
Раскрывающее многократное предсказание: соединение пробелов в обучении с LookaheAde
18 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
2. Метод
3. Эксперименты по реальным данным
4. Абляции на синтетических данных
5. Почему это работает? Некоторые предположения
6. Связанная работа
7. Заключение, Заявление о воздействии, воздействие на окружающую среду, подтверждения и ссылки
A. Дополнительные результаты по самопрокативному декодированию
Б. Альтернативные архитектуры
C. Скорость тренировок
D. МАГАЗИН
E. Дополнительные результаты по поведению масштабирования модели
F. Подробности о CodeContests Manetuning
G. Дополнительные результаты по сравнению с естественным языком
H. Дополнительные результаты по абстрактному текстовому суммированию
I. Дополнительные результаты по математическим рассуждениям на естественном языке
J. Дополнительные результаты по индукционному обучению
K. Дополнительные результаты по алгоритмическим рассуждениям
L. Дополнительные интуиции по многоцелевым прогнозам
М. Обучение гиперпараметры
5. Почему это работает? Некоторые предположения
Почему Multi-Token прогнозирование обеспечивает превосходную производительность при оценке кодирования, а также о небольших алгоритмических задачах рассуждения? Наша интуиция, разработанная в этом разделе, состоит в том, что многоцелостное прогнозирование смягчает расхождение распределения между вынуждением преподавателя и авторегрессивным поколением времени обучения. Мы поддерживаем эту точку зрения иллюстративным аргументом о неявных весах, предсказание, предсказательно назначает токены в зависимости от их актуальности для продолжения текста, а также с теоретикой информационной теоретической разложения потерь прогнозирования с несколькими токками.
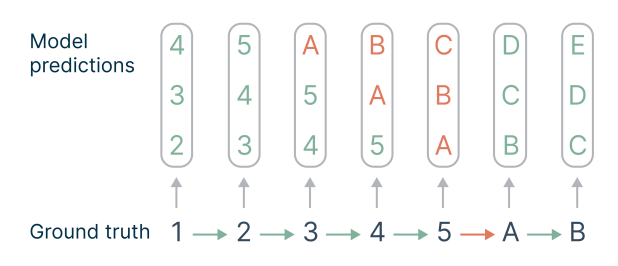
5.1. Lookahead Укрепляет очки выбора
Не все решения токенов одинаково важны для получения полезных текстов из языковых моделей (Bachmann and Nagarajan, 2024; Lin et al., 2024). В то время как некоторые токены разрешают стилистические вариации, которые не ограничивают оставшуюся часть текста, другие представляют точки выбора, которые связаны с семантическими свойствами более высокого уровня текста и могут решить, воспринимается ли ответ как полезный илисорвалПолем

5.2. Информация теоретичный аргумент
Языковые модели, как правило, обучаются преподавателям, где модель получает основную правду для каждого токена будущего во время обучения. Тем не менее, во время тестирования генерация времени не эксплуатируется и авторегрессирует, в результате чего накапливаются ошибки. Мы утверждаем, что преподавание поощряет модели, чтобы сосредоточиться на хорошо предсказании в очень краткосрочной перспективе, за потенциальные затраты на игнорирование долгосрочных зависимостей в общей структуре генерируемой последовательности.
Чтобы проиллюстрировать влияние многоцелевого прогнозирования, рассмотрите следующий теоретичный аргумент. Здесь X обозначает следующее будущее токен, а Y второе-токен Future Future. Производство обоих этих токенов обусловлено некоторым наблюдаемым входным контекстом C, который мы пропускаем из наших уравнений для простоты. При размещении перед токеном x, ванильный прогноз следующего тока касается количества h (x), в то время как многократное прогноз с n = 2 нацелен на H (x) + H (y). Мы разлагаем эти два количества как:
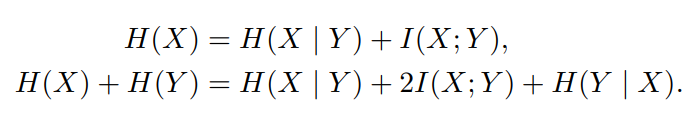
Отбросив термин H (y | x), который появляется снова при прогнозировании в следующем положении, мы наблюдаем, что 2-то-ток-прогноз увеличивает важность i (x; y) в течение 2. Таким образом, многократные предикторы более точны при прогнозировании токенов x, которые имеют отношение к остальному тексту. В Приложении L.2 мы даем относительную версию вышеуказанных уравнений, которые показывают повышенный вес относительной взаимной информации при разложении потерь 2-token потерь прогнозирования.
Авторы:
(1) Фабиан Глокл, ярмарка в Meta, Cermics Ecole des Ponts Paristech и равный вклад;
(2) Badr Youbi Idrissi, Fair at Meta, Lisn Université Paris-Saclayand и равный вклад;
(3) Baptiste Rozière, ярмарка в Meta;
(4) Дэвид Лопес-Паз, ярмарка в Meta и последний автор;
(5) Габриэль Синнев, ярмарка в Meta и последний автор.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27328)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)