

Использование агрегации данных для понимания стоимости проданных товаров
24 февраля 2022 г.Понимание COGS (себестоимость проданных товаров) является ключом к ведению любого успешного бизнеса. Как SaaS-компании, нам необходимо понимать не только наши общие затраты на производство, но и то, насколько каждая функция нашего продукта влияет на себестоимость, с точным распределением затрат на уровне клиента. Это помогает нашим командам инженеров проектировать более экономичную архитектуру, а бизнес-группам — принимать более обоснованные ценовые решения.
В этой статье рассматриваются инструменты, которые использует mParticle, и конвейер, который мы создали, чтобы получить представление о наших расходах на AWS. В нем также рассказывается, как мы решали основные проблемы, чтобы объединить ключевые наборы данных, и как это помогло нам определить основные услуги, которые привели к ненужным расходам.
Взгляд на данные о затратах AWS
Чтобы понять, сколько наши клиенты обходятся нам, нам сначала нужно было узнать, сколько мы тратим в целом. Крупные поставщики облачных услуг, такие как Azure, AWS и GCP, предоставляют информацию о затратах, связанных с использованием их услуг.
mParticle использует AWS, и из AWS Cost Explorer мы смогли получить разбивку того, сколько мы тратим на сервис AWS (например, использование S3, SQS, EC2 и т. д.). Однако для того, чтобы связать эти расходы с нашими клиентами, нам нужна была дополнительная информация.
Задача: привязать расходы AWS к затратам отдельных клиентов
Только с необработанными данными AWS не было четкого способа связать стоимость обслуживания с отдельными клиентами, поскольку, например, у нас могут быть данные нескольких клиентов, проходящие через одну и ту же очередь SQS с логической изоляцией. Еще одна проблема, с которой мы столкнулись, заключалась в том, что во время рабочих нагрузок с интенсивными вычислениями мы хотели отслеживать потребление ЦП клиентом, хотя необработанные данные AWS позволяли нам только видеть, сколько мы тратим на агрегированном уровне.
С помощью [Отчетов о затратах и использовании AWS (CUR)] (https://docs.aws.amazon.com/cur/latest/userguide/access-cur-s3.html) мы смогли получить доступ ко всем наших данных о затратах.
Теоретически, присоединяя эту информацию к другим наборам данных по мере необходимости, мы могли бы получить дополнительную информацию, которую искали.
Заполнение пробелов учетными данными
Для выполнения этой задачи по объединению данных мы разработали пользовательскую библиотеку под названием «CustomerAccountant», которая дает сервисам mParticle возможность четко предоставлять дополнительную информацию о разбивке затрат на каждого клиента при использовании этих сервисов AWS. Например, данные от многих клиентов могут проходить через одну очередь SQS, прежде чем они будут разделены для выполнения других задач. SQS взимает плату за общее количество сообщений и размер сообщения, поэтому мы используем наш CustomerAccountant для отслеживания количества сообщений и общего размера байтов, используемых каждым клиентом. «CustomerAccountant» регулярно отправляет эту информацию из службы в Kinesis Firehose, который доставляет эту информацию в наш кластер BI Redshift.
