
Использование Kubernetes и контейнеров для бесконечного масштабирования
14 ноября 2022 г.Полный вихрь перспективы
Контейнеризация лучшего в мире кода ничего не значит, если у этого контейнера нет ресурсов для выполнения своей работы.
Идея этой статьи возникла, когда мы писали об эффективных зондах контейнеров. Стало ясно, что предоставление точных ответов на запросы kubelet — это только первая часть решение.
Вторая часть является предметом этой статьи: распределение ресурсов по контейнерам, но изучение всего ландшафта распределения ресурсов, от одного контейнера в модуле Kubernetes до почти бесконечной емкости в облаке. р>
Управление ресурсами Kubernetes: обзор
"Как убедиться, что в контейнерах всегда есть необходимые ресурсы?"
Считайте этот раздел подведением итогов для тех, кто только начинает работать с управлением ресурсами Kubernetes. Официальная документация по управлению ресурсами Kubernetes для контейнеров и диапазонам ограничений пространства имен по-прежнему является обязательной к прочтению в пространство. Если вы уже знакомы с этой темой, перейдите к следующему разделу.
Управление ресурсами Kubernetes в основном охватывает процессор, память и локальное временное хранилище. Спецификация контейнера может определять запросы ресурсов и ограничения ресурсов для каждого типа ресурсов.
