Вставка больших записей из электронной таблицы (файл CSV) в базу данных является очень распространенным и трудная инженерная задача для решения по многим причинам. Современный стек данных ETL инструменты могут решить проблему.
А если?
- Вы специалист по javascript (NodeJS).
- Вы не хотите вкладывать деньги в инструмент ETL.
- Вы не специалист по данным, который знает, как создавать и поддерживать конвейеры данных.
*

Node.js — это мощный и гибкий механизм для чтения и записи данных в потоковая мода. Потоки обеспечивают эффективный способ обработки больших объемов данных, обрабатывая их небольшими порциями, а не загружая все сразу в память.
Поэтому мы собираемся решить эту проблему с помощью Node Stream.

Как нам поможет NodeJS Stream!!
В Node.js поток — это абстрактный интерфейс, представляющий последовательность данных. Поток можно рассматривать как поток данных, разделенный на фрагменты, и эти фрагменты можно обрабатывать постепенно по мере их доступности.
Потоки можно использовать для чтения или записи данных из различных источников, таких как файлы, сетевые сокеты или даже структуры данных в памяти. Потоки в Node.js реализуются с помощью генераторов событий, что означает, что их можно использовать асинхронно и неблокирующим образом.
Используется ли текущая архитектура для решения этой проблемы?
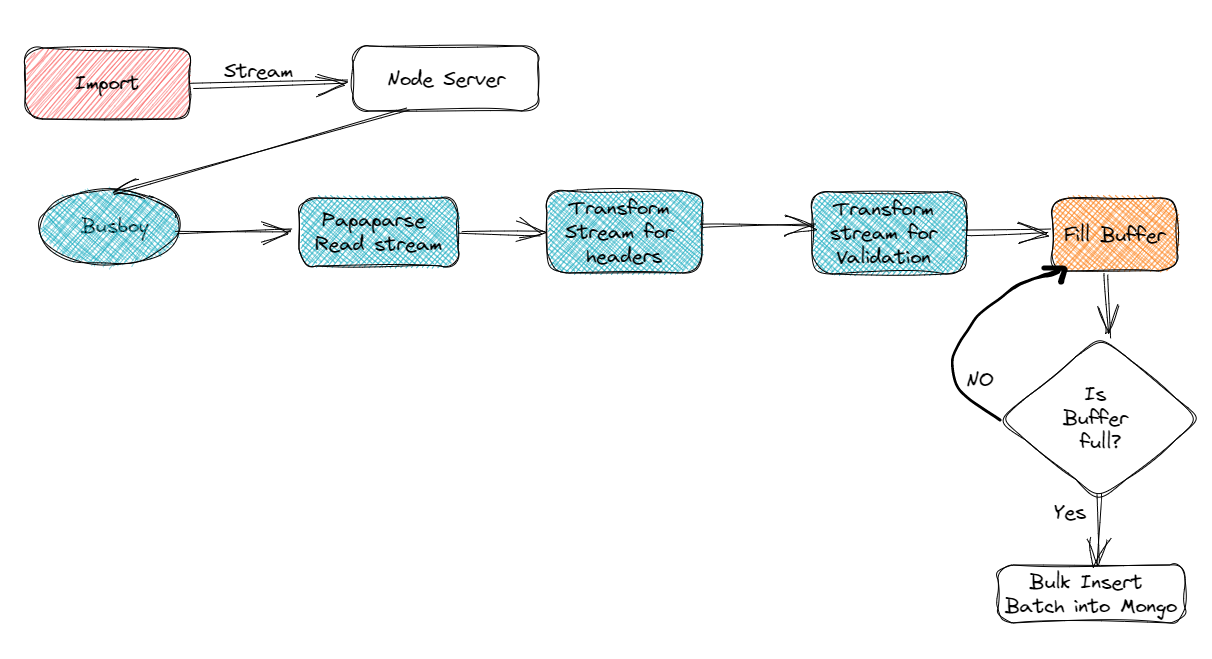
Шаг 1
Зона перетаскивания создается для предоставления места для перетаскивания CSV-файла.