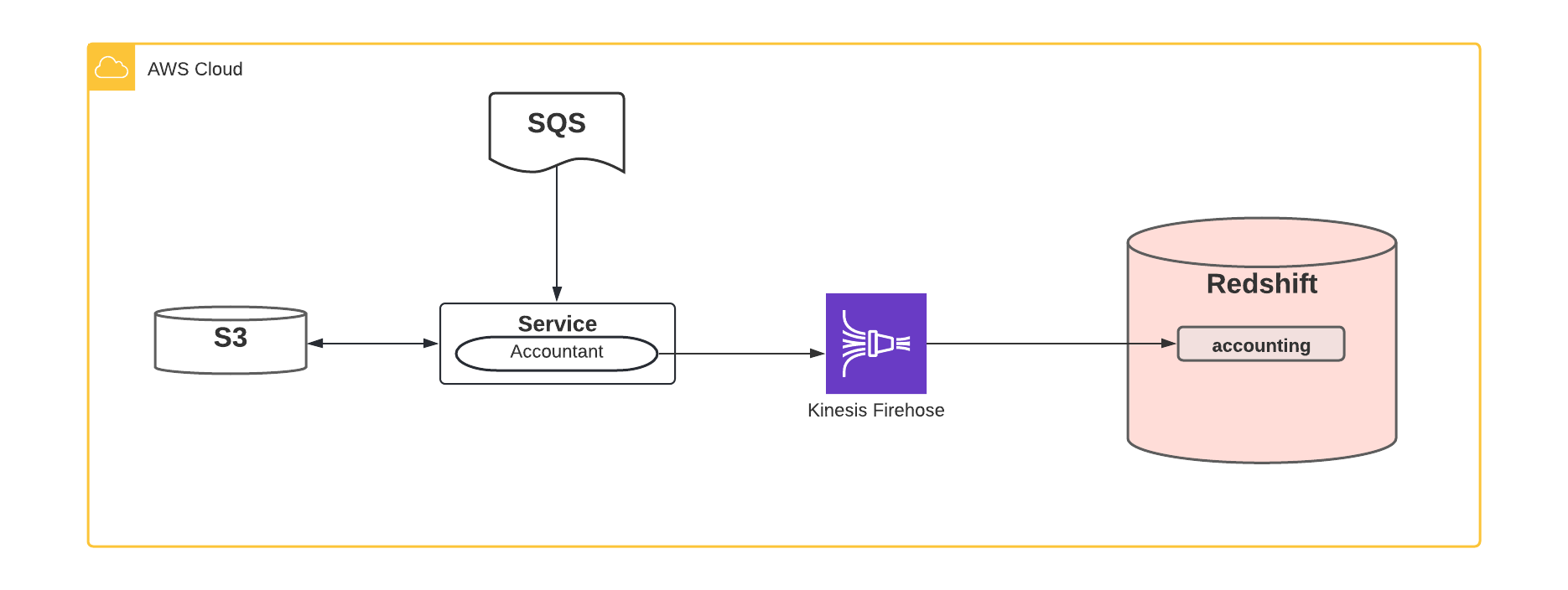
Как выглядит информация CustomerAccountant? Есть несколько важных вещей, о которых мы заботимся, а именно:
- Кто является клиентом в вопросе?
- Какой сервис или ресурс они использовали?
- Сколько этого ресурса они потребляли?
- Когда это произошло?
Таким образом, данные, которые CustomerAccountant может записывать для публикации сообщений SQS, могут выглядеть так:
- ID клиента = 1234
- Сервис = сервис mParticle A
- Ресурс = SQS
- Тип ресурса = Количество записанных байтов
- Потребление = 200,0 (байт)
- Дата и время = 2022-01-28 10:20:00
Но что, если мы записываем потребление процессора? Мы по-прежнему записываем тот же набор информации, но в этом случае потребление не обязательно отслеживается в байтах. Здесь мы будем отслеживать потребление в миллисекундах, и, поскольку это числовое значение, наш набор данных остается согласованным:
- ID клиента = 2345
- Сервис = сервис mParticle A
- Ресурс = ЦП
- Вид ресурса = Время
- Потребление = 4205,0 (мс)
- Дата и время = 2022-01-28 10:20:00
С библиотекой «CustomerAccountant» каждая из наших инженерных групп отвечает за ее инструментальное обеспечение для отслеживания необходимых показателей для понимания использования их компонентов. Мы сделали это требованием для запуска любого продукта в производство.
Общий набор данных
Наличие набора данных с общими полями упрощает работу как при приеме данных в Kinesis, так и при использовании данных из Redshift. Все данные CustomerAccountant попадают в учетную таблицу в нашем кластере BI Redshift.
