

Использование SypGL и Python для запуска аналитики командной строки
7 ноября 2022 г.Командная строка невероятно мощна, когда дело доходит до обработки данных. Тем не менее, многие из нас, работающих с данными, не пользуются ими. Я могу придумать несколько причин:
- Плохая удобочитаемость: основное внимание уделяется тому, чтобы свести к минимуму объем ввода, а не тому, насколько удобочитаема последовательность команд.
- Крутая кривая обучения: множество команд с множеством параметров.
- Выглядит устаревшим: некоторые из этих инструментов существуют с 70-х годов и предназначены для текстовых файлов с разделителями (а не для современных форматов, таких как JSON и YAML).
Это побудило меня написать инструмент командной строки, который фокусируется на удобочитаемости, простоте изучения и современных форматах данных, используя при этом экосистему командной строки. Кроме того, он также использует экосистему Python! Встречайте SPyQL - SQL с Python посередине:
SELECT
date.fromtimestamp(purchase_ts) AS purchase_date,
sum_agg(price * quantity) AS total
FROM csv('my_purchases.csv')
WHERE department.upper() == 'IT' and purchase_ts is not Null
GROUP BY 1
ORDER BY 1
TO json
SPyQL в действии
Я думаю, что лучший способ познакомиться с SPyQL и освоиться с командной строкой — это открыть терминал и решить проблему. В данном случае мы попытаемся понять географическое распространение вышек сотовой связи. Начнем!
Настройка
Начнем с установки SPyQL:
$ pip3 install -U spyql
и проверьте его версию:
$ spyql --version
spyql, version 0.8.1
Давайте также установим MatplotCLI, утилиту для создания графиков из командной строки, использующую Matplotlib:
$ pip3 install -U matplotcli
Наконец, мы загрузим некоторые образцы данных (вы также можете скопировать и вставить URL-адрес в свой браузер и загрузить оттуда файл):
$ wget https://raw.githubusercontent.com/dcmoura/blogposts/master/spyql_cell_towers/sample.csv
Этот CSV-файл содержит данные о вышках сотовой связи, которые были добавлены в базу данных OpenCellid 10 сентября 2022 года (OCID-diff-cell- файл export-2022-09-10-T000000.csv из проекта OpenCellid, распространяемый без изменений под Международная лицензия Creative Commons Attribution-ShareAlike 4.0).
Проверка данных
Давайте посмотрим на данные, получив первые 3 строки файла:
$ head -3 sample.csv
radio,mcc,net,area,cell,unit,lon,lat,range,samples,changeable,created,updated,averageSignal
GSM,262,2,852,2521,0,10.948628,50.170324,15762,200,1,1294561074,1662692508,0
GSM,262,2,852,2501,0,10.940241,50.174076,10591,200,1,1294561074,1662692508,0
Эту же операцию можно проделать и с SPyQL:
$ spyql "SELECT * FROM csv LIMIT 2" < sample.csv
или
$ spyql "SELECT * FROM csv('sample.csv') LIMIT 2"
Обратите внимание, что мы предлагаем вам получить 2 строки данных, а не 3 строки файла (где первая является заголовком).
