, прочтите статьи в справочных материалах для конкретных случаев использования.
Однако общая идея остается неизменной: небольшие наборы данных производят фактически случайные данные, прежде чем постепенно улучшаться и, наконец, становиться полезными примерно на участке размером около 500 ГБ.
:::
Это привело к гонке вооружений за наборы данных, которая произошла почти во всех областях специализации, связанных с ИИ (особенно во всем, что связано с компьютерным зрением).
Это происходило во многих стартапах с 2009 года по сегодняшний день, причем несколько известных стартапов были приобретены отчасти из-за их ценных наборов данных (и, как правило, талантов).
Поскольку гонка вооружений постоянно обострялась, новым стартапам становилось все труднее конкурировать со своими моделями ИИ (небольшие наборы данных) с традиционными (большие наборы данных).
Например, в uilicious.com (стартапе по автоматизации тестирования пользовательского интерфейса с низким кодом) мы использовали наш ограниченный набор данных для обучения модели ИИ (называемой TAMI v0.1). Мы обнаружили, что в половине случаев он выбрасывал мусор, что побудило нас отказаться от модели и развивать компанию без ИИ при создании набора данных.
В очень обобщенном и нетехническом смысле, ИИ, обученный таким образом, далее будет называться «Специализированные модели».
Начало LLM или больших языковых моделей
В поисках действительно универсального или универсального ИИ, особенно в области речевого взаимодействия человека (поскольку люди создают наиболее случайные из всех переменных), возникли усилия по обучению нового типа текстового ИИ для чрезвычайно большие наборы общедоступных данных (вспомните Википедию, Quora, StackOverflow и половину интернет-текста).
Поскольку эти новые модели расширили границы размеров наборов данных и размера модели (например, размера мозга), методы, используемые для их построения, отличались от специализированных моделей (которые, как правило, больше внимания уделяют точности и эффективности).
Модели текстового ИИ, обученные таким образом, теперь называются моделями больших языков (LLM).
Недостаток этого подхода был огромным, что мешало его раннему применению во многих случаях:
- Необходимо создавать и поддерживать очень большие наборы данных (GPT-3 использовал 45 ТБ).
- Обучение стоит миллионы долларов (обучение GPT-3 стоит более 4 млн долларов, GPT-3.5/chatGPT предположительно дороже)
- Ограниченное использование в особых случаях из-за отсутствия данных о частных тренировках.
- Точность ниже, чем у специализированных моделей, в… особых случаях использования
- Дорого в эксплуатации (подробнее об ограничениях позже)
:::подсказка В LLM доминировали Google (у которого уже были данные и был мотив сделать это для своего помощника по искусственному интеллекту) и OpenAI изначально. Позже к гонке присоединились Microsoft, Amazon, Apple, Salesforce, Meta и некоторые другие. Однако из-за огромных размеров и стоимости обучения такой модели ее обычно используют крупные технологические компании с глубокими кошельками.
:::
Хотя первые несколько поколений LLM, возможно, дали неутешительные результаты, поскольку они проигрывали почти каждой специализированной модели в каждой задаче, с годами все изменилось, и они увеличились как в размере набора данных, так и в размере модели.
Их преимущества стали более заметными:
- Не говоря уже о фактах и точности, они научились хорошо разговаривать с людьми.