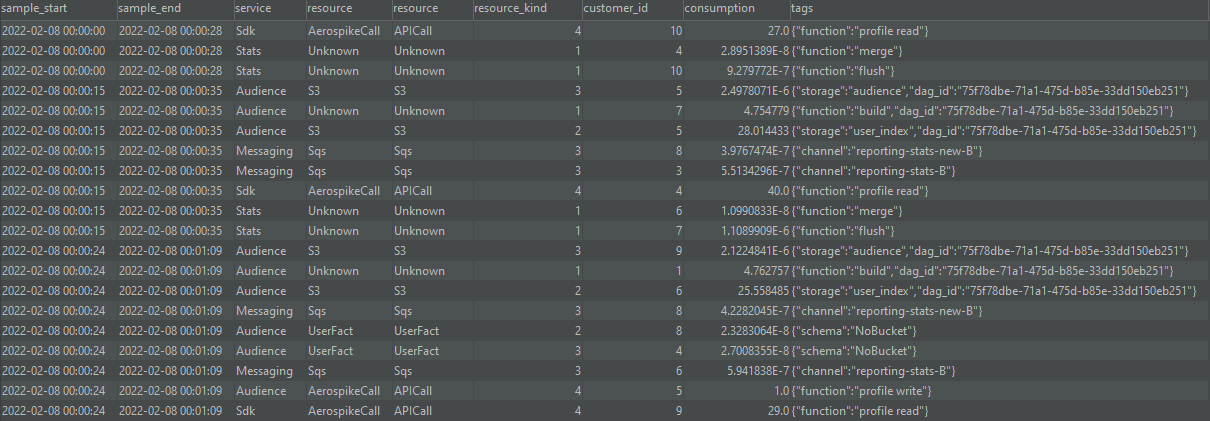
Эта учетная таблица со временем стала очень большой — миллиарды строк — из-за огромного объема собираемых данных, потому что каждый экземпляр контейнера запускает свой собственный CustomerAccountant и отправляет данные в Kinesis firehose каждые несколько минут. Данные в этой необработанной форме хороши, но они действительно оказывают влияние, когда они агрегированы.
Сколько бутербродов?
Думайте об этом как о позициях в квитанции из вашего заказа на обед. Приятно знать, что ваш бутерброд стоил 5 долларов, а напиток — 2 доллара, и отсюда мы можем довольно легко сказать, что потратили 7 долларов на обед (не включая налоги и т. д.). Теперь предположим, что наша квитанция содержит 10 миллиардов позиций и покрывает группу из тысяч человек в течение недель или лет. Когда кто-то спрашивает нас, сколько бутербродов было куплено во вторник, все становится немного сложнее.
Есть несколько оптимизаций, которые мы сделали поверх наших данных учета, чтобы помочь решить эту проблему. Во-первых, учетные данные в этой таблице не изменяются, поэтому, как только они появляются в таблице, мы заранее объединяем их вместе, чтобы сделать запросы к этому набору данных намного быстрее. Или, другими словами, если мы купили 500 бутербродов в мае 2020 года, так будет всегда (пока не будут изобретены путешествия во времени), поэтому нам не нужно складывать бутерброды за май 2020 года каждый раз, когда мы считаем бутерброды. Мы коснемся этого позже.
Однако в данных бухгалтерского учета не хватает одного аспекта проблемы, связанного с затратами. Мы знали, сколько услуг использовали наши клиенты, но без данных от AWS мы не могли точно сказать, сколько нам стоил каждый клиент. Нам нужно было объединить оба этих набора данных.
Объединение данных с помощью Airflow
Как упоминалось ранее, мы используем Отчеты о затратах и использовании AWS (CUR) , что дает нам доступ к все наши данные о затратах в корзине S3. Это было нашим первым серьезным препятствием, потому что данные были в S3, а не в Redshift, где существуют наши бухгалтерские (и другие важные данные BI).