Одним из преимуществ SPyQL является то, что мы можем легко изменить формат вывода. Давайте изменим вывод на JSON и посмотрим на первую запись:
$ spyql "SELECT * FROM csv('sample.csv') LIMIT 1 TO json(indent=2)"
{
"radio": "GSM",
"mcc": 262,
"net": 2,
"area": 852,
"cell": 2521,
"unit": 0,
"lon": 10.948628,
"lat": 50.170324,
"range": 15762,
"samples": 200,
"changeable": 1,
"created": 1294561074,
"updated": 1662692508,
"averageSignal": 0
}
Запрос данных
Сначала посчитаем, сколько записей у нас есть:
$ spyql "SELECT count_agg(*) AS n FROM csv('sample.csv')"
n
45745
Обратите внимание, что функции агрегации имеют суффикс _agg, чтобы избежать конфликтов с функциями Python, такими как min, max и sum. Теперь посчитаем, сколько у нас есть вышек сотовой связи по типу радио:
$ spyql "SELECT radio, count_agg(*) AS n FROM csv('sample.csv') GROUP BY 1
ORDER BY 2 DESC TO pretty"
radio n
------- -----
GSM 31549
LTE 12996
UMTS 1182
CDMA 16
NR 2
Обратите внимание на красивый вывод на печать. Мы можем построить приведенные выше результаты, установив выходной формат в JSON и передав результаты в MatplotCLI:
$ spyql "SELECT radio, count_agg(*) AS n FROM csv('sample.csv') GROUP BY 1
ORDER BY 2 DESC TO json" | plt "bar(radio, n)"
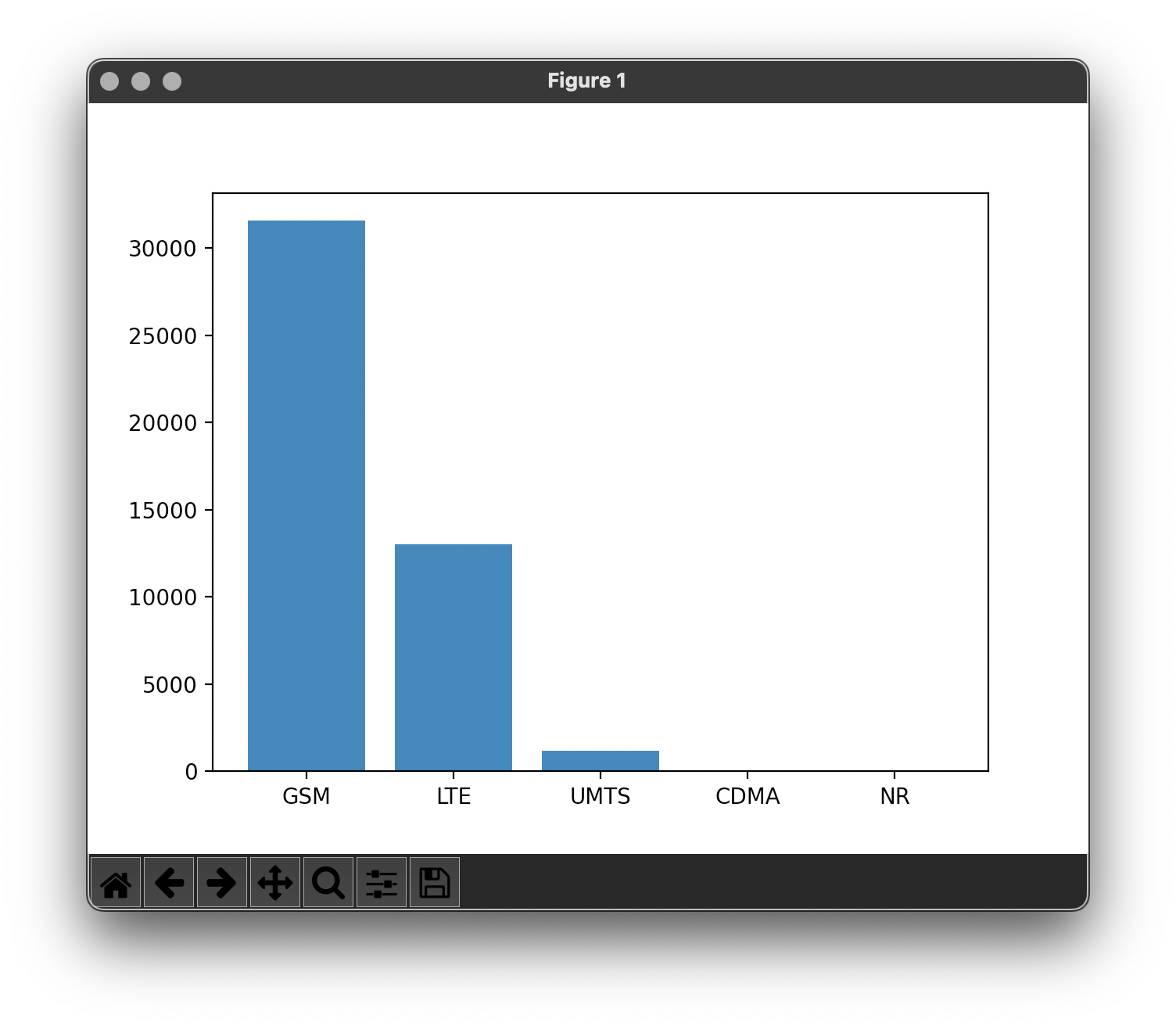
Насколько это было легко? :-)
Запрос данных: более сложный пример
Теперь давайте возьмем первые 5 стран, где в этот день было добавлено больше вышек сотовой связи:
$ spyql "SELECT mcc, count_agg(*) AS n FROM csv('sample.csv') GROUP BY 1 ORDER BY 2 DESC LIMIT 5 TO pretty"
mcc n
----- -----
262 24979
440 5085
208 4573
310 2084
311 799
MCC – мобильный код страны (262 – код Германии). Первая цифра MCC идентифицирует регион. Вот пример из Википедии:
0: Test networks
2: Europe
3: North America and the Caribbean
4: Asia and the Middle East
5: Australia and Oceania
6: Africa
7: South and Central America
9: Worldwide
Давайте скопируем и вставим приведенный выше список регионов и создадим новый файл с именем mcc_geo.txt. На Mac это так же просто, как $ pbpaste > mcc_geo.txt, но вы также можете вставить его в текстовый редактор и сохранить.
