Это вторая часть серии из трех частей, в которой мы рассмотрим, как использовать потоки Redis с NestJS.
Он состоит из 3 частей:
- Настройка приложения NestJS и подключение к Redis
- Заполнение потоков Redis и чтение из них в режиме разветвления
- Использование групп потребителей для обработки одного потока от нескольких участников таким образом, что одно сообщение отправляется и обрабатывается только одним участником (потребителем)
К концу этой серии вы будете обладать знаниями и инструментами, необходимыми для создания собственного приложения NestJS, использующего потоки Redis для обработки данных в реальном времени.
Полный код доступен на github
.Что у нас есть
В части 1 мы создали работающее приложение NestJS, которое может подключиться к серверу Redis. Мы также создали конечную точку /ping-redis для нашего приложения, которая будет вызывать команду ping на сервере Redis и возвращать ответ.
Для удобства разработки мы запускаем наше приложение и сервер Redis в докере. Мы используем Docker Compose для упрощения настройки файла docker-copose.yml.
Теперь мы готовы сосредоточиться на основной теме — использовании потоков Redis.
Что такое потоки Redis?
Прежде чем мы начнем нашу реализацию, важно понять, что такое потоки Redis, и развеять некоторые неправильные представления, которые могли возникнуть относительно того, чем потоки Redis не являются.
Структура данных
По своей сути потоки Redis представляют собой структуру данных, которая содержит данные — сообщения, упорядоченные по идентификаторам сообщений. По умолчанию этот идентификатор представляет собой временную метку, когда эти данные были добавлены в поток (за которым следует порядковый номер, если несколько записей произошли с одной и той же временной меткой).
Не список
Все это очень похоже на список. Однако разница здесь в том, что список может быть извлечен, а потоки — нет. Это связано с тем, что чтение потока не изменяет его. Таким образом, при вызове LPOP или RPOP для списка возвращаемый элемент удаляется. В потоках XREAD оставляет элемент в потоке и может быть прочитан несколько раз.
Не сокет - нет "подписки"
По одному только названию "поток" легко подумать, что это непрерывный "поток" данных, к которому вы подключаетесь и отправляете новые данные после их добавления.
Это поток в том смысле, что данные представляют собой некоторое направление — более старые данные с меньшими идентификаторами и более новые данные с большими идентификаторами. Но чтобы получить к нему доступ, нам нужно будет прочитать его вручную, как и в случае с другими более поверхностными структурами данных, такими как наборы или списки. После выполнения запроса и отправки данных из Redis в приложение команда считается выполненной, и новые данные не будут получены, пока она не будет вызвана снова.
Так что думать о стримах в виде Pub-Sub тоже было бы неправильно. С Pub-sub, как только вы подписываетесь на каналы, соединение блокируется, и все новые опубликованные сообщения будут доставляться. Повторная подписка не требуется.
Основные функции
В основном мы добавляем в поток (XADD) и читаем из него (XREAD, XRANGE XREADGROUP). Существует также функция удаления (XDEL), но в большинстве случаев мы думаем о потоке только как о добавлении.
Управление памятью
Чтобы избежать использования всего пространства и случайного удаления данных, длина потоков управляется путем их обрезки. Это можно сделать вручную с помощью XTRIM или мы можем передать ответственность Redis с помощью ограниченных потоков — добавив параметр MAXLEN при использовании XADD.
