
Непревзойденная эффективность LLM: многократный прогноз революционизирует производительность между доменами
18 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
4. Абляции на синтетических данных
5. Почему это работает? Некоторые предположения
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
М. Обучение гиперпараметры
3. Эксперименты по реальным данным
Мы демонстрируем эффективность потерь предсказания с несколькими точками на семь крупномасштабных экспериментов. В разделе 3.1 показано, как многократный прогноз становится все более полезным при увеличении размера модели. Раздел 3.2 показывает, как дополнительные головки прогнозирования могут ускорить вывод в 3 × с использованием спекулятивного декодирования. Раздел 3.3 демонстрирует, как мульти-ток-прогноз способствует более долгосрочным моделям обучения, что является наиболее очевидным в крайнем случае токенизации уровня байта. Раздел 3.4 показывает, что 4-то-ток-предиктор приводит к сильным достижениям с токенизатором размера 32K. Раздел 3.5 иллюстрирует, что преимущества многоцелевого прогноза остаются для обучения с несколькими эпохами. Раздел 3.6 демонстрирует богатые представления, продвигаемые в результате предварительной подготовки с несколькими потери прогнозирования путем создания набора данных CodeContests (Li et al., 2022). Раздел 3.7 показывает, что преимущества мульти-токного прогнозирования перенесены на модели естественного языка, улучшаяГенеративныйОценки, такие как суммирование, при этом не регрессируют значительно на стандартных контрольных показателях, основанных на вопросах с множественным выбором и негативным логарифмическим правдоподобием.
Чтобы обеспечить справедливое сравнение между предикторами следующих ток и предикторов N-Token, эксперименты, которые следуют, всегда сравнивают модели с одинаковым количеством параметров. То есть, когда мы добавляемне- 1 слои в будущих головках прогнозирования, мы удаляемне- 1 слои из общей модели ствола. Пожалуйста, обратитесь к таблице S14 для модельных архитектур и таблице S13 для обзора гиперпараметров, которые мы используем в наших экспериментах.
3.1. Шкала преимуществ с размером модели
Чтобы изучить это явление, мы обучаем модели из шести размеров в параметрах диапазона от 300 до 13B с нуля на по меньшей мере 91B токенах кода. Оценка приводит на рисунке 3 для MBPP (Austin et al., 2021) и Humaneval (Chen et al., 2021), показывают, что возможно, с точно таким же вычислительным бюджетом, чтобы выжать гораздо большую производительность из крупных языковых моделей, полученных с фиксированным набором данных с использованием многоцелевого прогнозирования.
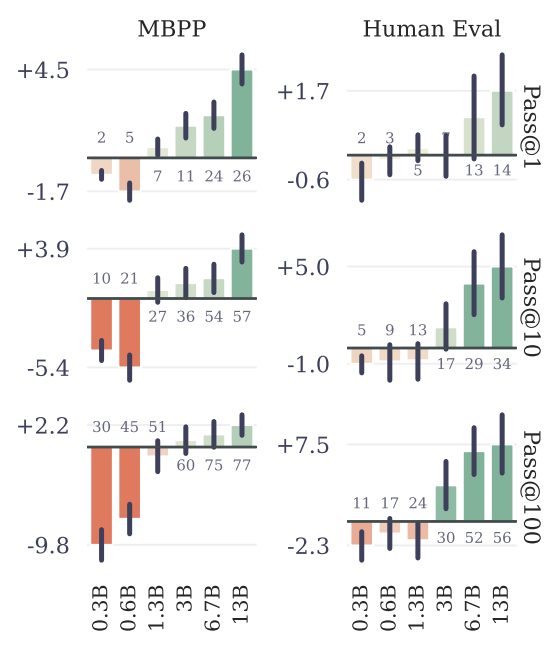
Мы верим в этополезность только в масштабеЧтобы быть вероятной причиной, почему многократный прогноз до сих пор в значительной степени упускается из виду как многообещающая потери тренировок для обучения модели с большой языком.
3.2. Более быстрый вывод
Мы внедряем жадныхСамопрокулятивное декодирование(Stern et al., 2018) с гетерогенными размерами партий с использованием Xformers (Lefaudeux et al., 2022) и измеряйте скорости декодирования нашей лучшей 4-то-точной модели прогнозирования с параметрами 7b при завершении подсказок, взятых из тестового набора данных кода и естественного языка (таблица S2), не наблюдаемые во время обучения. Мы наблюдаем ускорение 3,0 × код в среднем 2,5 принятых токена из 3 предложений по коду и 2,7 × на текст. На 8-байтовой модели прогнозирования ускорение вывода составляет 6,4 × (таблица S3). Предварительная подготовка с помощью многократного прогноза позволяет дополнительным головкам быть гораздо более точными, чем простое создание модели предсказания следующей точки, что позволяет нашим моделям разблокировать полный потенциал самопроизвольного декодирования.