Запрос ресурса — это минимальный объем ресурсов, необходимый для среды выполнения контейнера. Планировщик узла планирует пакет на узле только в том случае, если этот узел может удовлетворить этот минимальный запрос для всех контейнеров в модуле.
Ограничение ресурсов – это максимальное количество ресурсов, которое kubelet должен выделить контейнеру в течение срока его службы. Если для контейнера установлено ограничение ресурсов, но не запрос ресурсов, это эквивалентно установке для запроса ресурсов того же значения, что и ограничение ресурсов.
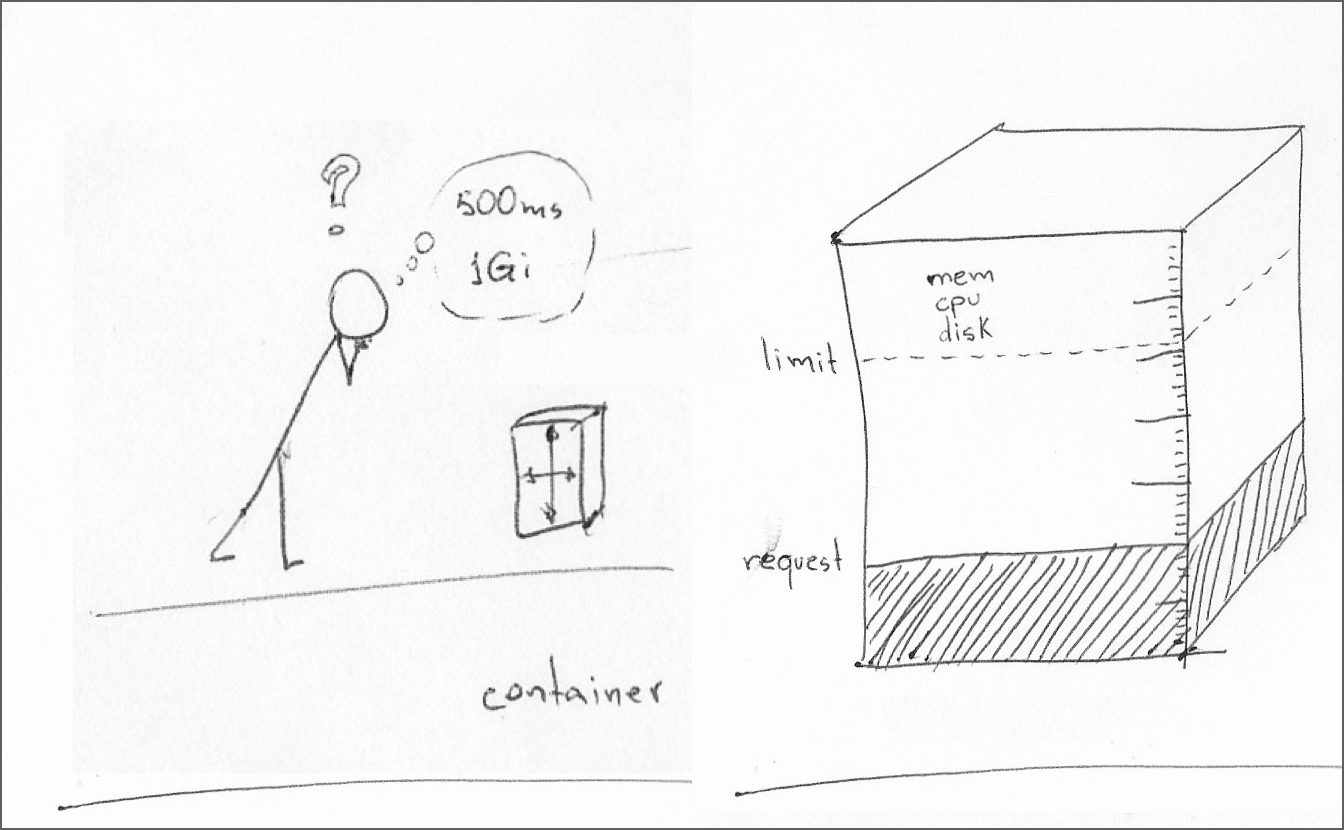
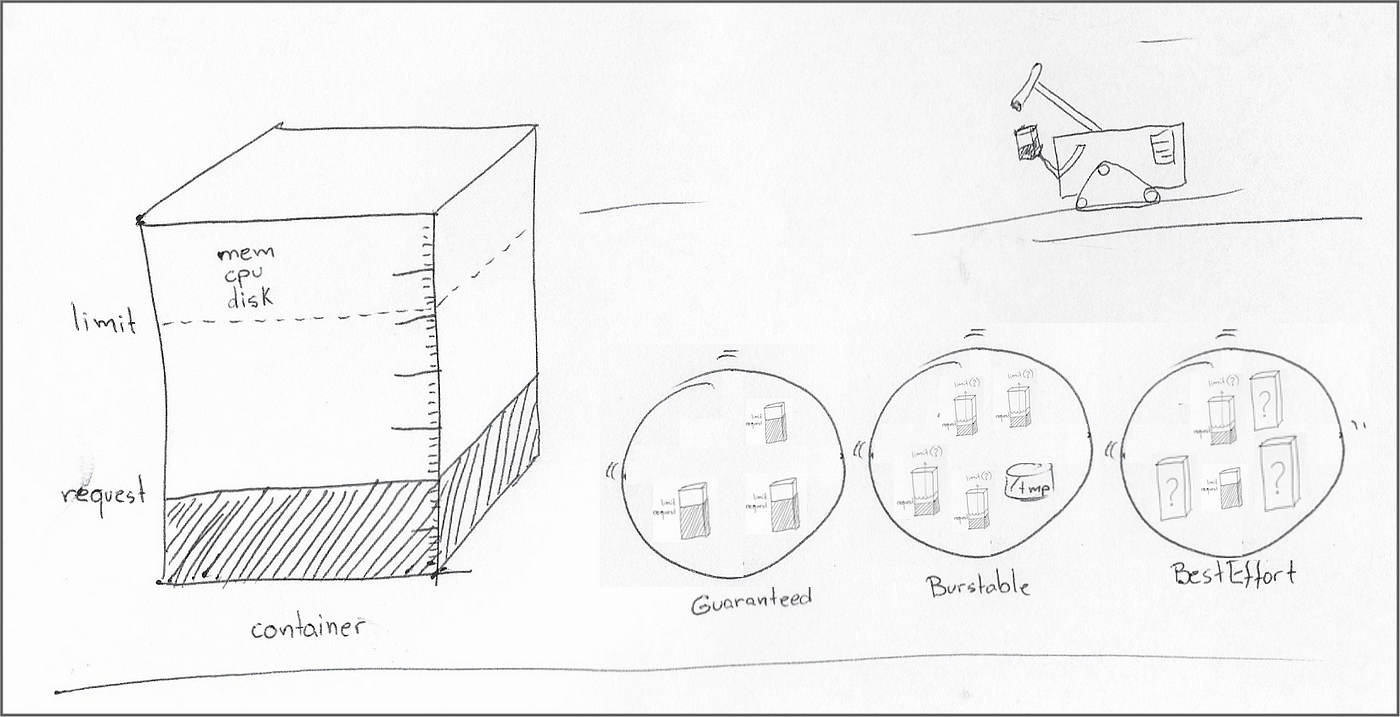
Kubernetes позволяет разработчикам программного обеспечения и системным администраторам совместно устанавливать минимальные резервы и максимальные ограничения для таких ресурсов, как ЦП, память и временное хранилище. Контейнер может иметь любую комбинацию запросов ресурсов и ограничений, при этом различные комбинации резервирования ЦП и памяти определяют качество обслуживания родительского модуля следующим образом:
* Для каждого контейнера в модуле установлены как запрос ресурсов, так и лимит, и для каждого контейнера запрос и лимит имеют одинаковое значение: Гарантировано. * Запрос ресурсов или ограничение не установлены по крайней мере в одном из контейнеров в модуле: BestEffort. * Все остальные модули, не вошедшие в два предыдущих сегмента: Burtable
.