Добавление в потоки
Наконец, давайте вернемся к реализации потоков в нашем приложении NestJS. Давайте создадим метод для добавления сообщения в поток:
// redis.service.ts
// --snip--
public async addToStream({
fieldsToStore,
streamName,
}: AddToStreamParams): Promise<string> {
// Converting object to record to store in redis
const messageObject = Object.entries(fieldsToStore).reduce(
(acc, [key, value]) => {
if (typeof value === 'undefined') {
return acc;
}
acc[key] = typeof value === 'string' ? value : JSON.stringify(value);
return acc;
},
{} as Record<string, string>,
);
// Adding to stream with trimming - approximately max 100 messages
return this.redis.xAdd(streamName, '*', messageObject, {
TRIM: {
strategy: 'MAXLEN',
strategyModifier: '~',
threshold: 100,
},
});
}
Как видите, мы определили интерфейс для параметров этого метода:
// interfaces.ts
export interface AddToStreamParams {
fieldsToStore: Record<string, any>;
streamName: string;
}
Мы возьмем имя потока, в который мы хотим добавить данные, и укажем данные как POJO с именем fieldsToStore
Далее у нас есть код преобразования, который преобразует наш объект любой глубины в пары ключ-значение строкового типа. Позже, при чтении данных, мы вернемся к исходному POJO:
// redis.service.ts
// --snip--
const messageObject = Object.entries(fieldsToStore).reduce(
(acc, [key, value]) => {
if (typeof value === 'undefined') {
return acc;
}
acc[key] = typeof value === 'string' ? value : JSON.stringify(value);
return acc;
},
{} as Record<string, string>,
);
// --snip--
Затем мы выполняем вызов службы Redis со следующими параметрами:
// redis.service.ts
// --snip--
return this.redis.xAdd(streamName, '*', messageObject, {
TRIM: {
strategy: 'MAXLEN',
strategyModifier: '~',
threshold: 100,
},
});
// --snip--
* streamName — имя нашего потока, к которому мы хотим добавить
* * — звездочка указывает, что Redis автоматически генерирует уникальный идентификатор (на основе метки времени). Здесь мы можем установить свой собственный идентификатор, если захотим.
* messageObject — пары ключ-значение, содержащие данные, которые мы хотим сохранить
* Параметры:
* TRIM — как упоминалось ранее, мы не хотим обрабатывать обрезку вручную, поэтому указываем, что хотим, чтобы Redis сам обрезал поток. Сюда входят дополнительные опции:
* strategy MAXLEN — здесь мы указываем, что хотим обрезать, когда поток достигает максимальной длины threshold. Другим вариантом может быть MINID, где порог указывает наименьший сохраняемый идентификатор. Остальные помечены для выселения.
* strategyModifier ~ — это говорит Redis, что мы не хотим быть строгими по размеру, и Redis может некоторое время превышать пороговое значение, но обрезка в конечном итоге случаться. Это оптимизирует Redis для выполнения выселения в наиболее удобное время, а не немедленно.
* threshold 100 — это максимальная длина потока, который нам нужен. В случае MINID это будет наименьший идентификатор, который необходимо сохранить. А так как у нас есть модификатор стратегии ~, это приблизительное значение.
Поэтому мы бы прочитали это так: Обрезать поток, если длина (MAXLEN) потока достигла примерно (~) 100.
Обработчик потока
Поскольку мы будем делать больше с нашими потоковыми данными и хотим сохранить базовую функциональность вызовов сервера Redis в RedisService, мы создадим новую службу с именем StreamHandlerService. для дополнительной обработки потоков.
Сейчас мы просто добавим «сквозной» метод addToStream, который будет вызывать метод RedisService addToStream.
Чтобы сгенерировать его, мы вызовем: nest g service redis/stream-handler
// stream-handler.service.ts
import { Injectable } from '@nestjs/common';
import { RedisService } from './redis.service';
@Injectable()
export class StreamHandlerService {
constructor(private readonly redisService: RedisService) {}
public addToStream(fieldsToStore: Record<string, any>, streamName: string) {
return this.redisService.addToStream({ fieldsToStore, streamName });
}
}
А так как мы не хотим предоставлять доступ к нашему RedisService другим модулям и хотим, чтобы они взаимодействовали с StreamHandlerService, мы переместим в него функцию ping-вызова и удалим экспорт из модуль.
// stream-handler.service.ts
// --snip--
public ping() {
return this.redisService.ping();
}
// --snip--
Чтобы использовать его в других модулях, нам нужно его экспортировать:
// redis.module.ts
import { Module } from '@nestjs/common';
import { redisClientFactory } from './redis-client.factory';
import { RedisService } from './redis.service';
import { StreamHandlerService } from './stream-handler.service';
@Module({
providers: [redisClientFactory, RedisService, StreamHandlerService],
exports: [StreamHandlerService], // Removed RedisService from exports
})
export class RedisModule {}
А в AppService вместо этого мы будем вызывать ping из StreamHandlerService:
// app.service.ts
// --snip--
constructor(private readonly streamService: StreamHandlerService) {} // changed from RedisService to StreamHandlerService
redisPing() {
return this.streamService.ping(); // changed here as well
}
// --snip--
:::информация
Теоретически другим модулям не должно быть дела до того, вызываем ли мы Redis, RabbitMQ, Kafka или еще что-то. . Он должен только знать, что это поток, и мы получаем конкретные данные, вызывая общедоступные методы в экспортируемых сервисах. Таким образом, мы можем легко изменить нашу реализацию потоков без необходимости изменения других частей кода — они становятся несвязанными. Поскольку это проект о Redis и потоках Redis, мы назвали этот модуль RedisModule, но в дополнение к предыдущему обучению в реальной жизни было бы более разумно назвать его StreamModule или MessagingModule или что-то еще, в зависимости от того, для чего будут использоваться эти потоки.