- он очень универсален
- Во многих (но не во всех) случаях: они действительно хорошо усваивают новые специализированные знания, когда получают наборы данных в соответствующем формате (вы не можете просто выгрузить их)
Это внесло кардинальные изменения в кривые:
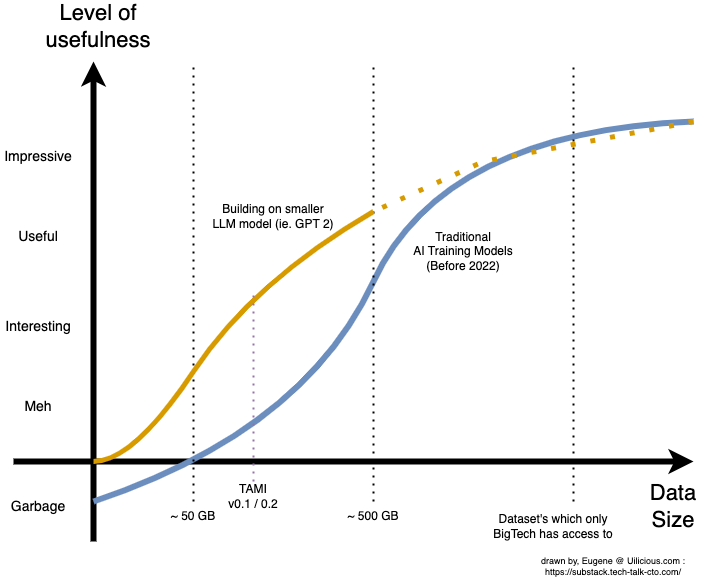
Это также вызвало новую волну бизнес-моделей на основе ИИ в 2019 году. Теперь стартапы могут обучать новые модели ИИ поверх существующих LLM с доступными наборами данных, от чат-ботов до генераторов слайдов презентаций, сопилотов кода, копирайтинга и даже D&D. мастера игры.
Эти модели ИИ больше не были прерогативой крупных технологических компаний. За небольшую плату за обучение и запуск ИИ в своей инфраструктуре OpenAI и Google начали открывать свои модели для других, чтобы они могли использовать их как средство получения прибыли от LLM.
Это также было выгодно для стартапов, поскольку им больше не требовались миллионы долларов инвестиций в исследования и разработки, необходимые для создания этих крупных моделей внутри компании, что позволило им быстрее выйти на рынок с их доказательствами концепции.
Дейта все еще была в некотором роде королем. Возможно, это сделало кривую более доступной, но для создания больших наборов данных и настройки модели по-прежнему требовалась команда.
В результате, хотя многим из стартапов 2019 года было значительно проще создавать свои прототипы, многим было трудно преодолеть порог полезности, поскольку им нужно было масштабировать набор данных с уменьшающейся отдачей.
:::информация Это согласуется с ранними внутренними испытаниями моделей искусственного интеллекта uilicious.com TAMI v0.2 — хотя GPT был огромным улучшением по сравнению с мусором, он все еще был между интересными и "ммм".
:::
Но именно тогда в 2022 году все действительно начнет меняться....
Почему модели большого языка плохо учатся
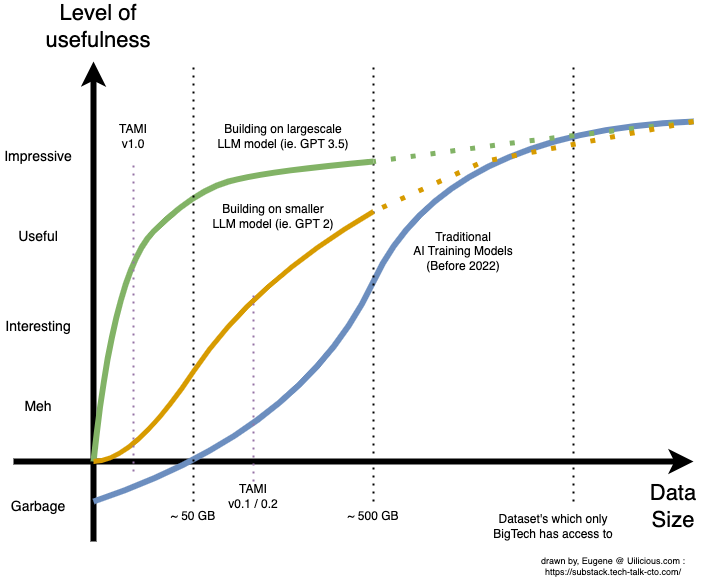
Выпуск GPT 3.5 (или chatGPT, как его называют в Интернете) в прошлом месяце (декабрь 2022 г.) оказал огромное влияние на то, как модели искусственного интеллекта обучаются и настраиваются.