n Полезно посмотреть, что означают эти категории, когда kube-scheduler решает запланировать модуль на рабочем узле:
* «Гарантировано» означает, что планировщик назначает модуль только рабочим узлам с достаточными ресурсами для удовлетворения запросов всех контейнеров в модуле.
* «Разрывное» QoS означает, что планировщик ищет рабочий узел с достаточным объемом памяти для удовлетворения запросов ресурсов всех контейнеров в поде. Планировщик не заботится о том, может ли рабочий узел соответствовать ограничениям ресурсов контейнеров в модуле или чему-либо сверх запроса ресурсов, если на то пошло.
* «BestEffort» означает, что планировщик сначала будет удовлетворять запросы ресурсов каждого модуля с «гарантированным» или «стабильным» QoS, прежде чем планировать модуль «BestEffort». Планировщик постоянно пересматривает эту оценку, поэтому он по-прежнему может помечать модуль «BestEffort» для исключения, если те же ресурсы требуются для модуля «Guaranteed» или «Burtable».
Время принятия решения: кто должен определять ресурсы контейнера?
Сначала мы должны понять, что запросы ресурсов защищают контейнер, а ограничения ресурсов защищают кластер.
Двумя основными сторонами в этом решении являются разработчики продукта и системные администраторы. Эти «переговоры» между ними несколько сложны, потому что они растянуты во времени:
* Разработчики продуктов тратят большую часть времени на установление границ ресурсов отдельно от развертывания в рабочей среде.
* Системные администраторы часто имеют дело со спецификациями рабочей нагрузки Kubernetes с недостаточной документацией о том, как изменения в предустановленных запросы и ограничения влияют на рабочие нагрузки.
Разработчики продуктов имеют более полное представление о потребностях рабочих нагрузок и их поведении при различном распределении ресурсов. Как правило, перед отгрузкой они должны быть в состоянии определить следующие пороговые значения:
* Абсолютный минимум запроса ресурсов. Это значение представляет собой использование ресурсов, необходимое для загрузки среды выполнения и возможности удобного ответа на пробные запросы от kubelet. В этой статье показано несколько запросов PromQL для выявления проблемных контейнеров.
* Максимально используемый лимит ресурсов. Это значение — точка, в которой производительность контейнера начинает сталкиваться с внешними ограничениями, такими как дисковый ввод-вывод или узкие места при вызовах сторонних служб.
Я также рекомендую ознакомиться с записью в блоге Натана Йеллина под названием «Вы не можете иметь одновременно высокую степень использования и высокую надежность", исследуя важные компромиссы, связанные с определением запросов и ограничений ресурсов.

В идеале разработчики продукта должны также установить и задокументировать, как производительность контейнера меняется в этих границах. Эта информация позволяет системным архитекторам планировать начальную мощность перед развертыванием, а системным администраторам корректировать запросы на ресурсы в производственных средах.
Квоты, диапазоны и трагедия общего пользования
Системные администраторы имеют представление о емкости кластера и о том, какая часть этой емкости еще доступна. Как человек, который иногда носит шляпу SRE, я ценю рабочие нагрузки в «гарантированном» сегменте QoS. Организации разработчиков требуется особая уверенность (и большое количество тестов), чтобы установить фиксированные границы ресурсов для всех контейнеров в модуле и доверять тому, чтобы модуль надежно работал в этих границах.