:::
Заполнение Redis сообщениями
Давайте воспользуемся нашим методом addToStream для заполнения нашего Redis.
Мы могли бы пойти по тому же пути, что и с ping, и предоставить его конечной точке нашего API, но на этот раз, поскольку мы хотим «симулировать» поток данных, мы будем вызывать этот метод с интервалом, чтобы у нас был непрерывный поток данных в наш поток.
Давайте добавим его в наш AppService:
// app.service.ts
// --snip--
@Injectable()
export class AppService implements OnModuleInit, OnModuleDestroy {
private interval: NodeJS.Timeout = null;
// --snip--
private populateStream() {
this.interval = setInterval(() => {
this.streamService.addToStream(
{
hello: 'world',
date: new Date(),
nestedObj: { num: Date.now() % 100 },
},
EXAMPLE_STREAM_NAME,
);
}, 1000);
}
async onModuleInit() {
this.populateStream();
}
onModuleDestroy() {
clearInterval(this.interval);
}
}
Как видите, мы создали метод populateStream, который добавит некоторые фиктивные данные в наш поток.
EXAMPLE_STREAM_NAME — это просто константа имени потока, которую мы определили в файле constants.ts и импортировали сюда:
// constants.ts
export const EXAMPLE_STREAM_NAME = 'example-stream';
Мы создали интервал, который мы вызываем в событии образа жизни onModuleInit, и очищаем его в нашем событии жизненного цикла onModuleDestroy, чтобы не оставлять оборванных ссылок. Это добавит сообщение в наш поток Redis каждые 1000 мс.
Чтобы убедиться в этом, давайте теперь создадим способ чтения из потока.
Чтение из потока
Для чтения из потоков Redis мы можем использовать команды XREAD или XRANGE (и REVXRANGE). Поскольку целью этого проекта является чтение новых сообщений, для достижения этой цели можно использовать обе команды. В этой статье мы будем использовать XREAD.
Давайте добавим метод, который оборачивает вызов команды XREAD и дополнительно обрабатывает ошибки:
// redis.service.ts
// --snip--
public async readStream({
streamName,
blockMs,
count,
lastMessageId,
}: ReadStreamParams): Promise<RedisStreamMessage[] | null> {
try {
const response = await this.redis.xRead(
commandOptions({ isolated: true }), // uses new connection from pool not to block other redis calls
[
{
key: streamName,
id: lastMessageId,
},
],
{ BLOCK: blockMs, COUNT: count },
);
const { messages } = response?.[0]; // returning first stream (since only 1 stream used)
return messages || null;
} catch (error) {
if (error instanceof ClientClosedError) {
console.log(`${error.message} ...RECONNECTING`);
await this.connectToRedis();
return null;
}
console.error(
`Failed to xRead from Redis Stream: ${error.message}`,
error,
);
return null;
}
}
Разберем этот код:
Во-первых, обратите внимание, что мы добавили интерфейс параметров ReadStreamParams:
// interfaces.ts
export interface ReadStreamParams {
streamName: string;
blockMs: number;
lastMessageId: string;
}
// --snip--
а также мы определили наше ответное сообщение RedisStreamMessage. Поскольку в node-redis мало экспорта типов, нам нужно извлечь его самостоятельно:
// redis-client.types
// --snip--
export type RedisStreamMessage = Awaited<
ReturnType<RedisClient['xRead']>
>[number]['messages'][number];
// --snip--
В блоке try у нас есть вызов нашей команды:
// --snip--
const response = await this.redis.xRead(
commandOptions({ isolated: true }), // uses new connection from pool not to block other redis calls
[
{
key: streamName,
id: lastMessageId,
},
],
{ BLOCK: blockMs, COUNT: count },
);
const { messages } = response?.[0]; // returning first stream (since only 1 stream used)
return messages || null;
} catch (error) {
// --snip--
Сначала мы используем опцию команды вызова, чтобы запустить ее изолированно commandOptions({isolated: true}).
