

Распаковка Phi-3-Mini: архитектура, управляемая телефона, расширяется Power LLM Power
4 июля 2025 г.Таблица ссылок
Аннотация и 1 введение
2 технические характеристики
3 академические тесты
4 Безопасность
5 Слабость
6 Phi-3-Vision
6.1 Технические спецификации
6.2 академические тесты
6.3 Безопасность
6.4 Слабость
Ссылки
Пример подсказки для тестов
B Авторы (алфавитный)
C подтверждения
2 технические характеристики
Модель PHI-3-Mini представляет собой архитектуру декодера трансформатора [VSP+ 17], с длиной контекста по умолчанию 4K. Мы также вводим длинную контекстную версию через Longrope [dzz+ 24a], которая расширяет длину контекста до 128 тыс., Называется Phi-3-Mini-128K.
Чтобы наилучшим образом принести пользу сообществу с открытым исходным кодом, Phi-3-Mini построен на аналогичной структуре блоков, что и Llama-2 [tli+ 23], и использует один и тот же токензатор с размер словарного запаса 32064 [1]. Это означает, что все пакеты, разработанные для семейства моделей Llama-2, могут быть непосредственно адаптированы к Phi-3-Mini. Модель использует 3072 скрытого размера, 32 головы и 32 слоя. Мы тренировались, используя BFLOAT16 в общей сложности 3,3 т токенов. Модель уже проведена в чате, а шаблон чата заключается в следующем:

Модель PHI-3-ял (параметры 7B) использует токенизатор Tiktoken (для лучшей многоязычной токенизации) с размер словарного запаса 100352 [2] и имеет длину контекста по умолчанию 8192. Она следует за стандартным архитектурой декодера 4B-модельного класса, с 32 головами, 32 слоя и hidden Size Size 4096. Мы переключаем GLE-активацию GLE-nef-nef-nef-stica glu-stica and gelu-активацию на 32 головы, 32 слоя и hidden size 4096. Обновите параметризацию (MUP) [?] Настройку гиперпараметров на небольшую прокси -модель и перенесите их в модель Target 7B. Они помогли обеспечить лучшую производительность и стабильность обучения. Кроме того, модель использует внимание сгруппированного вопроса, с 4 запросами, разделяющими 1 ключ. Чтобы оптимизировать обучение и скорость вывода, мы разрабатываем новый модуль внимания блоков. Для каждой главы внимания внимание блокировки обеспечивает различные паттерны разреженности по сравнению с кэшем KV. Это гарантирует, что все токены посещаются на разных головах для данного выбора редкости. Как показано на рисунке 1, контекст затем эффективно разделяется и завоевывается среди головок внимания, со значительным снижением кеша кВ. Для достижения фактического ускорения развертывания от дизайна блоков мы внедрили высокоэффективные, но гибкие ядра как для обучения, так и для вывода. Для обучения мы строим ядро тритона на основе флэш -внимания [DFE+ 22]. Для вывода мы внедрили ядро для фазы предварительного профиля и расширили ядро с обратным вниманием в VLLM для фазы декодирования [KLZ+ 23]. Наконец, в архитектуре PHI-3-SMALL мы чередую плотные слои внимания и слои внимания блокировки для оптимизации экономии кэша KV, сохраняя при этом длительную производительность поиска контекста. Дополнительные 10% многоязычных данных также использовались для этой модели.
Высоко способная языковая модель, работающая локально по мобильному телефону.Благодаря своему небольшому размеру, PHI3-Mini может быть квантован до 4-битных, чтобы он занимал только ≈ 1,8 ГБ памяти. Мы протестировали квантовую модель, развернув Phi-3-Mini на iPhone 14 с A16 Bionic Chip, работающим национально на устройстве и полностью офлайн, достигая более 12 токенов в секунду.

Методология обучения.Мы следуем последовательности работ, инициированных в «Учебных книгах-это все, что вам нужно» [GZA+ 23], в которой используются высококачественные данные обучения для повышения производительности моделей малых языков и отклоняться от стандартных законов. В этой работе мы показываем, что такой метод позволяет достигать уровня высокоэффективных моделей, таких как GPT-3.5 или Mixtral, с общим параметром 3,8B (например, Mixtral имеет 45b общие параметры). Наши учебные данные состоит из сильно отфильтрованных общедоступных веб-данных (в соответствии с «уровнем образования») из различных открытых интернет-источников, а также синтетических данных, сгенерированных LLM. Предварительное обучение выполняется в двух непрерывных и последовательных этапах; Фаза-1 состоит в основном из веб-источников, направленных на обучение модели общим знаниям и пониманию языка. Фаза-2 объединяет еще более отфильтрованные WebData (подмножество, используемое в фазе-1) с некоторыми синтетическими данными, которые обучают модели логическим рассуждениям и различным нишевым навыкам.