«Взрывные» рабочие нагрузки находятся несколько ниже в этом спектре доверия. Когда я ношу шляпу SRE, я больше всего надеюсь, что все контейнеры в расширяемом модуле имеют «абсолютно минимальные» запросы ресурсов, упомянутые в предыдущем разделе.
Когда дело доходит до ограничений ресурсов при взрывной рабочей нагрузке, мое мнение зависит от философии разработки, стоящей за этими ограничениями:
* (хорошо) Автомасштабирование в рамках рабочей нагрузки (например, виртуальная машина Java, запущенная с минимальным и максимальным ограничениями памяти). времени на определение полезного рабочего диапазона рабочей нагрузки и хорошо справляется с управлением этими ресурсами.
* (плохо) Защита от возможных ошибок. Эта философия дизайна напоминает мне о «трагедии общин», где каждый требуется немного больше общего ресурса, чтобы предвидеть его возможное исчерпание, ускоряя исчерпание общего ресурса. Эта философия особенно губительна, когда команда разработчиков недооценивает запросы на ресурсы. В этой ситуации рабочая нагрузка постоянно работает в зоне взрывоопасности своего рабочего диапазона, что делает ее восприимчивой к регулированию ЦП, исчерпанию памяти и завершению kubelet на рабочем узле.
И это, наконец, оставляет нас с рабочими нагрузками «BestEffort», постоянным источником беспокойства из-за их неограниченной способности истощать ресурсы кластера и их незначительного статуса планирования перед лицом других модулей, запрашивающих те же ресурсы.
Имея дело с этими типами рабочих нагрузок, системный администратор должен уделить время рассмотрению возможных вариантов:
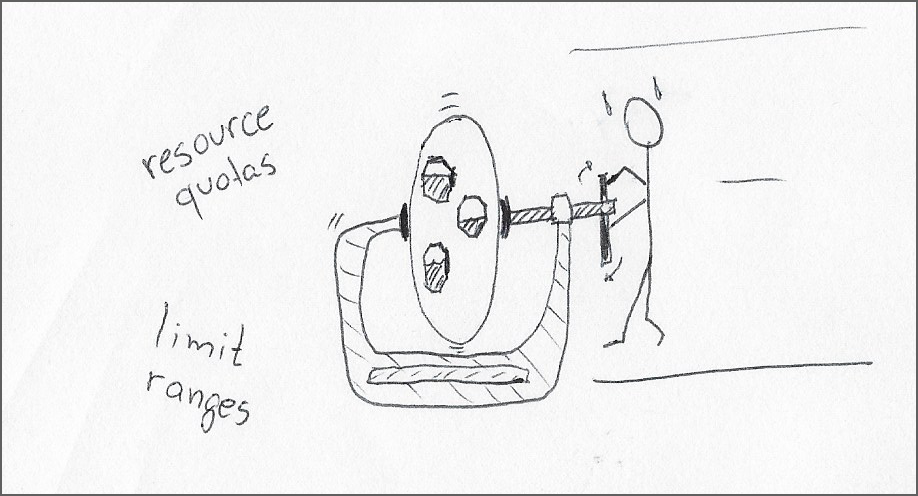
1. Используйте предельные диапазоны, чтобы задать запросы ресурсов по умолчанию и ограничения для контейнеров и модулей в пространстве имен. Я думаю, что общее назначение одинаковых лимитов ресурсов для всех рабочих нагрузок в пространстве имен в сочетании с отсутствием информации от разработчиков продукта делает это предложение нереалистичным.
2. Используйте квоты ресурсов, чтобы ограничить объединенные ресурсы для всех модулей в пространстве имен. Этот подход является более перспективным решением. Это уменьшает «радиус поражения» потенциального контейнера, который может выйти из строя в этом пространстве имен, с преимуществом, позволяющим избежать потерь, связанных с умножением буфера безопасности ресурса на количество модулей в пространстве имен.
3. Сделайте глубокий вдох и надейтесь на облегчение благодаря технологиям автоматического масштабирования контейнеров, описанным в следующем разделе.
