

Ваттиция: эффективность распределения физической памяти для LLMS
18 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
2.1 Модели больших языков
2.2 Фрагментация и Pagegataturation
3 проблемы с моделью Pagegatatturetion и 3.1 требуют переписывания ядра внимания
3.2 Добавляет избыточность в рамки порции и 3,3 накладных расходов
4 понимания систем обслуживания LLM
5 Vattument: проектирование системы и 5.1 Обзор дизайна
5.2 Использование поддержки CUDA низкого уровня
5.3 Служение LLMS с ваттенцией
6 -й ваттиция: оптимизация и 6,1 смягчения внутренней фрагментации
6.2 Скрытие задержки распределения памяти
7 Оценка
7.1 Портативность и производительность для предпочтений
7.2 Портативность и производительность для декодов
7.3 Эффективность распределения физической памяти
7.4 Анализ фрагментации памяти
8 Связанная работа
9 Заключение и ссылки
7.3 Эффективность распределения физической памяти
Распределитель кэширования Pytorch выделяет объекты памяти (например, тензоры), не требуя поездки в оба конца к ядру. В отличие от этого, Vattument должна вызывать драйвер ядра Cuda, одновременно отображая новую физическую страницу в KV-кэше запроса. В этом разделе мы показываем, что с помощью наших оптимизаций ваттенция может эффективно соответствовать требованиям как предварительных, так и декодирует фазы в системе обслуживания LLM.
Таблица 7 показывает, что даже с нашим наименьшим размером страницы 64 КБ, ваттенция может выделять до 7,6 ГБ в секунду на графический процессор. Это более чем на порядок выше, чем максимальная скорость распределения памяти 600 МБ в секунду декодов (рис. 6). Большие размеры страниц и более высокие размеры TP увеличивают скорость распределения памяти пропорционально. Это показывает, что судации более чем способны удовлетворить полосу распределения памяти декодах.
Кроме того, на рисунке 10 показано, что наша оптимизация перекрывающегося распределения памяти с помощью выполнения модели также скрывает влияние задержки на вызов API CUDA. Этот пример показывает задержку итераций последовательных декодирования для LLAMA3-8B, работающих с TP-1 и размером партии 4. Без перекрывающегося распределения памяти с помощью вычислений, новые страницы для kv-cach выделяются синхронно, которые увеличивают
Задержка некоторых итераций от 25 миллисекунд до 41 миллисекунд (≈ 4 миллисекундных задержек из -за распределения памяти по одному запросу). Обратите внимание, что эти скачки задержки происходят после каждых 1024 итераций, потому что мы использовали размер страницы 2 МБ для этих экспериментов, и каждая 2 МБ страница содержит 1024 токена для этой конфигурации модели. Когда распределение памяти перекрывается с выполнением модели предыдущей итерации декодирования, эффект задержки полностью скрыт.
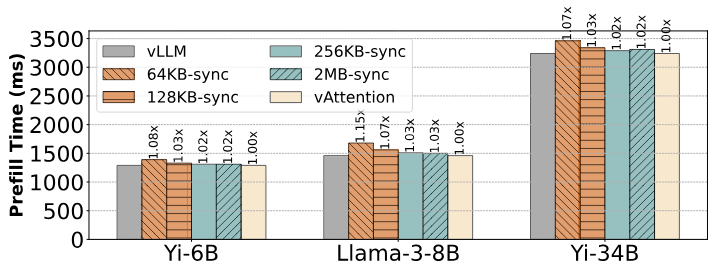
Наконец, поскольку для предварительной засыпания может потребоваться более одной страницы для KV-кэша, мы также исследуем, как различные схемы распределения памяти влияют на задержку предварительного заполнения. На рисунке 11 показано, что распределение синхронной физической памяти (когда наша фоновая поток, отсроченная рекультивация и оптимизация энергичных распределений отключено) могут добавить до 15% накладных расходов с размером страницы 64 КБ. Большие размеры страниц амортизируют стоимость распределения и снижают накладные расходы до 3% (с размерами 256 КБ и 2 МБ). Слива дополнительно снижает стоимость распределения с отложенной мелиорацией и стремлением распределения при перекрывающемся распределении памяти с помощью вычислений. В большинстве случаев эти оптимизации гарантируют, что недавно прибывший запрос может просто повторно использовать страницы физической памяти, которые были выделены на предыдущий запрос. Следовательно, ваттенция несет незначительные накладные расходы, выполняя столь же хорошо, как VLLM для предварительных выборов.
Эта статья естьДоступно на ArxivПод CC по лицензии 4.0.
Авторы:
(1) Рамья Прабху, Microsoft Research India;
(2) Аджай Наяк, Индийский институт науки и участвовал в этой работе в качестве стажера в Microsoft Research India;
(3) Джаяшри Мохан, Microsoft Research India;
(4) Рамачандран Рамджи, Microsoft Research India;
(5) Ашиш Панвар, Microsoft Research India.
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)