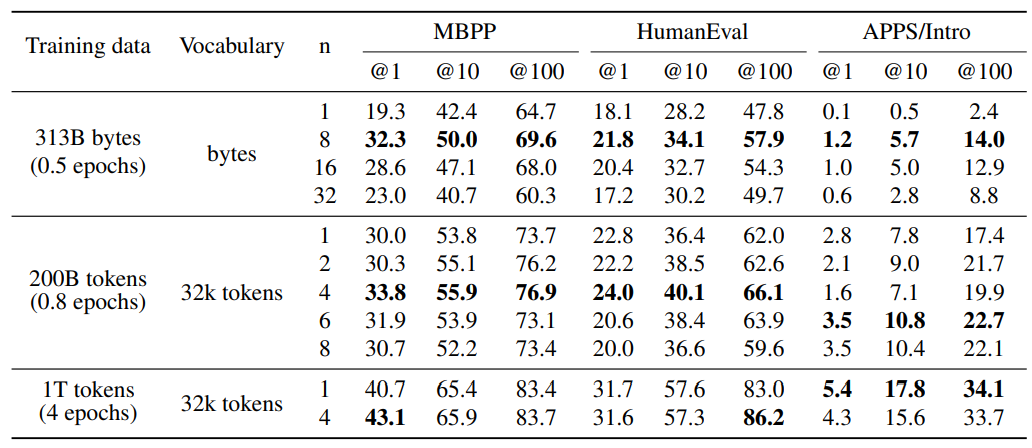
3.3. Обучение глобальным моделям с помощью много-байтового прогнозирования
Чтобы показать, что задача прогнозирования следующего ток привязывает локальные шаблоны, мы обратились к экстремальному случаю токенизации уровня байта, обучая трансформатор уровня параметров 7B на байтах 314B, что эквивалентно около 116B токенс. 8-байтовая модель прогнозирования достигает поразительных улучшений по сравнению с предсказанием следующего, решая на 67% больше проблем при проходе MBPP при проходе@1 и 20% больше проблем при проходе Гуманевала@1.
Поэтому многообещающий прогноз является очень многообещающим проспектом, чтобы открыть эффективное обучение моделей уровня байта. Самоспективное декодирование может достичь ускорения в 6 раз для 8-байтовой модели прогнозирования, что позволило бы полностью компенсировать стоимость более длинных последовательностей уровня байта во время вывода и даже быть быстрее, чем модель прогнозирования следующей точки почти на два раза. 8-байтовая модель прогнозирования представляет собой сильную модель на основе байтов, приближаясь к производительности моделей на основе токсов, несмотря на то, что была обучена на 1,7 × меньше данных.
3.4. Поиск оптимальногоне
Чтобы лучше понять влияние количества прогнозируемых токенов, мы сделали всеобъемлющие абляции на моделях масштаба 7b, обученных 200B токенам кода. Мы пробуем n = 1, 2, 4, 6 и 8 в этом настройке. Результаты в таблице 1 показывают, что обучение с 4-защитными токенами превосходит все остальные модели последовательно по всему гумане и MBPP для прохода при 1, 10 и 100 метрик: +3,8%, +2,1% и +3,2% для MBPP и +1,2%, +3,7% и +4,1% для HumaneVal. Интересно, что для приложений/вступления n = 6 берет лидерство с +0,7%, +3,0%и +5,3%. Весьма вероятно, что оптимальный размер окна зависит от распределения входных данных. Что касается моделей уровня байтов, оптимальный размер окна более последовательна (8 байтов) по этим критериям.
3.5. Обучение для нескольких эпох
Обучение с несколькими точками по-прежнему сохраняет преимущество над предсказанием следующего ток, когда обучается на нескольких эпохах одних и тех же данных. Улучшения уменьшаются, но у нас все еще есть увеличение на +2,4% при проходе@1 на MBPP и +3,2% увеличения на проходе@100 на Humaneval, в то же время имея аналогичные характеристики для остальных. Что касается приложений/вступления, размер окна 4 уже не был оптимальным с токенами 200b тренировок.