Автомасштабирование модуля: помимо статического размера
Вероятно, многие читатели готовы предложить обычные обходные пути для борьбы с неконтролируемыми рабочими нагрузками:
* Горизонтальное автомасштабирование pod (HPA) * Вертикальное автомасштабирование пакетов (VPA)
Эти популярные методы автоматического масштабирования позволяют динамически распределять емкость внутри кластера на основе показателей ресурсов; HPA может изменить количество реплик модуля в развертывании, в то время как VPA может изменить запросы ресурсов и ограничения для модуля. Обратите внимание, что до этого Предложение по улучшению Kubernetes добавлено в Kubernetes, изменения VPA в модуле приводят к его перезапуску.
Хотя эти компоненты способны автоматически увеличивать емкость, они не позволяют отказаться от точного определения рабочих диапазонов для своих рабочих нагрузок. Например, HPA не будет выполнять действия по метрике, если у контейнеров в модуле нет запроса ресурсов для этой метрики. HPA также не подходит для сценариев, в которых развертывание зависит от определенного количества реплик для модуля в кластере.
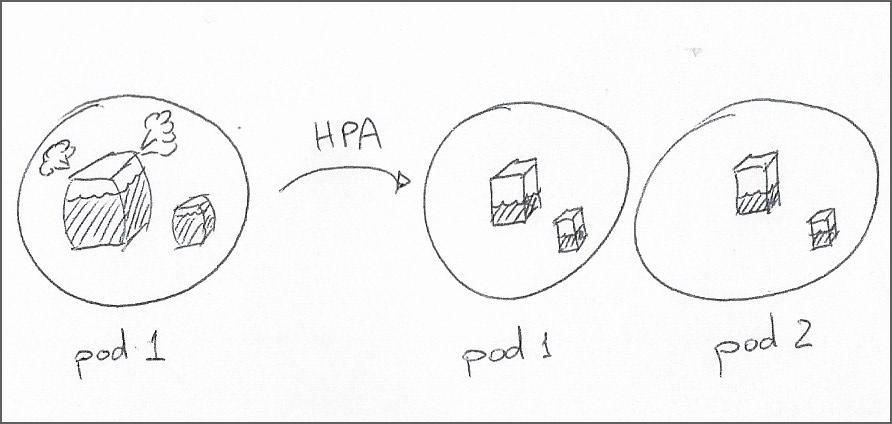
Использование VPA лучше для рабочих нагрузок, требующих фиксированного количества реплик, или когда рабочая нагрузка не поставляется с предустановленными ограничениями. Однако существует относительно длинный список ограничений. Кроме того, при использовании предельных диапазонов могут возникать дополнительные вопросы.
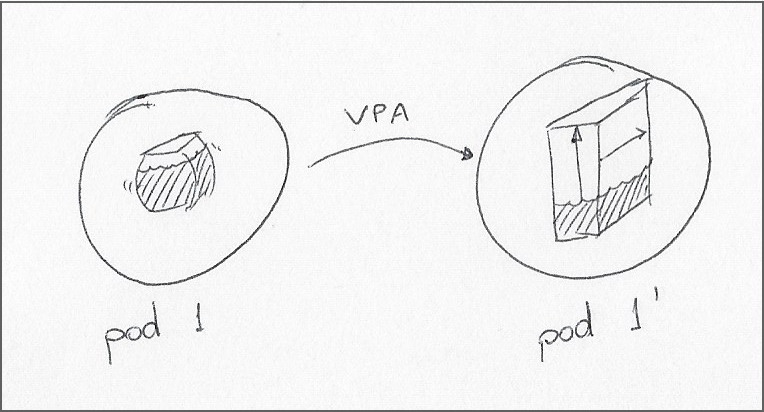
n В конечном итоге эффективность этих инструментов при автоматическом масштабировании рабочих нагрузок зависит от усилий по профилированию, затрачиваемых на определение тщательно изученных запросов ресурсов и ограничений во время разработки. Здесь я должен отдать должное VPA за ее способность «изучить» диапазоны операционных ресурсов для развертывания.
Операторы автопилота: SRE в коробке?