Это необходимо, потому что мы собираемся БЛОКИРОВАТЬ соединение. Это означает, что после того, как этот командный вызов установит соединение с сервером Redis, если результаты не будут в Redis на момент поступления вызова, он будет ожидать указанное количество времени (параметр BLOCK ) и, если в течение этого периода придут данные, соответствующие запросу, они будут возвращены немедленно, либо дождутся окончания указанного времени и ничего не вернут.
В это время соединение используется, и никакие другие команды не могут быть вызваны. По сути, наша команда БЛОКИРУЕТ соединение.
Если бы мы хотели создать несколько вызовов, мы бы быстро столкнулись с задержками и проблемами с производительностью. Для этого мы можем использовать изолированное выполнение. Это означает, что node-redis будет создавать несколько подключений, используя общий пул ресурсов под капотом, поэтому у нас будет несколько подключений для параллельного использования.
Далее мы говорим, какие потоки мы хотим читать и начиная с какого ID. Нам нужно передать его в массиве, так как мы можем вызывать несколько потоков за один вызов. Мы будем обрабатывать несколько потоков в одном запросе за рамками этой статьи:
[
{
key: streamName,
id: lastMessageId,
},
],
Далее мы передаем необязательные параметры:
{ BLOCK: blockMs, COUNT: count },
* BLOCK - время блокировки в миллисекундах. **Если указан 0, он будет блокироваться на неопределенный срок, пока не будет возвращено хотя бы 1 сообщение.
* COUNT — это максимальное число, которое мы вернем. Если на сервере Redis доступно меньше сообщений, он не будет ждать совпадения счетчика, а вернет столько сообщений, сколько есть.
Далее разбираем данные:
const { messages } = response?.[0];
return messages || null;
Поскольку мы вызвали только 1 поток, массив response всегда будет иметь длину 1. Все сообщения возвращаются в объекте messages. И, наконец, мы возвращаем либо массив потоковых сообщений, либо null.
Здесь же мы можем обрабатывать некоторые начальные ошибки:
// --- snip---
} catch (error) {
if (error instanceof ClientClosedError) {
console.log(`${error.message} ...RECONNECTING`);
await this.connectToRedis();
return null;
}
console.error(
`Failed to xRead from Redis Stream: ${error.message}`,
error,
);
return null;
}
В случае ошибки мы вернем значение null.
Если у нас есть ClientClosedError, бесполезно пытаться что-то получить дальше, поэтому мы пытаемся повторно подключиться к Redis.
// --- snip---
private async connectToRedis() {
try {
// Try to reconnect only if the connection socket is closed. Else let it be handled by reconnect strategy.
if (!this.redis.isOpen) {
await this.redis.connect();
}
} catch (error) {
console.error(
`[${error.name}] ${error.message}`,
error,
);
}
}
Мы проверяем isOpen, чтобы узнать, открыт ли сокет. Если это так, мы будем доверять стратегии повторного подключения, чтобы выполнить свою работу и повторно подключиться к клиенту. Если это не так, то мы пытаемся сделать это сами. И вот как мы можем получить одно сообщение из потока. Давайте расширим это и добавим возможность чтения нескольких сообщений.
Открытие чтения для нашего API
Открытие потока Redis для нашего API аналогично тому, что мы делали с ping.
Давайте добавим еще один метод в наш StreamHandlerService:
//stream-handler.service.ts
// --- snip --
public readFromStream(streamName, count) {
return this.redisService.readStream({
streamName,
blockMs: 0, // 0 = infinite blocking until at least one message is fetched, or timeout happens
count, // max how many messages to fetch at a time
lastMessageId: '$',
});
}
Простой метод, в котором мы передаем streamName потока, который мы хотим прочитать, и count сообщений, которые мы хотели бы получить. Как упоминалось ранее, COUNT на самом деле является «максимальным количеством», поскольку, если сообщений в потоке меньше или совсем нет, Redis вернет от 1 до count количества сообщений.
