

Производительность и портативность кадров для фазы префиллы LLM
14 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
7.1 Портативность и производительность для предпочтений
Чтобы оценить фазу предварительного заполнения, мы сосредоточимся на ядрах внимания, предоставленных Flashattention v2.5.6 [9, 33] и Flashinfer v0.0.3 [11, 46]. Мы не включаем VLLM в эти эксперименты, потому что у него нет собственного ядра преподресса, а вместо этого использует ядро флэшта. Мы также не могли оценить YI-34B, потому что ядра FlashInfer не поддерживают размер KV группы YI-34B в 7 [23].
Flashinfer - это библиотека, которая недавно представила набор ядер внимания, оптимизированные для различных сценариев, например, для
Перефиллы-оптимизация, предложенная в Сарати [26], а затем принята в различных системах [25, 36, 38]. Сарати расщепляет входные токены подсказки в несколько небольших кусков и планирует один кусок за раз, позволяя системе порции добавлять новые запросы в партии, не приостанавливая текущие декоды. Это помогает улучшить пропускную способность без увеличения задержки [25]. Как вспышка, так и Flashinfer обеспечивают ядра для вычисления показателей внимания ChunkedPrefills с и без нее. Мы интегрируем их в VLLM и используя размер чанка токенов 2048, измерьте время на первое место (TTFT) для следующих конфигураций:
FA_PAGED:Использует flash_attn_with_kv_cache ядра API Flashattention.
Fi_paged:Использует ядро Pageinfer PageNattureation, представляющее современное ядро на основе Pagegatatention для фазы префилля.
FA_VATTITION:Использует ядро ванильного префилля Flashattention с помощью API Flash_attn_func.
FI_vAttention:Использует ядро ванильного префилля FlashInfer через API single_prefill_with_kv_cache.
Таким образом, обе конфигурации ваттенции используют ядра, которые поддерживают кусочку, над практически смежными Kvcache. Мы добавляем им поддержку динамического распределения памяти без необходимости изменения их кода.
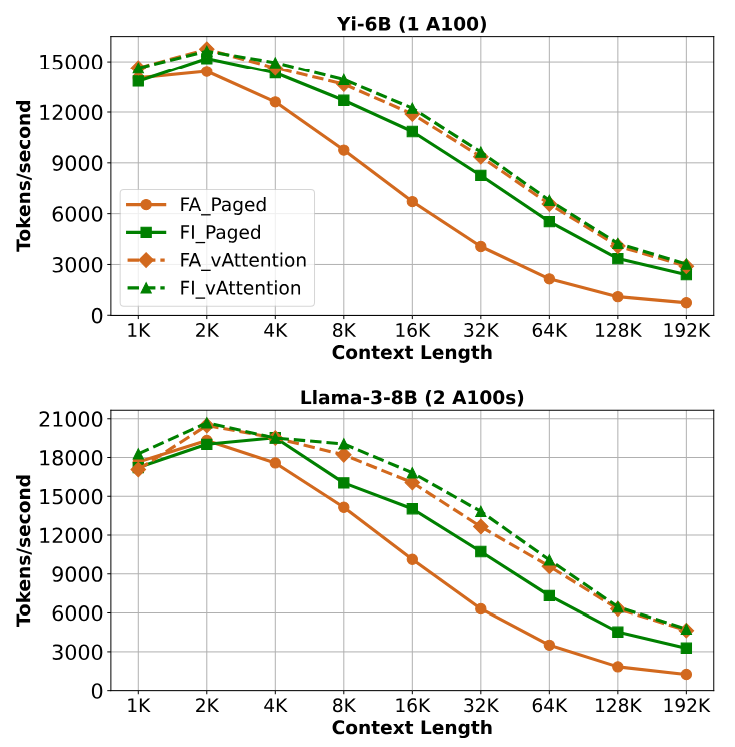
На рисунке 8 показана пропускная способность преобразования четырех конфигураций для YI-6B и Llama-3-8B. Во всех случаях, ваттенция обеспечивает неизменно более высокую пропускную способность, опережая
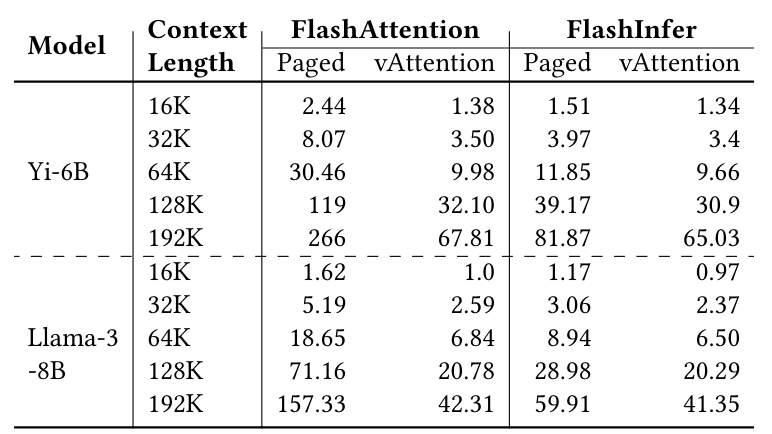
FA_PED на 1,60 - 3,92 × и Fi_Pedged на 1,03 - 1,45 ×. Для того же эксперимента, таблица 6 показывает TTFT с различной длиной контекста. Поскольку TTFT напрямую зависит от пропускной способности, по сравнению с использованием ванильных ядер с ваттинцией, FA_PAGED и FI_PAGE увеличивает TTFT на 3,92 × (YI-6B, длина контекста 192K) и 1,45 × (LLAMA-3-8B, длина контекста 192K), соответственно.
Источником прироста производительности Vattument является двойным в этих сценариях. Во -первых, ядро ванили быстрее, чем ядро погибло как в флештере, так и в Flashinfer. В то время как ядра Flashattention не оптимизирована для предпочтений (оно оптимизировано для декодов), ядро FlashInfer специально разработано для поддержки наборов. Тем не менее, ядро погибло более медленнее, чем ванильное ядро, как обсуждалось в §3.3. Этот пример иллюстрирует сложности передачи критически важной оптимизации между различными реализациями-даже когда реализации написаны одной и той же командой. Вторым источником улучшения является меньше накладных расходов на ЦП. Например, для добавления нового тензора K или V к KV-кэшу требуется одна операция копирования тензора в ваттенции, тогда как в реализации страниц, оно требует добавления по одному блоку за раз. Кроме того, FlashInfer включает в себя создание и удаление нескольких объектов для его сжатых блок-столов в каждой итерации. Vattument избегает таких накладных расходов, поскольку оно сохраняет виртуальную смелость Kvcache и, следовательно, не требует блочного стола.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
4 признака того, что ваш Instagram взломали (и что делать)
16 ноября 2022 г. -
Предстоящие эксклюзивы для PS5 — график выхода подтвержденных игр
24 октября 2023 г. -
Как подключить беспроводную клавиатуру Apple к Windows 10
18 апреля 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
Categories
- Технологии и IT (25544)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (271)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)