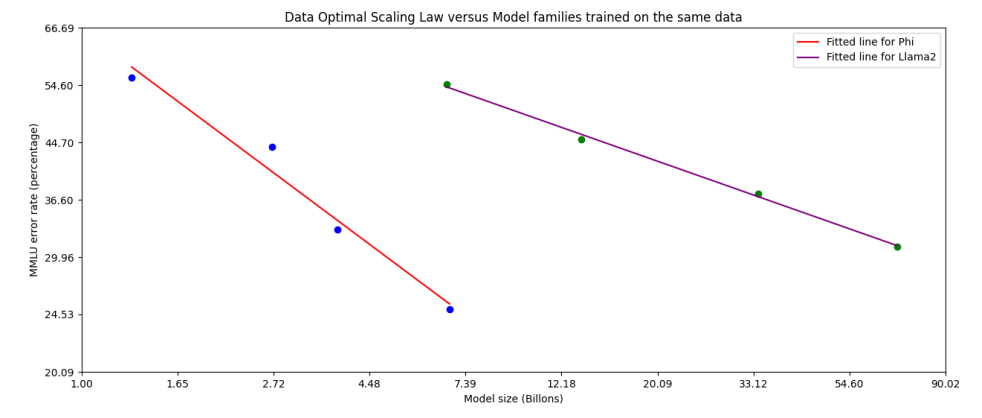
Оптимальный режим данных.В отличие от предыдущих работ, которые обучают языковые модели либо в «Вычислите оптимальный режим» [HBM+ 22], либо «режим переученика», мы в основном сосредотачиваемся на качестве данных для данной шкалы. [3] Мы стараемся калибровать учебные данные, чтобы быть ближе к «оптимальному» режиму данных для небольших моделей. В частности, мы отфильтровали общедоступные веб -данные, чтобы содержать правильный уровень «знаний» и сохраняем больше веб -страниц, которые потенциально могут улучшить «способность рассуждать» для модели. Например, результатом игры в Премьер -лиге в определенный день может быть хорошие учебные данные для пограничных моделей, но нам необходимо удалить такую информацию, чтобы оставить больше моделей для «рассуждений» для мини -размеров моделей. Мы сравниваем наш подход с Llama-2 на рисунке 3.
Чтобы проверить наши данные о большем размере моделей, мы также обучалисьPhi-3-Medium, модель с параметрами 14b с использованием того же такеизатора и архитектурыPhi-3-Miniи обучались тем же данным для немного большего количества эпох (всего 4,8t токенов, как и дляPhi-3-SmallПолем Модель имеет 40 голов и 40 слоев, с внедрением измерения 5120. Мы наблюдаем, что некоторые критерии улучшаются гораздо меньше с 7b до 14b, чем с 3,8b до 7b, возможно, указывая на то, что наша смесь данных требует дальнейшей работы, чтобы быть в «оптимальном режиме данных» для модели параметров 14b.
После тренировки.После тренировки PHI-3-Mini проходили два этапа, включая контролируемое создание Manetuning (SFT) и непосредственную оптимизацию предпочтений (DPO). SFT использует высококачественные высококачественные данные в разных областях, например, математике, кодировании, рассуждениях, разговоре, идентичности модели и безопасности. Смесь данных SFT начинается с использования примеров только на английском языке. Данные DPO охватывают данные формата чата, рассуждения и ответственные усилия по ИИ (RAI). Мы используем DPO, чтобы убрать модель от нежелательного поведения, используя эти выходы в качестве «отклоненных» ответов. Помимо улучшения математики, кодирования, рассуждений, устойчивости и безопасности, после тренировки преобразует языковую модель помощнику по искусственному интеллекту, с которым пользователи могут эффективно и безопасно взаимодействовать.
Как часть процесса после тренировки, мы разработали длинную контекстную версиюPhi-3-Miniс ограничением длины контекста, увеличенным до 128K вместо 4K. По всем направлениям качество модели 128K находится наравне с версией длины 4K, одновременно выполняя длительные контексты. Длинное расширение контекста было выполнено на двух этапах, включая длительный контекст среднего тренировок и длинно короткого смешанного пост-тренировки как с SFT, так и с DPO.