Это открыло возможность создания пригодного для использования ИИ с очень небольшими наборами данных — то, к чему большинство стартапов имеют доступ или могут создать вручную. Это фундаментальный сдвиг в том, как мы думаем об обучении ИИ.
:::информация На uilicious.com мы были ошеломлены, когда обнаружили, что небольшой образец набора данных размером менее 1 ГБ из нашего более крупного набора данных размером примерно 100 ГБ при преобразовании и оптимизации с помощью новые методы обучения преодолели «порог полезности» — точку, в которой наши пользователи могли использовать ИИ и превзойти все, что у нас было раньше.
В то время как последующие эксперименты с большими наборами данных показали убывающую отдачу. Ключевой вывод заключался в том, как мало данных требовалось для «создания полезного продукта». Нам потребовалось меньше времени, чтобы создать экспериментальный ИИ, точно настроенный для нашего собственного варианта использования, чем на написание этой статьи.
:::
Используя GPT 3.5 в качестве базового строительного блока, теперь можно создавать полезные приложения ИИ для различных вариантов использования, не требуя специализированной команды или отдельного человека.
В зависимости от варианта использования набор данных может иметь размер от одного предложения или абзаца до 100 МБ или 1 ГБ – такой размер подходит для многих стартапов.
В качестве альтернативы, если вы можете заставить chatGPT действовать так, как вы считаете полезным и ценным для вашего стартапа, вы можете создать его как специальный сервис ИИ.
Резкое сокращение необходимого набора данных позволило нам построить «полезную» модель ИИ, используя лишь небольшую часть нашего полного набора данных, что ранее было «бесполезным» или «невозможным» в нашем масштабе.
Во многих отношениях данные больше не имеют решающего значения, поиск и создание полезных приложений являются настоящими творцами королей с этим новым искусственным интеллектом. Где идеи могут быть созданы и протестированы за недели (а не годы).

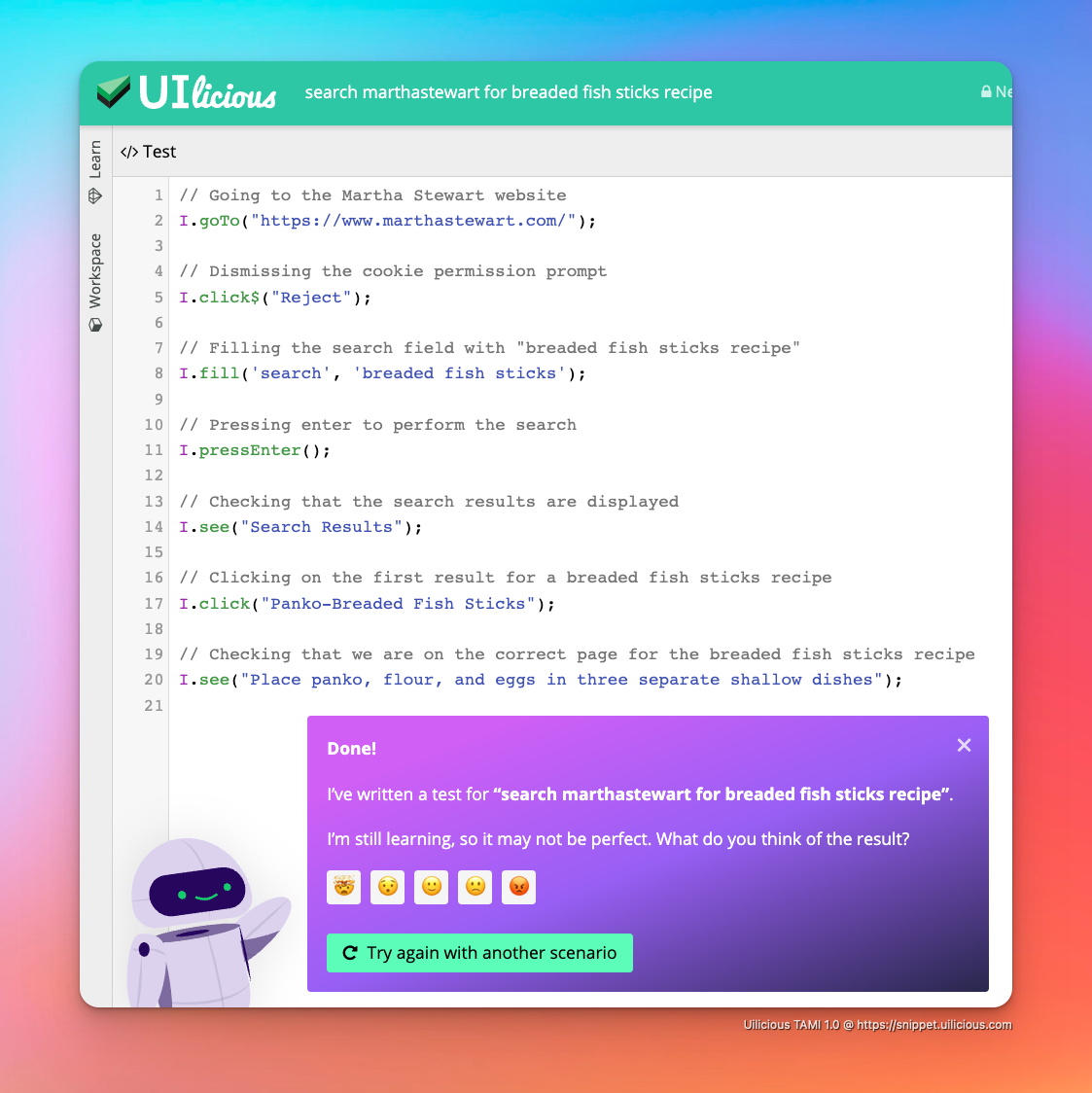
