Когда у нас есть несколько каналов привлечения клиентов и маркетинговый бюджет быстро растет, мы хотим как можно скорее узнать, какой из новых каналов стоит вложений. Моделирование Lifetime Value (LTV) может быть полезным инструментом для такой задачи.
В этой статье я хотел бы поделиться случаем из моей практики прогноза LTV для розничных клиентов в финансовой отрасли, который изменил подход компании к распределению маркетингового бюджета (для привлечения клиентов).
Проблема
Представьте, что вы работаете в быстрорастущей компании, которая привлекает новых клиентов по разным каналам. Конечно, многие из этих каналов не генерируют новых клиентов бесплатно: за рекламу, будь то контекстная или медийная реклама, переходы с партнерских сайтов, упоминания в блогах, посты в соцсетях и т. д., нужно платить.
Когда наш маркетинговый бюджет намного ниже нашей прибыли, мы можем даже не заботиться о затратах на приобретение. Но когда наш бизнес находится в стадии роста, привлечение клиентов обходится дорого, и получение максимальной отдачи от каждого доллара, вложенного в привлечение клиентов, является вопросом жизни и смерти.
Вы можете сказать: «Хорошо, если мы тратим много, мы должны сравнить так называемую CAC (стоимость привлечения клиента) с наша средняя прибыль, полученная от среднего клиента, поступающего из этого конкретного канала».
И вы абсолютно правы:

Весь беспорядок возникает, когда дело доходит до расчета средней прибыли, полученной от клиентов, пришедших по определенным каналам:
* В финансовой сфере LTV клиента может существенно различаться. Вот почему мы не можем просто полагаться на исторические средние значения. * Если время жизни типичного клиента велико (скажем, год), нам нужно слишком долго ждать, чтобы понять среднюю ценность нового канала для клиента. * Если канал не новый, привлечение клиентов со временем может ухудшиться. Если это произойдет, мы хотим получить оповещение как можно скорее
Эти проблемы возникли в финансовой компании, где я работал, и я хотел бы поделиться тем, как я подошел к их решению, создав систему, которая могла бы оценивать LTV и CAC для новых клиентов всего через несколько дней после запуска нового канала привлечения.
Как проблема была решена
С технической точки зрения, мы хотели создать модель, которая могла бы прогнозировать пожизненную ценность клиентов для новых клиентов, поступающих по каналам привлечения (или подканалам, таким как определенные маркетинговые кампании). Как правило, мы ищем ситуации, когда:
Постоянная ценность > 3 х САС
Что такое ЦАК? Расчет этого показателя прост:
CAC = стоимость канала / количество клиентов из канала
Что такое LTV?
LTV = общее количество (PV(доход)) / количество клиентов из канала
Доход представляет собой сумму денег, которую клиент получает за всю жизнь. Обсуждение того, как рассчитать выручку (или должна ли она быть прибылью со всеми распределениями затрат), выходит за рамки этой истории. Конкретная методология в основном зависит от рассматриваемой бизнес-модели и может даже заслужить дополнительную статью.
n PV означает текущую стоимость, которая применяется для дисконтирования Дохода по определенной ставке (мы помним временную стоимость денег: затраты на привлечение клиентов оплачиваются сегодня, а клиенты приносят доход в течение некоторого времени). рамка). Вы можете легко погуглить, как рассчитать PV на основе будущих денежных потоков. п
Создание модели для прогнозирования LTV
У нас всегда есть все необходимые данные для расчета CAC. Это не относится к LTV. Для оценки этого показателя нам необходимо спрогнозировать будущий доход для каждого клиента:
Прогноз дохода = f(Xi)
Где Xi обозначает все параметры клиента, которые у нас есть, а именно:
* Демографический профиль клиента (возраст, страна, регион и т. д.), хранящийся в наших внутренних системах. * Онлайн-поведение на нашем веб-сайте (мы отслеживаем его и храним в базе данных BigQuery Cloud DataBase) * Поведение в первые дни (например, сумма депозита, первые транзакции и т. д.), которое мы также храним в наших внутренних системах.