Теперь давайте попросим SPyQL открыть этот файл в формате CSV и распечатать его содержимое:
$ spyql "SELECT * FROM csv('mcc_geo.txt') TO pretty"
col1 col2
------ -------------------------------
0 Test networks
2 Europe
3 North America and the Caribbean
4 Asia and the Middle East
5 Australia and Oceania
6 Africa
7 South and Central America
9 Worldwide
SPyQL обнаружил, что разделителем является двоеточие и файл не имеет заголовка. Мы будем использовать синтаксис colN для обращения к N-му столбцу.
Теперь давайте создадим один объект JSON с таким количеством пар "ключ-значение", как и входных строк. Пусть 1-й столбец ввода будет ключом, а 2-й столбец будет значением, и сохраните результат в новый файл:
$ spyql "SELECT dict_agg(col1,col2) AS json FROM csv('mcc_geo.txt') TO json('mcc_geo.json', indent=2)"
Мы можем использовать cat для проверки выходного файла:
$ cat mcc_geo.json
{
"0": "Test networks",
"2": "Europe",
"3": "North America and the Caribbean",
"4": "Asia and the Middle East",
"5": "Australia and Oceania",
"6": "Africa",
"7": "South and Central America",
"9": "Worldwide "
}
Мы объединили все входные строки в словарь Python, а затем сохранили его в виде файла JSON. Попробуйте удалить псевдоним AS json из SELECT, чтобы понять, зачем он нам нужен :-)
Теперь давайте получим статистику по регионам, а не по Центру клиентов. Для этого мы загрузим только что созданный файл JSON (с опцией -J) и выполним поиск в словаре:
$ spyql -Jgeo=mcc_geo.json "SELECT geo[mcc//100] AS region, count_agg(*) AS n
FROM csv('sample.csv') GROUP BY 1 ORDER BY 2 DESC TO pretty"
region n
------------------------------- -----
Europe 35601
Asia and the Middle East 5621
North America and the Caribbean 3247
Australia and Oceania 894
Africa 381
South and Central America 1