Мы используем специальный идентификатор $ — он представляет «все, что приходит после запроса XREAD».
Теперь давайте прочитаем одно сообщение:
// app.service.ts
// --snip--
public getSingleNewMessage() {
return this.streamService.readFromStream(EXAMPLE_STREAM_NAME, 1);
}
// --snip--
Опять же, используя EXAMPLE_STREAM_NAME — тот же поток, который мы заполняем, и установив для count значение 1.
И, наконец, давайте добавим новую конечную точку в наш контроллер:
// app.controller.ts
// --snip--
@Get('message')
getMessage() {
return this.appService.getSingleNewMessage();
}
// --snip--
Теперь, вызывая конечную точку, мы должны увидеть одно сообщение, сгенерированное нашим методом populateStream:
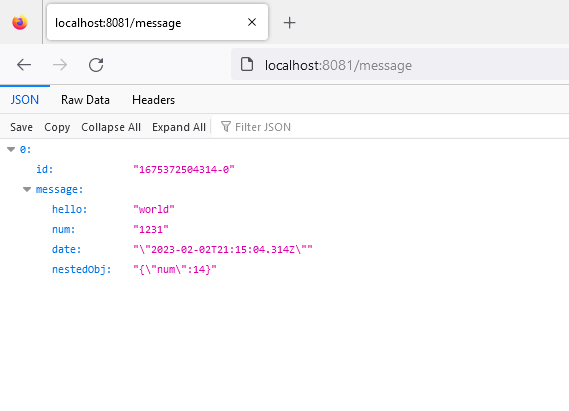
Обработка результатов в виде потока
Получить одно сообщение относительно просто.
Но как нам получить несколько сообщений?
Что, если мы хотим получить определенное количество сообщений, например ровно 3?
Сначала это может показаться простым — просто установите count количество сообщений, которое вы хотите. Но помните - COUNT не гарантирует, что мы получим точное количество сообщений. Это скорее "максимальный счет". Поэтому у вас может возникнуть соблазн вызвать XREAD несколько раз. Но поскольку мы передаем $ в качестве идентификатора последнего сообщения, мы можем пропустить некоторые сообщения, которые приходят между нашими вызовами.
Это означает, что нам нужно запомнить наш последний идентификатор.
А что, если мы хотим читать из потока непрерывно и бесконечно?
Все это создает дополнительную сложность, с которой нам необходимо справиться.
Генераторы
Генераторы — ценный инструмент, который должен быть в нашем наборе инструментов. Здесь они пригодятся, когда мы хотим лениво получить данные из какого-то внешнего ресурса (Redis).
Не буду заострять внимание на "что и как" генераторов. Если вы не использовали их раньше, я рекомендую вам ознакомиться с справочником по генераторам JavaScript. и книга доктора Акселя Раушмайера "JavaScript для нетерпеливых программистов" по асинхронным генераторам.
Основная функция, которую мы можем сделать, — это создать бесконечный цикл, который мы можем остановить и перезапустить, когда захотим и в котором будем нуждаться.
Давайте добавим новый метод в наш StreamHandlerService:
// stream-handler.service.ts
export class StreamHandlerService implements OnModuleDestroy {
private isAlive = true;
onModuleDestroy() {
this.isAlive = false;
}
// --snip--
public async *getStreamMessageGenerator(
streamName: string,
count: number,
): AsyncRedisStreamGenerator {
// Start with latest data
let lastMessageId = '$';
while (this.isAlive) {
const response = await this.redisService.readStream({
streamName,
blockMs: 0, // 0 = infinite blocking until at least one message is fetched, or timeout happens
count, // max how many messages to fetch at a time
lastMessageId,
});
// If no messages returned, continue to next iteration without yielding
if (!response || response.length === 0) {
continue;
}
// Update last message id to be the last message returned from redis
lastMessageId = response[response.length - 1].id;
for (const message of response) {
yield message;
}
}
}
// --snip--
Давайте разберем то, что мы написали:
Во-первых, вы заметите, что мы добавили новое логическое значение isAlive, которое мы изначально установим в true, и только во время уничтожения модуля мы установим его в ложь. Это будет служить циклом while-true, из которого мы сможем выйти, когда приложение завершит работу.
