
Использование LLMS для классификации вниз по течению: приглашение, вербализируйте, тренируется
11 июня 2025 г.Авторы:
(1) Горан Мурич, Inferlink Corporation, Лос -Анджелес, (Калифорния gmuric@inferlink.com);
(2) Бен Зал, Inferlink Corporation, Лос -Анджелес, Калифорния (bdelay@inferlink.com);
(3) Стивен Минтон, корпорация Inferlink, Лос -Анджелес, Калифорния (sminton@inferlink.com).
Таблица ссылок
Аннотация и 1 введение
1.1 Мотивация
2 Связанная работа и 2,1 методы подсказки
2.2 Внутреннее обучение
2.3 модели интерпретируемость
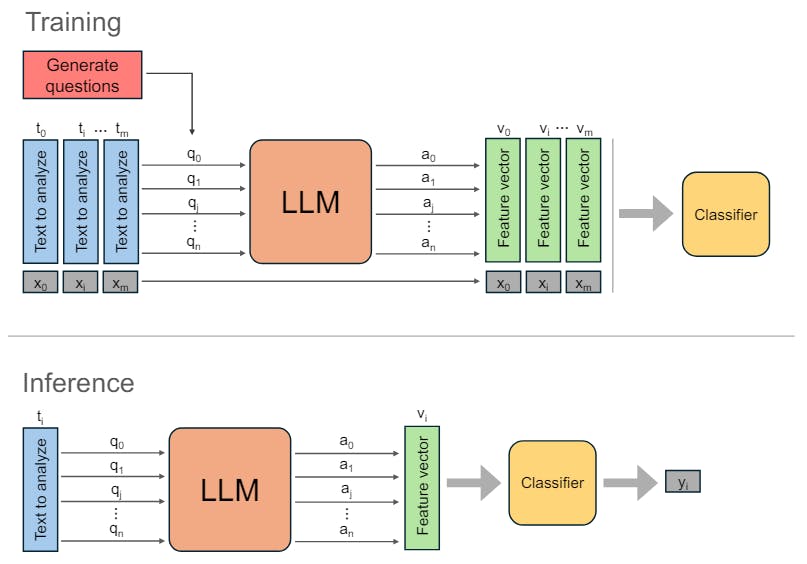
3 Метод
3.1 Создание вопросов
3.2 Подсказка LLM
3.3. Сорбализация ответов и 3.4 Обучение классификатора
4 данные и 4.1 клинические испытания
4.2 Корпус независимости Каталонии и 4.3 Корпус обнаружения климата
4.4 Данные по медицинскому здоровью и 4.5 Данные Европейского суда по правам человека (ECTHR)
4.6 Набор данных Necure-Tos
5 экспериментов
6 результатов
7 Обсуждение
7.1 Последствия для интерпретации модели
7.2 Ограничения и будущая работа
Воспроизводимость
Подтверждение и ссылки
Вопросы, используемые в методе ICE-T
3.2 Подсказка LLM
LLMs представлены в два раза. Во -первых, им предложено получить набор вторичных вопросов Q, как описано в разделе 3.1. Во -вторых, для каждого документа мы представляем LLM с документом и соответствующими вторичными вопросами.
Затем, для каждого вопроса Qi вывод AI LLM собирается, создавая набор выходов для каждого документа. Текстовым выходам затем присваивается числовое значение и преобразуется в вектор функций VI, посредством процесса вербализации, объясненного в разделе 3.3.
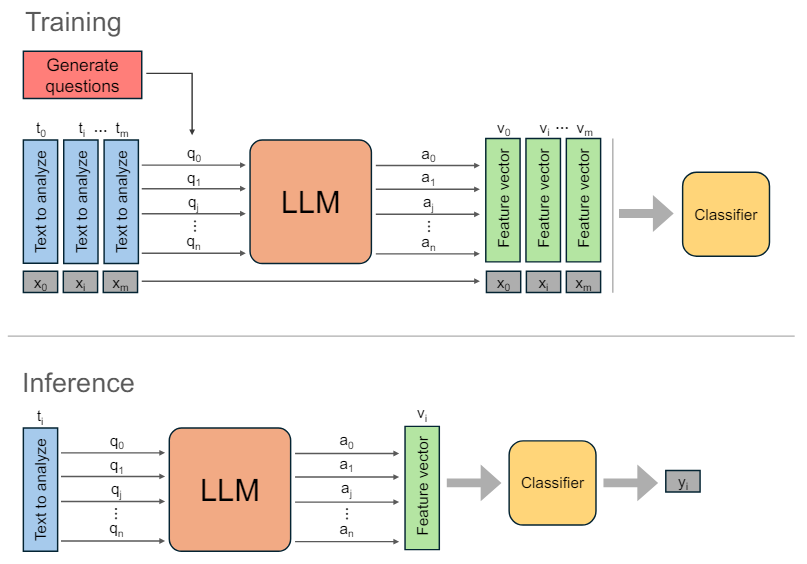
3.3. Вырбализация ответов
Вывод LLM в ответ на каждую подсказку ограничен одним из трех возможных значений: да, нет или неизвестно, в зависимости от ответа на вопрос, заданный в приглашении. Этим ответам впоследствии присваиваются численные значения для анализа, при этом «да» переводится на 1, «нет» на 0 и «неизвестно» на 0,5.
3.4 Обучение классификатора
Для обучения классификатора мы используем набор V из низкоразмерных численных векторов, где | v = n+1 и соответствующие метки x, где каждый вектор VI имеет соответствующую бинарную метку XI. Векторы V получают из учебных текстовых данных после побуждения LLM для генерации N + 1 выходов, которым затем присваивается числовое значение. Затем классификатор обучается с использованием 5-кратного процесса перекрестной проверки и поиска сетки для лучших параметров. Выбор конкретного алгоритма классификации будет зависеть от размера учебных данных, распределения значений и желаемой производительности на определенной метрике классификации.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)