Очевидно, у нас есть исторические данные для (Revenue_i, X_i) для всех наших существующих клиентов, что дает нам возможность строить модели машинного обучения, прогнозирующие Revenue_i на основе X_i. Нам нужно определить временные рамки для прогнозирования доходов. В нашем случае это полгода. Этот параметр может значительно отличаться для других случаев и подлежит обсуждению.
n ПРИМЕЧАНИЕ: Нам также необходимо определить период после регистрации клиента, для которого мы строим наш массив параметров и делаем первый прогноз. Чем короче этот период, тем быстрее мы сможем оценить средний LTV для канала, чтобы сравнить его с CAC. Но с другой стороны, чем короче этот период, тем меньше информации о клиенте для обучения нашей модели машинного обучения и тем меньше у нас предсказательной силы.
В нашем случае три дня были довольно хорошим компромиссом (обозначим его T = 3). Мы также должны помнить, что нам всегда нужно собирать статистически значимое количество клиентов для расчета среднего LTV.
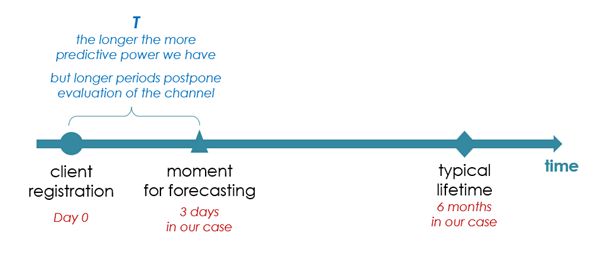
На практике задача решалась несколько иначе, чем объяснено здесь, но это не меняет всего подхода: у нас всегда есть какие-то «старые» клиенты, чем определено X дней для таймфрейма, поэтому прогнозы по ним могут быть лучше просто потому, что у нас есть больше информации об их поведении.
Таким образом, имея исторические данные (Revenue_i, X_i) для тысяч наших существующих и бывших клиентов, мы можем обучить алгоритм машинного обучения, такой как повышение градиента (или нейронную сеть, если она лучше соответствует данным), для выполнения прогнозирования. Выбор модели и настройка в настоящее время стали довольно простой рутиной. Вы можете просто погуглить примеры xgboost или catboost и найти сквозной код на первой странице результатов поиска.
Развертывание модели
Теперь у нас есть модель, которая делает прогнозы (не забудьте провести тестирование на исторических данных и оценить ее эффективность для данных вне выборки). У вас есть несколько вариантов развертывания:
* Запуск модели непосредственно в вашем DWH (хранилище данных, где вы собираете данные из всех источников данных). ). Это нормально для простых моделей, которые вы можете «жестко закодировать» в SQL. * Расписание запуска модели на локальной машине, подключенной к таблице DWH с данными. Этот способ хорош для быстрого старта, но имеет проблемы со стабильностью и масштабированием. * Организация среды выполнения модели Python, которая может планировать подключение к DWH для извлечения данных и загрузки прогнозов. Этот способ предпочтительнее, но и самый трудоемкий.
В нашем случае был выбран вариант №2 (запуск модели на локальном компьютере).
Заключение
Имея модель прогнозирования дохода, мы можем легко рассчитать ожидаемую LTV для каждого клиента = PV (прогноз дохода) за 6-месячный период времени. Как только у нас будет достаточно клиентов из канала (или маркетинговой кампании), мы сможем сравнить средний LTV с CAC и принять решение, сохранять ли этот канал (или кампанию) или нет. В нашем случае нам удалось сократить оценку канала в среднем до 3 дней (вместо 6 месяцев ожидания, чтобы понять реальную ценность каждого клиента).
P.S. Это может показаться решенной задачей, но на самом деле это только начало пути. Затем нам нужно начать отслеживать производительность нашей модели, регулярно переобучать ее и в какой-то момент, возможно, даже подвергнуть сомнению весь подход.