Чтобы решить эту проблему, мы выбрали Airflow через AWS MWAA , что позволило нам легко организовать прием этих данных в Redshift. Каждый день Airflow DAG (код Python) извлекает данные о затратах из AWS S3 и делает их доступными для использования в Redshift. При использовании AWS CURs возникают некоторые интересные технические сложности, но наше решение в конечном итоге выглядело так: что-то вроде этого:
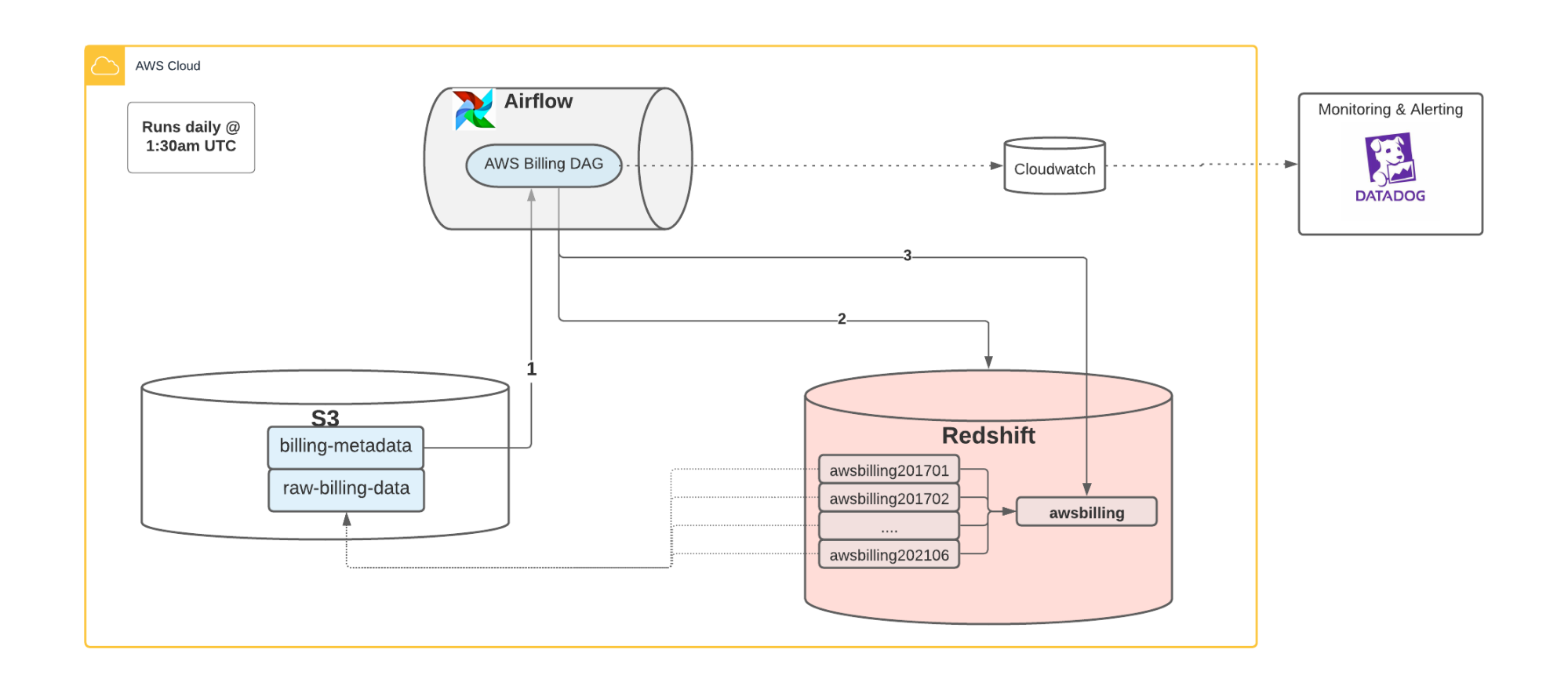
- Для каждого месяца мы создаем внешнюю таблицу с использованием Redshift Spectrum , что дает нам представление о данных о затратах AWS, которые существуют в S3.
- Мы создаем представление поверх внешних таблиц, чтобы объединить их в одном месте.
- У нас есть ведение журналов, метрики, оповещения и многое другое с использованием Cloudwatch и Datadog
Создание компонентов затрат и запрос данных
Теперь, когда наши данные находились в общем хранилище BI, мы могли начать использовать их для нашей аналитики. Было несколько вещей, которые нам нужно было сделать в первую очередь, чтобы максимально использовать наши данные.