:::информация Скриншот представляет собой демонстрацию нашего ИИ в действии, генерирующего полные сценарии тестирования пользовательского интерфейса из подсказки в качестве примера интеграции. (один из многих вариантов)
То, что теперь можно сделать за неделю, с правильной командой и правильными данными.
Свяжитесь с нами, если вас интересует будущее тестирования ИИ и пользовательского интерфейса.
:::

Часть 2. Поиск вариантов использования (и стажеров по ИИ) начался
Внутренняя структура для поиска вариантов использования
GPT-3.5 и все другие модели больших языков имеют ограничения по точности и надежности. Отчасти это связано с тем, что они выдумывают ответы.
Хотя теоретически (еще не доказано), при достаточно большом специализированном наборе данных его точность может быть значительно улучшена для специализированных случаев использования. Однако, если у вас есть такой большой набор данных, скорее всего, вы уже можете создавать «специализированные модели».
В конечном счете, этот предел точности и надежности является критической проблемой только в чувствительных отраслях (например, в медицине). В большинстве случаев это просто отвлечение при поиске вариантов использования. Как только ИИ пересекает порог «достаточно хорошего» (что он и делает).
<цитата>Более здоровый и реалистичный подход к проблеме — представить GPT-3.5 как удаленного и оплачиваемого «умного стажера в колледже по запросу»
Потому что на самом деле у ИИ есть все те же ограничения в таких случаях использования, помимо того, что он удаленно и онлайн:
* Никогда не верьте интернам в то, что они всегда правы на 100% (не говоря уже о диагностике медицины) * Создайте рабочий процесс, который позволяет стажеру безопасно предоставлять полезную ценность с соответствующим контролем, руководством и планированием. * Для однодневных или месячных стажеров вы должны создать формальный план обучения, чтобы быстро повысить их продуктивность за один час или одну неделю обучения соответственно. Вы должны платить своим стажерам; они не бесплатны (как для людей, так и для ИИ)
Единственное реальное преимущество модели ИИ по сравнению с реальными стажерами заключается в следующем:
- На них не влияют школьные сезоны.