3.6 Создание нескольких предикторов
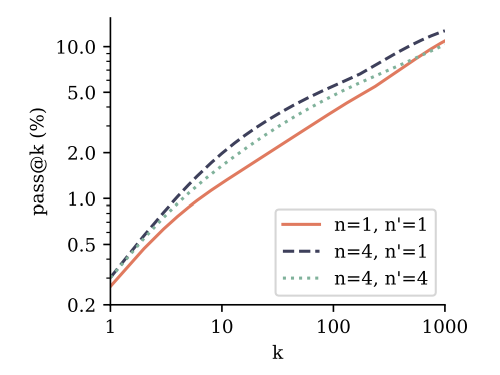
Предварительные модели с потерей прогнозирования с несколькими ток-точками также превосходят модели следующего ток для использования в Manetunings. Мы оцениваем это путем Manetuning 7B -моделей параметров из Раздела 3.3 в наборе данных CodeContests (Li et al., 2022). Мы сравниваем модель прогнозирования с 4-х позором с базовой линейкой прогнозирования следующего ток и включаем настройку, в которой модель прогнозирования с 4 ток-мышкой снимается с его дополнительных головок прогнозирования и создана с использованием классической цели прогнозирования следующего ток. Согласно результатам на рисунке 4, оба способа создания модели прогнозирования 4-ток превзошли следующую модель прогнозирования следующего ток на Pass@K через k. Это означает, что модели лучше понимают и решают задачу и генерируют разнообразные ответы. Обратите внимание, что CodeContests является наиболее сложным эталоном кодирования, который мы оцениваем в этом исследовании. Следующее предсказание прогнозирования на вершине 4-х дарового прогнозирования предварительно представляется лучшим методом в целом, в соответствии с классической парадигмой предварительной подготовки со вспомогательными задачами, за которыми следуют характеристика, специфичная для задачи. Пожалуйста, обратитесь к Приложению F для получения подробной информации.
3.7 Многократный прогноз на естественном языке
Чтобы оценить многократное обучение прогнозирования по естественному языку, мы обучаем модели параметров размера 7b на 200b токенах естественного языка с 4-то-токеном, 2-то-ток-потерей и следующей потерей прогнозирования, соответственно. На рисунке 5 мы оцениваем полученные контрольные точки на 6 стандартных контрольных показателях NLP. На этих критериях модель прогнозирования токенов с двумя итогами работает наравне с базовой линейкой предсказания следующего ток.
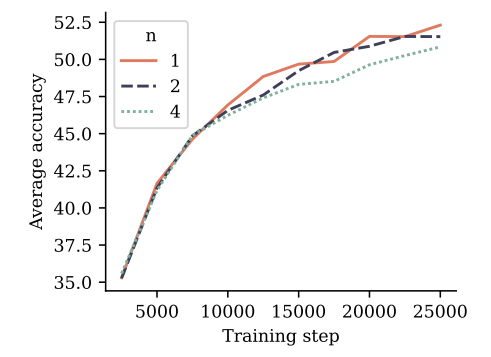
на протяжении всего обучения. Модель прогнозирования токенов с 4 итогами страдает деградацией производительности. Подробные цифры сообщаются в Приложении G.
Тем не менее, мы не считаем, что контрольные показатели на основе множественного выбора и вероятности подходят для эффективного различения генеративных возможностей языковых моделей. Чтобы избежать потребности в человеческих аннотациях качества генерации или языковых судей, которые поставляются с собственными ловушками, как указано Koo et al. (2023)-Мы проводим оценки по сравнению с суммированием и математикой естественного языка и сравниваем предварительные модели с размерами обучающих наборов токенов 200b и 500b, а также с потери прогноза с несколькими точками, соответственно.
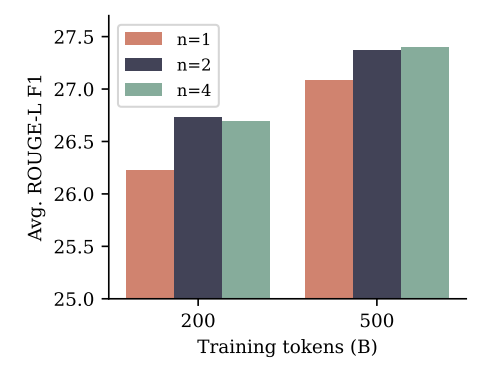
Для суммирования мы используем восемь тестов, где метрики Rouge (Lin, 2004) в отношении резюме грунта позволяют автоматической оценке сгенерированных текстов. Мы определяем каждую предварительную модель на наборе учебного данных каждого теста для трех эпох и выбираем контрольную точку с самой высокой оценкой Rouge-L F1 в наборе данных проверки. На рисунке 6 показано, что модели с несколькими токными прогнозирования как с n = 2, так и N = 4 улучшаются по сравнению с базовой линией следующего ток в Rouge-L F1-баллах для обоих размеров наборов обучения, а разрыв в производительности сокращается с большим размером набора данных. Все метрики можно найти в Приложении H.
Для математики естественного языка мы оцениваем предварительную модели в режиме 8 выстрелов на эталон GSM8K (Cobbe et al., 2021) и измеряем точность окончательного ответа, полученного после цепочки мыслей, вызванной примерами Marting Shot. Мы оцениваем метрики Pass@K, чтобы количественно оценить разнообразие и правильность ответов, как в оценках кода
и использовать температуру отбора проб от 0,2 до 1,4. Результаты изображены на рисунке S13 в Приложении I. Для 200B тренировочных токенов модель n = 2 явно превосходит базовую линию следующего ток-прогноза, в то время как шаблон меняется после 500B токенов, а n = 4 хуже во всем.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и равный вклад;
(2) Badr Youbi Idrissi, Fair at Meta, Lisn Université Paris-Saclayand и равный вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Meta и последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)