Как мы уже упоминали ранее, набор учетных данных огромен и состоит из миллиардов строк, многие из которых поступают из инстансов EC2, на которых размещена большая часть нашей платформы. Запросы к этому набору данных громоздки и могут быть быстро улучшены за счет ежедневной предварительной агрегации данных. Вместо того, чтобы каждый раз запрашивать базовый набор бухгалтерских данных с миллиардами строк и агрегировать их, запрос агрегированного набора данных предоставляет те же данные, но за меньшее время. Этот предварительно агрегированный набор данных стал первым из того, что мы называем нашими компонентами затрат.
Следующее, что мы хотели сделать, это начать создавать больше компонентов затрат, чтобы обеспечить нам то целостное представление, которого мы пытались достичь. Возвращаясь к примеру SQS, чтобы построить компонент затрат SQS, мы извлекаем данные из представления awsbilling и компонента accounting_aggregated. Мы также получаем некоторую информацию о клиентах из другого представления Redshift vw_org. Мы объединяем три набора данных, используя идентификатор клиента, и фильтруем таблицу awsbilling для получения информации о затратах только на SQS.
У нас есть более дюжины этих компонентов с различными уровнями сложности, все они созданы и объединены между двумя основными наборами данных awsbilling и accounting_aggregated данными, обеспечивая фильтрацию или обогащение для данные, специфичные для каждого компонента.
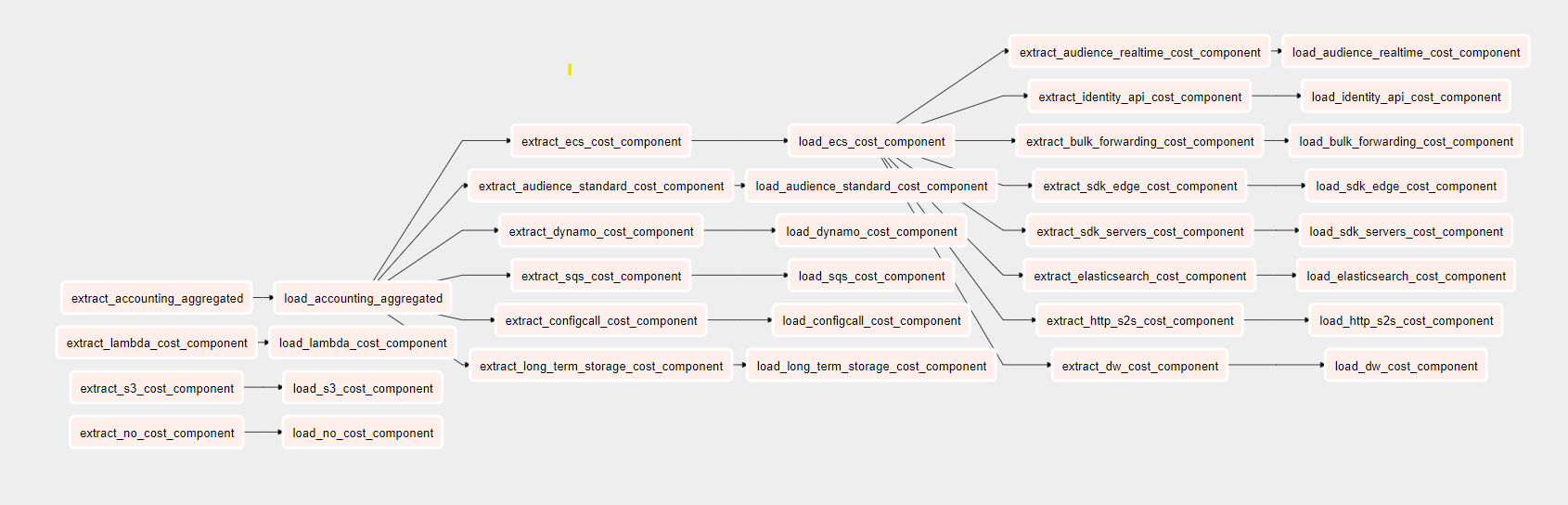
Иметь все эти компоненты было здорово, и это был огромный шаг вперед к ответу на наш вопрос: «Сколько нам обходится клиент X?». Последнее, что нам нужно, — это собрать все эти компоненты вместе в виде отчета, где мы сможем затем фильтровать на уровне клиента, а не на уровне компонентов затрат.