Мы выполняем целочисленное деление на 100, чтобы получить первую цифру MCC, а затем ищем эту цифру в только что созданном JSON (который загружается как словарь Python). Вот как мы делаем JOIN в SPyQL через поиск по словарю :-)
Использование библиотек Python в ваших запросах
Еще одно преимущество SPyQL заключается в том, что мы можем использовать экосистему Python. Давайте попробуем сделать еще немного географической статистики. Считаем башни по ячейке H3 (разрешение 5) для Европы. Во-первых, нам нужно установить библиотеку H3:
$ pip3 install -U h3
Затем мы можем преобразовать пары широта-долгота в ячейки H3, подсчитать, сколько башен у нас есть по ячейке H3, и сохранить результаты в CSV:
$ spyql "IMPORT h3 SELECT h3.geo_to_h3(lat, lon, 5) AS cell, count_agg(*) AS n
FROM csv('sample.csv') WHERE mcc//100==2 GROUP BY 1 TO csv('towers_by_h3_res5.csv')"
Визуализировать эти результаты с помощью Kepler довольно просто. Просто зайдите на kepler. gl/demo и откройте вышеуказанный файл. Вы должны увидеть что-то вроде этого:
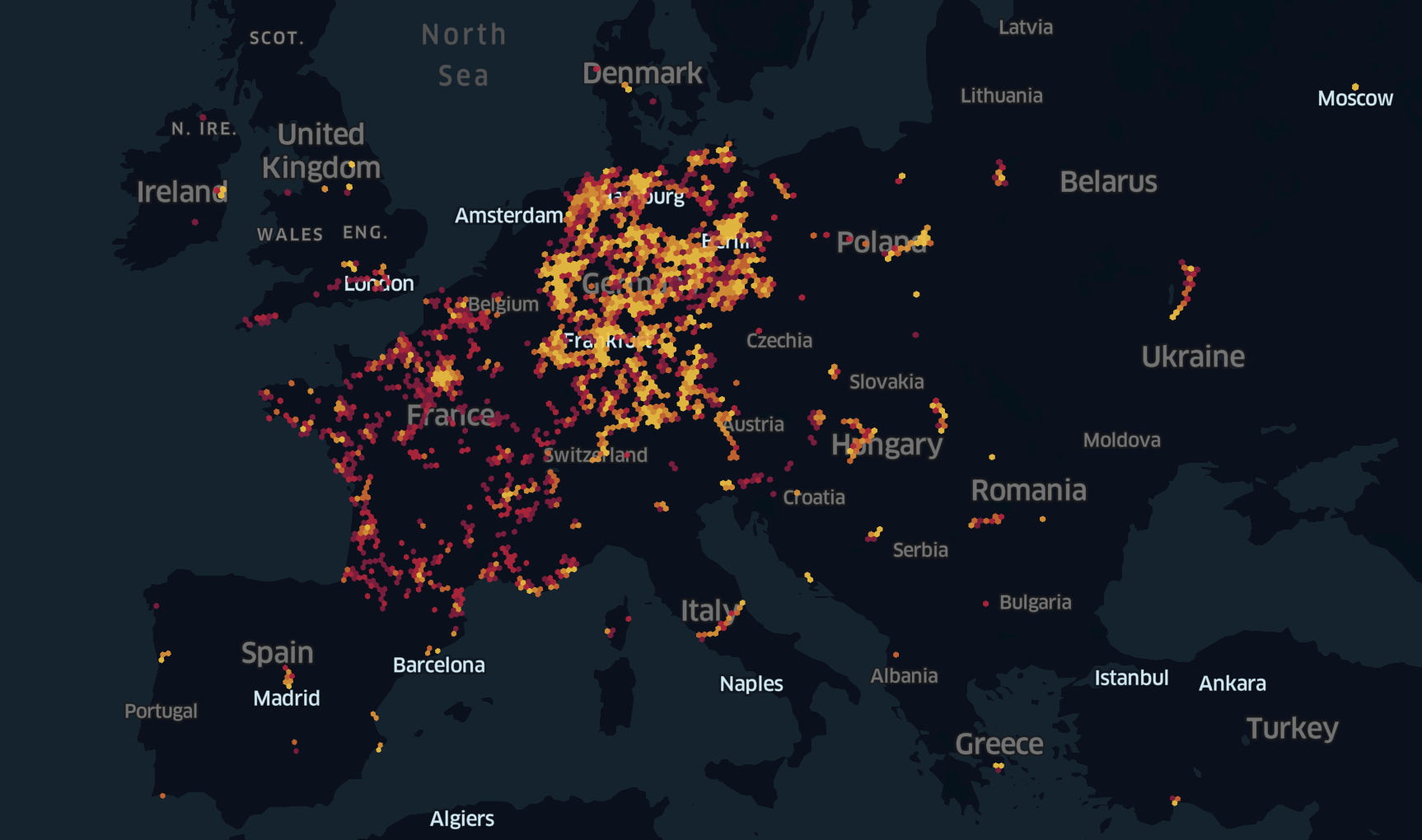
Заключительные слова
Надеюсь, вам понравился SPyQL и я смог показать вам, насколько просто запрашивать данные из командной строки. В этом первом посте о SPyQL мы лишь слегка касаемся поверхности. Мы можем сделать гораздо больше. В этой статье мы почти не использовали экосистемы Shell и Python. И мы работали с небольшим файлом (SPyQL может обрабатывать файлы размером в гигабайт без ущерба для системных ресурсов). Так что следите за обновлениями!
Попробуйте SPyQL и поделитесь со мной своими мыслями. Спасибо!
Ресурсы
- Репозиторий SPyQL: github.com/dcmoura/spyql
- Документация по SPyQL: spyql.readthedocs.io
- Репозиторий MatplotCLI: github.com/dcmoura/matplotcli
Вы можете найти меня в Tweeter, LinkedIn и Vimeo!
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27538)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)