- Вы можете масштабировать как вверх, так и вниз в любую секунду.
- Обучение – это то, что вы можете проводить один раз в пакете, а затем увеличивать количество экземпляров.
Недостатком ИИ по сравнению с людьми является то, что он не может принести вам кофе лично.
Как только вы сформулируете это в этих терминах, станет значительно проще понять, как интегрировать ИИ в существующие бизнес-процессы или продукты.
- Нужно придумать идеи для статей? Наймите стажера на один день.
- Необходимо преобразовать проприетарный код Java в код JavaScript? Наймите месячного стажера и пройдите базовое обучение этому процессу.
- И так далее, и тому подобное, где ни на каком этапе процесса человек не должен быть удален из цикла при контроле и итерации со стажером.
:::информация Немного более технический уровень:
- Стажер-однодневка может быть быстро создан с помощью быстрого проектирования; все, что вам удается заставить chatGPT делать, попадает в эту категорию. Недостатком является то, что существует практический предел (около 2000 слов) того, что вы можете поместить в обучающие данные. Положительным моментом является то, что вы можете поэкспериментировать и настроить это за считанные секунды, и это очень легко протестировать с помощью chatGPT.
* Месячная стажировка (или что-то среднее между ними) — это когда вы начинаете иметь формальный набор данных для обучения, который они могут запомнить и изучить. Они смогут справиться с большим количеством ситуаций в соответствии с учебными материалами. Недостатком является то, что вам действительно нужно подготовить этот учебный материал; это более технически сложный процесс.
:::

Часть 3. Стоимость и бизнес-ограничения
Цена за приглашение создаст или разрушит бизнес-модель
Это самая большая слабость нового подхода к ИИ, основанного на более крупных и качественных моделях. К сожалению, бесплатных обедов не бывает.
Хотя обучаться конкретным задачам дешевле и проще с точки зрения размера набора данных, его запуск значительно дороже по сравнению с более традиционными моделями ИИ.
Это не дешево; стоимость подсказки и ответа колеблется от одного до пятидесяти центов, в зависимости от того, сколько данных необходимо для обучения или использования в процессе. Это значительно выше, чем у обычного сервера API, который может обрабатывать миллион запросов за доллар.
Проще говоря, серверное оборудование требует больше средств для обработки одного запроса ИИ для одного пользователя в течение заданной секунды, чем для обслуживания миллиона пользовательских запросов для типичного веб-сайта Shopify среднего размера.
Это связано не только с тем, что OpenAI или Azure пытаются получить прибыль; для запуска таких больших моделей требуется чистая аппаратная инфраструктура сервера.
В результате, несмотря на свою мощь, включение такой большой языковой модели ИИ имеет высокую цену и может не подходить для всех случаев использования только из-за этого ограничения.
Конечным результатом является то, что, хотя многие варианты использования могут выиграть от использования такого ИИ, не все варианты использования могут себе это позволить; и это должно быть важным соображением для любой реализации.
Пример A: Чат службы поддержки
Обычный персонал службы поддержки может обслуживать десять клиентов в час, при этом каждый клиент получает в среднем пятнадцать запросов туда и обратно. Если это пять центов за подсказку, это составит до 7,50 долларов США в час, если ИИ использовался для имитации одного сотрудника службы поддержки.
Это не только дешевле, чем средняя заработная плата типичного сотрудника колл-центра в США, составляющая 15 долларов США в час, но и гораздо более гибкая (отсутствие накладных расходов на персонал, возможность мгновенного повышения и понижения).