Операторы Kubernetes вводят понятие настраиваемых ресурсов для управления приложениями и рабочими нагрузками. Концептуально оператор постоянно отслеживает пользовательский ресурс и сопоставляет его содержимое с ресурсами рабочей нагрузки
.Модель зрелости оператора предусматривает пять различных уровней автономии, наивысшим из которых является уровень 5, или «Автопилот». Оператор на этом этапе зрелости должен, помимо других видов автономного поведения, применять горизонтальное или вертикальное масштабирование к рабочим нагрузкам, которыми он управляет.
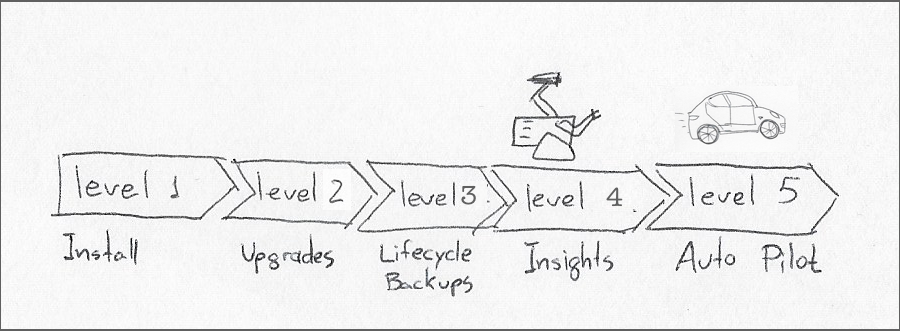
Разработка оператора сопряжена с естественными дополнительными затратами, включая разработку и документирование пользовательских определений ресурсов. Существует также дополнительная стоимость времени выполнения модуля оператора. Вот почему я думаю, что ценность операторов начинает компенсировать свои затраты только на уровне 4, или «Глубокой аналитике», которая включает в себя генерацию метрик, выдачу предупреждений, анализ рабочей нагрузки и т. д.
Ниже уровня 4 операторы мало что делают, чтобы облегчить непрерывный цикл разработчиков продуктов, пытающихся предсказать будущее, и системных администраторов, пытающихся воплотить эти прогнозы в жизнь.
Knative: эластичная емкость без отходов
Согласно веб-сайту Knative , это решение корпоративного уровня с открытым исходным кодом для создания бессерверных и управляемых событиями Приложения».
С точки зрения этой статьи нас интересует модуль Knative Serving. Этот модуль содержит Knative Pod Autoscaler (KPA), который имитирует способность HPA изменять количество реплик pod в соответствии с потребностями, но с двумя ключевыми отличиями:
* Масштабирование реплик в зависимости от объема внешних запросов * Масштабирование реплик до нуля при отсутствии внешних запросов
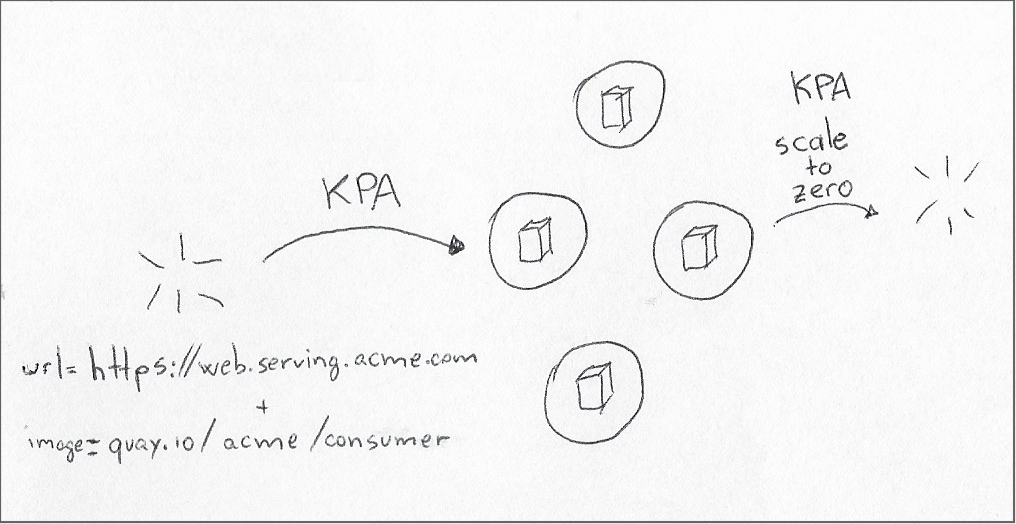
В отличие от HPA, которое реагирует на использование ресурсов, когда оно выходит за заданные границы, KPA принимает решения на основе параллелизма и целевого количества запросов в секунду.