Авторы:
(1) Мара Абдин;
(2) Сэм Аде Джейкобс;
(3) Аммар Ахмад Аван;
(4) jyoti aneja;
(5) Ахмед Авадаллах;
(6) Hany Awadalla;
(7) Нгуен Бах;
(8) Амит Бахри;
(9) Араш Бахтиари;
(10) Цзянмин Бао;
(11) Харкират Бел;
(12) Алон Бенхайм;
(13) Миша Биленко;
(14) Йохан Бьорк;
(15) Sébastien Bubeck;
(16) Цин Цай;
(17) Мартин Кай;
(18) Caio César Teodoro Mendes;
(19) Вейджу Чен;
(20) Вишрав Чаудхари;
(21) Донг Чен;
(22) Дундонг Чен;
(23) Йен-Чун Чен;
(24) Йи-Линг Чен;
(25) Парул Чопра;
(26) Xiyang Dai;
(27) Элли Дель Джирно;
(28) Густаво де Роза;
(29) Мэтью Диксон;
(30) Ронен Эльдан;
(31) Виктор Фаросо;
(32) Дэн Итер;
(33) Мэй Гао;
(34) мин Гао;
(35) Цзянфенг Гао;
(36) Амит Гарг;
(37) Абхишек Госвами;
(38) Сурия Гунасекар;
(39) Эмман Хайдер;
(40) Junheng Hao;
(41) Рассел Дж. Хьюитт;
(42) Джейми Хьюнх;
(43) Mojan Javaheripi;
(44) Синь Джин;
(45) Пьеро Кауфманн;
(46) Никос Карампатцциакис;
(47) Dongwoo Kim;
(48) Махоуд Хадеми;
(49) Лев Куриленко;
(50) Джеймс Р. Ли;
(51) Инь Тэт Ли;
(52) Юаньжи Ли;
(53) Юншенг Ли;
(54) Чен Лян;
(55) Ларс Лиден;
(56) CE Liu;
(57) Менгхен Лю;
(58) Вайшунг Лю;
(59) Эрик Лин;
(60) Zeqi Lin;
(61) Чонг Луо;
(62) Пиюш Мадан;
(63) Мэтт Маццола;
(64) Ариндам Митра;
(65) Хардик Моди;
(66) ANH NGUYEN;
(67) Брэндон Норик;
(68) Барун Патра;
(69) Даниэль Перес-Бекер;
(70) Портет Томаса;
(71) Рейд Прайзант;
(72) Хейанг Цинь;
(73) Марко Радмилак;
(74) Корби Россет;
(75) Самбудха Рой;
(76) Olatunji Ruwase;
(77) Олли Саарикиви;
(78) Амин Саид;
(79) Адил Салим;
(80) Майкл Сантакрос;
(81) Шитал Шах;
(82) Нин Шан;
(83) Хитеши Шарма;
(84) Свадхин Шукла;
(85) Sia Song;
(86) Масахиро Танака;
(87) Андреа Тупини;
(88) Синь Ван;
(89) Лиджуань Ван;
(90) Чуню Ван;
(91) Ю Ван;
(92) Рэйчел Уорд;
(93) Гуанхуа Ван;
(94) Филипп Витте;
(95) haiping wu;
(96) Майкл Уайетт;
(97) бен Сяо;
(98) может XU;
(99) Цзяхан Сюй;
(100) Weijian Xu;
(101) Сонали Ядав;
(102) вентилятор Ян;
(103) Цзяньвей Ян;
(104) Зийи Ян;
(105) Йифан Ян;
(106) Донган Ю;
(107) Лу Юань;
(108) Chengruidong Zhang;
(109) Кирилл Чжан;
(110) Цзянвен Чжан;
(111) Ли Лина Чжан;
(112) И Чжан;
(113) Юэ Чжан;
(114) Юнан Чжан;
(115) Ксирен Чжоу.
Эта статья есть
[1] Мы удаляем токены BOS и добавляем дополнительные токены для шаблона чата.
[2] Мы удаляем неиспользованные токены из словарного запаса.
[3] Как и для «вычислительного оптимального режима», мы используем термин «оптимальный» в желательном смысле для «оптимального режима данных». Мы не подразумеваем, что на самом деле нашли доказуемо «оптимальную» смесь данных для данной шкалы.
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)