Точно так же можно использовать тот же «стажерский» подход, когда этот вспомогательный ИИ служит только в качестве поддержки L1, позволяя людям обрабатывать более сложные случаи. В этом сценарии это имеет смысл, когда это делается и масштабируется соответствующим образом для каждой подсказки (или для каждого часа).
Пример Б: SaaS-сервис для черновиков писем
В среднем офисный работник отвечает примерно на сорок электронных писем в рабочий день или примерно на 880 электронных писем в месяц. Даже по пять центов за электронное письмо это будет в среднем 44 доллара США в месяц на одного пользователя только для обработки ответов на электронные письма.
Что еще хуже, так это то, что разумно ожидать, что с такой услугой офисный работник сможет в среднем ответить на большее количество электронных писем. Было бы разумно, если бы в среднем удвоились до двух тысяч электронных писем, или сто долларов в месяц, только за счет чистых затрат на ИИ.
В этом случае, если стартап SaaS будет использовать простую цену, скажем, десять долларов в месяц, со временем он может понести большие потенциальные убытки.
Эта модель ценообразования и бизнес-модели противоречит типичной модели ценообразования из расчета на пользователя, распространенной в SaaS. Вот почему такие интеграции обычно имеют систему «кредитов» как средство ограничения использования и средства выставления счетов за такой ИИ.
:::информация Ожидается, что со временем, благодаря более тонкой настройке, конкуренции и оптимизации затрат, цена за приглашение может снизиться. Еще один примечательный метод — сначала использовать исходный более дорогой ИИ при запуске, собирая больше данных, которые затем используются для обучения более специализированной и более дешевой модели. Однако все эти методы имеют глубокие технические детали, которые могут быть уникальными для каждого варианта использования и, как правило, требуют значительного времени и усилий.
И даже в этом случае, несмотря на то, что это может дать десятикратную экономию, существенно дороже, чем традиционные API-сервисы SaaS.
:::
OpenAI имеет эффективную монополию (на данный момент)
Цены могут оставаться на прежнем уровне до появления конкурентов
Несмотря на то, что модели больших языков с открытым исходным кодом существуют, если говорить откровенно, они либо сравнимы с GPT2, либо где-то между GPT3.5.
n В некоторых простых случаях, когда они начинают создавать разумный набор данных, эти меньшие (и более дешевые) модели могут быть полезны для перехода на них в качестве средства сокращения затрат.
Однако в других сложных случаях такой шаг может быть невозможен из-за сложности их ИИ, что дает OpenAI эффективную монополию без стимула для снижения цен.
Однако считается, что в течение следующих одного-двух лет сообщество разработчиков ПО с открытым исходным кодом наверстает упущенное и тем самым, возможно, позволит повысить цены благодаря более качественным альтернативным поставщикам инфраструктуры.
Однако, поскольку это неопределенное будущее, на нем стоит остановиться.
OpenAI является потенциальным нежелательным конкурентом для некоторых моделей
Хотя это и не преднамеренно, очень важно, чтобы стартапы в этом пространстве создавали наборы функций, которые можно защитить за пределами их ботов, отправляющих текстовые подсказки.
Например, было несколько небольших стартапов, которые создали ботов на основе GPT3 или SaaS для конкретных вариантов использования текстовых приглашений, таких как генераторы имен или генераторы идей с простым интерфейсом.
Буквально за одну ночь, с запуском chatGPT, эти небольшие одноразовые SaaS-программы для преобразования текста в текст стали ненужными, поскольку обычные люди теперь могут получить те же функции через chatGPT бесплатно.
Хотя у OpenAI, возможно, не было намерения конкурировать с теми самыми партнерами, которые опираются на них, это может быть неизбежно, поскольку они продолжают улучшать свою модель и chatGPT.