Также для нашего удобства мы создали новый тип AsyncRedisStreamGenerator
// redis-client.type.ts
// --snip--
export type AsyncRedisStreamGenerator = AsyncGenerator<
RedisStreamMessage,
void,
unknown
>;
// --snip--
Это асинхронный генератор, который выдает или создает значения RedisStreamMessage, не возвращает ничего (void) при возврате и принимает unknown< /code> сообщения, так как мы ничего не будем передавать в метод next нашего генератора.
Мы будем вызывать метод readStream в бесконечном цикле:
let lastMessageId = '$';
while (this.isAlive) {
const response = await this.redisService.readStream({
streamName,
blockMs: 0, // 0 = infinite blocking until at least one message is fetched, or timeout happens
count, // max how many messages to fetch at a time
lastMessageId,
});
// -- snip --
}
Как и в нашем предыдущем примере, мы начнем считывать данные только тогда, когда генератор будет создан и вызовет поток, используя $ в качестве lastMessageId.
Остальное тоже самое, что и в предыдущем примере, за исключением того, что мы вызываем его в цикле.
Далее мы обработаем случай, когда получим пустой ответ. Мы просто перейдем к следующей итерации без каких-либо результатов
// If no messages returned, continue to next iteration without yielding
if (!response || response.length === 0) {
continue;
}
Если у нас есть ответы, мы их обработаем:
// Update last message id to be the last message returned from redis
lastMessageId = response[response.length - 1].id;
for (const message of response) {
yield message;
}
Чтобы избежать пробелов в сообщениях и прочитать все сообщения с момента запуска этого генератора, мы обновим переменную lastMessageId последним полученным сообщением.
Поскольку у нас есть count, мы получим массив размеров от 1 до count с сообщениями. Однако этот генератор создает только одно сообщение за раз. Поэтому мы будем перебирать массив и выдавать только одно сообщение за раз.
Это что касается генераторной части. Давайте посмотрим, как мы можем использовать его для решения наших предыдущих вопросов:
Чтение нескольких результатов
Теперь давайте воспользуемся нашим генератором для создания нескольких результатов, создав новый метод в AppService
// app.service.ts
// --snip--
public async getMultipleNewMessages(count: number) {
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
count,
);
const messages: Record<string, string>[] = [];
let counter = 0;
for await (const messageObj of generator) {
messages.push(this.parseMessage(messageObj.message));
counter++;
if (counter >= count) {
break;
}
}
return messages;
}
// --snip--
Сначала мы создаем генератор:
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
count,
);
Мы передаем ему наш счет для «оптимистичной» выборки. Мы постараемся получить все за один вызов Redis. Но если этого не произойдет, мы будем вызывать Redis столько раз, сколько потребуется.
Мы создаем массив для сбора наших сообщений:
const messages: Record<string, string>[] = [];
и определите счетчик, где мы будем подсчитывать, сколько мы получили.
Одной из удобных особенностей генераторов является то, что они являются итерируемыми, поскольку реализуют метод @@iterator. Таким образом, мы можем вызвать для них for..of. В этом случае, поскольку генератор является асинхронным, он для ожидания .. of
for await (const messageObj of generator) {
messages.push(this.parseMessage(messageObj.message));
counter++;
if (counter >= count) {
break;
}
}
return messages;
Как только счет достигнут, мы просто прерываем цикл и возвращаем собранные сообщения.