Как показывает опыт, HPA лучше подходит для длительных процессов с медленным запуском, когда потребности в ресурсах не меняются резко. Напротив, KPA отдает предпочтение временным процессам, которые могут быстро загружаться для удовлетворения немедленных потребностей.
И последнее, но не менее важное, независимо от того, бессерверный он или нет, KPA работает с контейнерами, поэтому ограничения ресурсов по-прежнему имеют значение.
Автомасштабирование кластера: расширение границ
После того как вы должным образом настроили все ресурсы рабочей нагрузки и средства автомасштабирования модулей, пришло время глубже изучить набор инструментов и воспользоваться средством автомасштабирования кластера Kubernetes.
Средство автомасштабирования кластера может добавлять (или удалять) рабочие узлы в зависимости от потребности в ресурсах. Средство автомасштабирования учитывает настраиваемые нижние и верхние границы, чтобы обеспечить минимальную емкость и определенный уровень контроля затрат, чтобы избежать чрезмерной нагрузки на кластер из-за неконтролируемых рабочих нагрузок.
Медленное растяжение. Имейте в виду, что время отклика для средства автомасштабирования кластера значительно меньше, чем для средств автомасштабирования pod: рабочему узлу требуется несколько минут, чтобы стать доступным для планировщика Kube.
Предположим, вам нужно средство автомасштабирования кластера для работы с пиковыми нагрузками. В этом случае вы должны прибегнуть к развертыванию резервного буфера из «пакетов паузы» (описано в документации по автомасштабированию кластера). .) Когда новые рабочие нагрузки нуждаются в этих ресурсах, планировщик Kube немедленно вытесняет модули паузы, чтобы освободить ресурсы. Позже кластер увеличивает количество узлов, чтобы перераспределить исключенные модули.
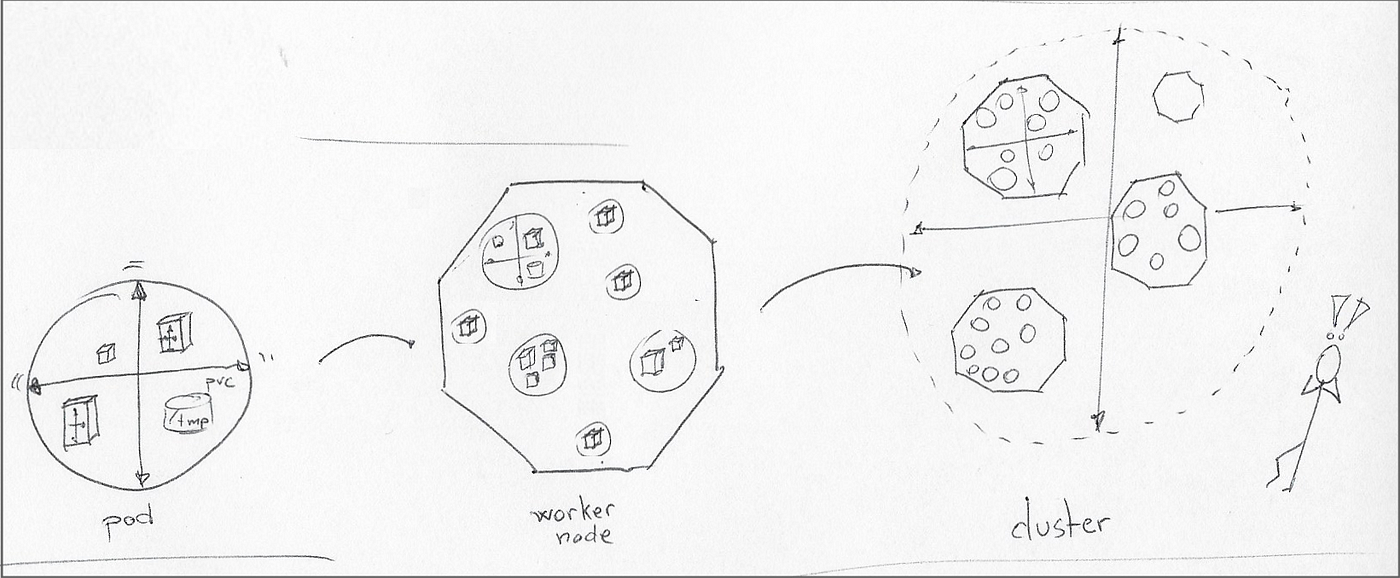
Обратите внимание, что Kubernetes также играет роль загрязнения и допуски. в том, как автоскейлеры выполняют свою работу, делая испорченные рабочие узлы недоступными для размещения модулей без терпимости к этим испорченным.