Анализ данных и возможности
Все данные были в Redshift, и у нас были отдельные компоненты затрат, созданные для каждой из наших основных служб. Теперь мы хотели предоставить эти данные для нашего бизнеса и аналитики. Нашим предпочтительным инструментом BI и Analytics был Looker. Внутри Looker у нас есть возможность углубляться в каждый компонент затрат по мере необходимости, а также создавать отчеты, которые могут ответить на наш первоначальный вопрос: какова наша себестоимость?
Одним из наиболее важных отчетов, которые у нас есть, является сводное представление наших стоимости AWS. Он объединяет все компоненты затрат с данными учета и разбивает их несколькими способами для облегчения анализа, позволяя фильтровать и быстро просматривать базовые данные.
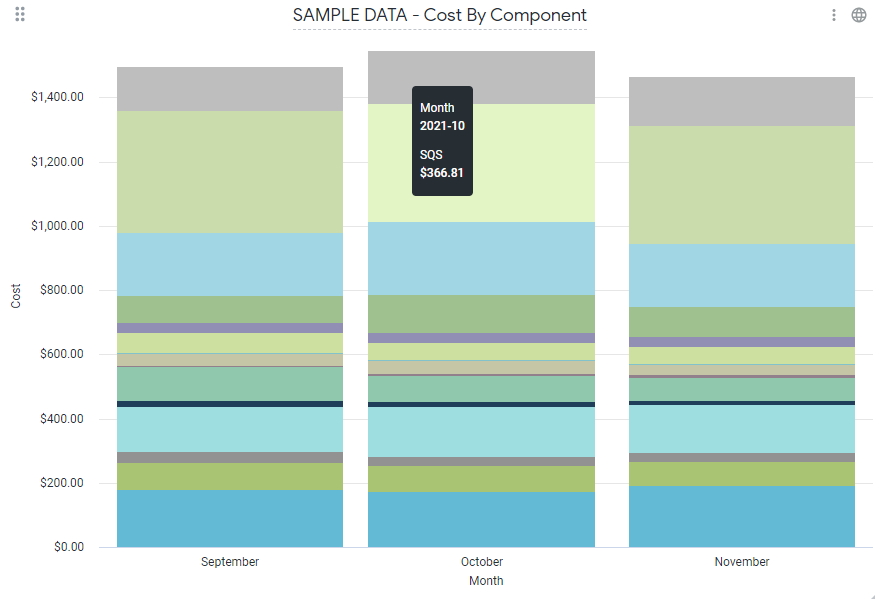
Именно здесь действительно вступает в игру общий набор данных для всех наших бухгалтерских данных и компонентов затрат.
Наличие этих отчетов имело решающее значение для принятия бизнес-решений и помогло подчеркнуть, что один из наших основных компонентов стоил все больше и больше с каждым месяцем по мере того, как его использование становилось все более распространенным. Это позволило нам принять меры, сформировав отряд, специально предназначенный для снижения потребления ресурсов и оптимизации этого компонента, что в конечном итоге снизило его стоимость в пять раз.
По мере того, как наша платформа растет и расширяется, мы можем легко встраиваться в эту систему, добавляя дополнительные компоненты и различные разбивки данных в зависимости от наших потребностей в данный момент. Доступность этих данных критически важна для принятия правильных решений сейчас и для руководства нашими решениями по мере роста нашего бизнеса.
Хотите получать проверенные отзывы о ландшафте инженерии данных? Подпишитесь на [Дайджест разработчиков mPulse] от mParticle (https://www.mparticle.com/resources/mpulse-sign-up). Написано разработчиками для разработчиков, включая такой контент, как технические сообщения в блогах, обновления документации и тщательно подобранные материалы из области инженерии данных.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27142)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Социальные медиа и интернет-культура (107)
- Экономика и финансы (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)