Поскольку Redis хранит все значения в виде строк, мы также создали общий метод анализатора:
//app.service.ts
// --snip--
private parseMessage(message: Record<string, string>) {
return Object.entries(message).reduce((acc, [key, value]) => {
try{
acc[key] = JSON.parse(value);
}catch(e){
acc[key] =value
}
return acc;
}, {});
}
// --snip--
Чтобы убедиться, что мы действительно получаем указанное количество сообщений, мы создадим новую конечную точку /messages, откуда мы получим 3 сообщения:
// app.controller.ts
// --snip--
@Get('messages')
getMessages() {
return this.appService.getMultipleNewMessages(3);
}
// --snip--
Опять же, когда мы вызываем нашу только что созданную конечную точку, мы действительно получаем 3 сообщения:
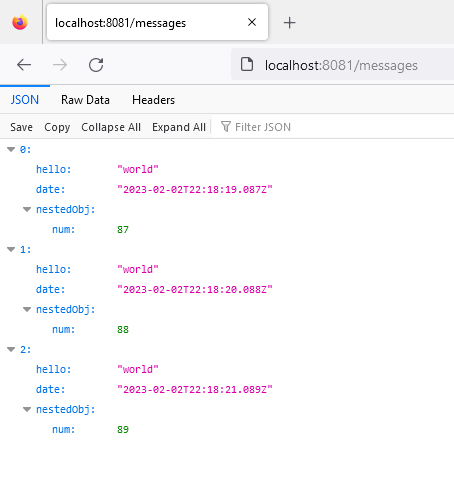
Непрерывное чтение потока
Самая большая сила потока Redis заключается в том, что он используется как непрерывный поток данных. Для этого мы можем повторно использовать наш генератор:
// app.service.ts
// --snip--
private isAlive = true;
// --snip--
async onModuleInit() {
// --snip--
this.continuousReadMessages();
}
onModuleDestroy() {
// --snip--
this.isAlive = false;
}
// --snip--
private async continuousReadMessages() {
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
3,
);
for await (const messageObj of generator) {
console.log(
`Got message with ID: ${messageObj.id}`,
JSON.stringify(this.parseMessage(messageObj.message), undefined, 2),
);
if (!this.isAlive) {
break;
}
}
}
// --snip--
Как и в случае с получением нескольких сообщений, мы начинаем с создания генератора:
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
10,
);
Мы даем ему произвольное число для count, так как мы хотим попытаться получить несколько ответов за один вызов Redis, если это возможно.
А затем мы просто делаем все, что нам нужно, с данными в цикле. Итак, здесь просто регистрируется сообщение.
И разорвав цикл после уничтожения модуля, у нас не будет висящих ссылок, и мы сможем остановить наш цикл.
for await (const messageObj of generator) {
console.log(
`Got message with ID: ${messageObj.id}`,
JSON.stringify(this.parseMessage(messageObj.message), undefined, 2),
);
if (!this.isAlive) {
break;
}
}
И мы вызываем этот метод один раз при инициализации нашего модуля, так же, как мы делали с потоком заполнения:
async onModuleInit() {
this.populateStream();
this.continuousReadMessages();
}
И в нашей консоли мы должны увидеть, что мы получаем сообщения непрерывно
...
app | Got message with ID: 1675377159049-0 {
app | "hello": "world",
app | "date": "2023-02-02T22:32:39.048Z",
app | "nestedObj": {
app | "num": 48
app | }
app | }
app | Got message with ID: 1675377160050-0 {
app | "hello": "world",
app | "date": "2023-02-02T22:32:40.050Z",
app | "nestedObj": {
app | "num": 50
app | }
app | }
...
Рефакторинг для одного сообщения
Поскольку мы используем генератор для обработки потоковых сообщений, давайте реорганизуем наш пример выборки одного сообщения.
// app.service.ts
// --snip--
public async getSingleNewMessage() {
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
1,
);
const messageObj = await generator.next();
if (!messageObj.done && messageObj.value) {
return this.parseMessage(messageObj.value.message);
}
}
// --snip--
Как и во всех примерах, мы создаем генератор в нашем потоке EXAMPLE_STREAM_NAME, на этот раз с count 1.
const generator = this.streamService.getStreamMessageGenerator(
EXAMPLE_STREAM_NAME,
1,
);
Поскольку нам нужно только одно сообщение, нам не нужно использовать цикл. Вместо этого мы вызываем метод next вручную:
const messageObj = await generator.next();
а затем обработать ответ - если генератор не вернулся/завершился - это не done и у нас есть сообщение t return, мы разбираем сообщение и возвращаем его клиенту:
if (!messageObj.done && messageObj.value) {
return this.parseMessage(messageObj.value.message);
}
Все остальное для клиента остается прежним, и возвращается тот же результат.
Это конец второй части серии из трех частей. Мы использовали то, что создали в часть 1.
В результате у вас должно получиться приложение, способное получать один или несколько ответов и постоянно получать новые результаты из потока Redis.
В части 3 мы рассмотрим, как мы можем использовать группы потребителей для разделения сообщений между несколькими потребителями, чтобы каждый из них получал уникальный набор сообщений (не так, как сейчас, где, если бы мы подключили больше клиентов, все клиенты получили бы получение всех сообщений).