const onDrop = useCallback((acceptedFiles) => {
setFiles((prevFiles) => [...prevFiles, ...acceptedFiles]);
}, []);
const { getRootProps, getInputProps, isDragActive } = useDropzone({ onDrop });
return(
<>
<div
className={`px-6 pt-5 pb-6 border-2 border-dashed rounded-lg ${
isDragActive ? "border-green-400" : "border-gray-400"
}`}
{...getRootProps()}
>
<input {...getInputProps()} />
<div className="flex flex-col items-center justify-center text-center space-y-1">
<PlusIcon className="w-8 h-8 text-gray-400" />
<p className="text-sm font-medium text-gray-400">
Drop files here or click to upload
</p>
</div>
</div>
{files.map((file) => (
<p
key={file.name}
className="mt-2 text-sm font-medium text-gray-500 truncate"
>
{file.name} ({file.size} bytes)
</p>
))}
</>)
Шаг 2
Создайте rest api< /a> для запуска потоковой передачи.
busboy.on(
'file',
async function (fieldname, file, filename, encoding, mimetype) {
console.log('The file details are', filename, encoding, mimetype);
}
pipeline(stream1, stream2)
)
Здесь мы использовали библиотеку Busboy для прямой потоковой передачи данных вместо их копирования на сервер и последующего перемещения. в MongoDB.
Функция конвейера из потока js узла будет использоваться для предоставления потока для синтаксического анализа, затем преобразования и вставки в Монгодб.
pipeline(
file,
openCsvInputStream,
headers_changes,
dbClient.stream,
(err) => {
if (err) {
console.log('Pipeline failed with an error:', err);
} else {
console.log('Pipeline ended successfully');
}
}
);
Шаг 3
Здесь поток papaparse является первым этапом конвейера. Papaparse — это высокоскоростная библиотека синтаксического анализа для преобразования огромных CSV-файлов в формат JSON. Но нам нужен поток огромного количества данных csv, которые будут переданы на следующие этапы преобразования.
Следующий код создает читаемый поток из входного потока papaparse:
const openCsvInputStream = (fileInputStream) => {
const csvInputStream = new Readable({ objectMode: true });
csvInputStream._read = () => {};
Papa.parse(fileInputStream, {
header: true,
dynamicTyping: true,
skipEmptyLines: true,
step: (results) => {
csvInputStream.push(results.data);
},
complete: () => {
csvInputStream.push(null);
},
error: (err) => {
csvInputStream.emit('error', err);
},
});
return csvInputStream;
};
Шаг 4
Именно здесь на сцену выходят потоки трансформации.
var headers_changes = new Transform({
readableObjectMode: true,
writableObjectMode: true,
});
headers_changes._transform = async function (data, enc, cb) {
var newdata = await changeHeader({
oldColumns,
newColumns,
});
headers_changes.push(newdata);
cb();
};
Это преобразование изменения заголовка изменяет старые имена заголовков столбцов на новые имена заголовков. Загвоздка в том, что это поток-трансформер. После преобразования данных они готовы к вставке.
Шаг 5
Наступает последний этап вставки в Mongo DB. Но нам нужна пакетная вставка в MongoDB. Это называется массовой вставкой.
Здесь мы должны создать пакет записей и, когда пакет будет заполнен, вставить в mongodb.
Очистите пакет, чтобы освободить место для новых записей.
async addToBatch(record) {
try {
this.batch.push(record);
if (this.batch.length === this.config.batchSize) {
await this.insertToMongo(this.batch);
}
} catch (error) {
console.log(error);
}
}
const writable = new Writable({
objectMode: true,
write: async (record, encoding, next) => {
try {
if (this.dbConnection) {
await this.addToBatch(record);
next();
} else {
this.dbConnection = await this.connect();
await this.addToBatch(record);
next();
}
} catch (error) {
console.log(error);
}
},
});
Чего мы достигли?
Поток — это мощная функция NodeJ. Даже если у вас есть ноутбук с 8 ГБ оперативной памяти, вы можете использовать его для анализа большого CSV-файла и его потоковой передачи в MongoDB с минимальным использованием ресурсов ЦП и ресурсов. БАРАН. Но может ли он выполнять несколько запросов параллельно? Дождитесь нашей следующей записи!
:::информация Примечание. Это тестирование проводится на компьютере MAC M1 с 8 ГБ ОЗУ.
:::