Бессерверный: безграничная емкость… с ограничениями
Для максимального уровня автомасштабирования пора отказаться от границ кластера — даже Kubernetes имеет ограничения — и посмотрите на бессерверные возможности на уровне облачного провайдера.
Крупные облачные провайдеры могут запускать образы контейнеров по запросу на основе множества событий, таких как веб-запросы, операции с базами данных и таймеры. По сравнению с одним кластером ресурсная емкость облачного провайдера практически неограничена, а стоимость запуска контейнера в течение нескольких секунд практически незначительна по сравнению с выполнением той же рабочей нагрузки внутри кластера.
По иронии судьбы, несмотря на сверхнизкую стоимость вызова, бессерверные подходы заставляют вас переключиться с беспокойства об ограничениях ресурсов на беспокоится о перерасходе средств:
* Ограничения контейнеров по-прежнему имеют значение: поставщики облачных услуг требуют, чтобы вы указали количество ЦП и объем памяти для каждого вызова контейнера. * Бюджетные ограничения: если ошибка в наборе тестов может привести к истощению ресурсов кластера, та же ошибка в бессерверном развертывании может в одночасье стереть весь бюджет вашего отдела.
Вы можете найти несколько вариантов бессерверных предложений, таких как передача небольшой функции облачному движку, а не всего образа контейнера, или разрешение поставщику облачных услуг использовать один из ваших управляемых кластеров для запуска контейнеров (обмен масштабами на безопасность).
Для дополнительного удобства многие из этих предложений могут начинаться с репозитория Git, содержащего Dockerfile, который они используют для создания и кэширования образа контейнера перед планированием рабочих нагрузок, ссылающихся на этот образ.

н
Заключение
Мы рассмотрели весь спектр распределения ресурсов для рабочей нагрузки, от настройки одного контейнера до гипермасштабирования рабочей нагрузки за пределами Kubernetes.
Статья началась с краткого обзора управления ресурсами Kubernetes и его основных концепций запросов и ограничений ресурсов. Затем мы использовали эти статические ограничения в сфере автомасштабирования контейнеров: HPA, VPA и KPA.
От способности автомасштабирования модулей эффективно использовать максимальную емкость кластера мы перешли к увеличению этой емкости с помощью автоматического масштабирования кластера. Затем мы завершили полный воронку перспективы с практически неограниченными ресурсами (и затратами) в виде бессерверные предложения от облачных провайдеров.
За исключением VPA, эти методы по-прежнему основываются на разумных усилиях по определению потребления ресурсов контейнером во время разработки. Например, HPA не предпринимает никаких действий на основе ресурсов, для которых не указаны ограничения, в то время как поставщики облачных услуг напрямую запрашивают ресурсы ЦП и памяти, назначенные для каждого запуска контейнера.
В моей следующей статье на эту тему, не касающейся масштабирования ресурсов, будут рассмотрены конкретные методы определения запросов и ограничений ресурсов во время разработки и наблюдения за ними в рабочей среде.
Ссылки
- Практический Kubernetes — Top Ten Challenges — Part 6: Sizeing and Footprint Optimization, Андре Тост
- Не может быть одновременно высокой загрузки и высокой надежности, автор Натан Йеллин< /li>
- Подробное описание вертикального модуля автомасштабирования, ограничения и примеры из жизни
- Автомасштабирование вертикальных модулей: подробное руководство
- Ресурсы рабочих нагрузок Kubernetes
- IBM Code Engine (управляемый Knative)
Также опубликовано здесь
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27574)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)