Таким образом, чтобы это не повторилось, для любой бизнес-модели, основанной на этой технологии, очень важно выяснить, какую дополнительную ценность они обеспечивают, помимо простого текстового приглашения, возможно, лучшего взаимодействия с пользователем или интеграции с существующими инструментами и т. д.< /p>
Наконец: это не идеально
Напоминание о модели стажера: не рассчитывайте использовать ее для лечения рака завтра. Поэтому, пожалуйста, не внедряйте ИИ во все продукты и стартапы на Земле, если это не принесет пользы конечному пользователю.
~ До следующего раза 🖖 живите долго и процветайте n Юджин Чеа: технический директор uilicious.com
Эта статья изначально была размещена в подстеке автора

Дополнительные примечания, которые не поместились
swyx также отлично справляется с объединением различной информации в этом быстро хаотичном и растущем пространстве, которое очень стоит прочитать (рекомендуется!!!)
* День рождения AGI: https://lspace.swyx.io/p/everything- мы-знаем-о-чате * Как Open Source поглощает ИИ: https://lspace.swyx.io/p/open-source-ai< /а> * Его живые заметки ИИ: https://github.com/sw-yx/ ai-notes/blob/main/TEXT.md#chatgpt
В настоящее время BLOOM является основным претендентом на GPT3 (не 3.5) с открытым исходным кодом: computer-f48e1e2a9a32">https://towardsdatascience.com/run-bloom-the-largest-open-access-ai-model-on-your-desktop-computer-f48e1e2a9a32
В индустрии искусственного интеллекта и машинного обучения способность LLM быстро изучать новые концепции и применять их количественно оценивается и измеряется с помощью тестов, называемых «Нулевым», «Одним выстрелом» и «Несколько выстрелов».
Как правило, чем лучше ИИ проходит эти тесты, тем меньше данных вам потребуется для его обучения для вашего варианта использования.
:::информация На мой взгляд: задним числом это имеет смысл — кто бы мог подумать, что нейронная сеть, созданная по образцу людей, будет действовать как люди? И воспользуйтесь моделью обучения T-Shape. Где большой объем обобщенных знаний помогает улучшить способность изучать специализированные знания в одной области знаний. (это утверждение не подкреплено никакими данными)
:::
Другие источники и цитаты
- Учебный набор GPT-3 45 ТБ: https://www. .springboard.com/blog/data-science/machine-learning-gpt-3-open-ai/
- GPT-3 оценивается в 4 миллиона долларов США++ плюс затраты на обучение: https://lambdalabs.com/blog/demystifying-gpt-3.
- Bloom AI, конкурент с открытым исходным кодом, потратил на обучение 1,6 млн долларов: https://techcrunch.com/2022/07/12/a-year-in-the-making-bigsciences-ai-language-model-is-finally-available/
- Т-образная модель образования и работы
- https://wordspy.com/index.php?word=t-Shape
- https://collegeinfogeek.com/become-t-Shaped-Person/
- Большие документы по языковым моделям для практических занятий.
- https://arxiv.org/abs/2205.11916 (нулевой снимок)
- https://arxiv.org/abs/2005.14165 (несколько снимков)
- Ставки заработной платы колл-центров в США: https://www.comparably.com/salaries/. зарплата оператора колл-центра
- Среднее количество электронных писем, отправляемых офисным работником в день: https://www.templafy.com/blog/how-many-emails-are-sent-every-day-top-email-statistics-your-business-needs- знать/
- Объявление OpenAI о chatGPT/GPT3.5: https://openai.com/blog/chatgpt/
- Открыть авторство фотографий
- https://unsplash.com/photos/7swaW1bYpWI
- https://unsplash.com/photos/1iVKwElWrPA
- https://unsplash.com/photos/SELXIJwN24s
- https://unsplash.com/photos/3xwrg7Vv6Ts
- https://unsplash.com/photos/-G3rw6Y02D0 п