
Понимание направлений масштабируемости платформ технических данных
16 февраля 2023 г.Техническая масштабируемость является одним из основных факторов платформы данных, как указано в Методология SOFT. Но какие есть варианты? В этом блоге мы оценим направление масштабируемости и компромиссы, с которыми вы можете столкнуться в процессе принятия решения.
Основные направления технической масштабируемости
Вертикальная масштабируемость
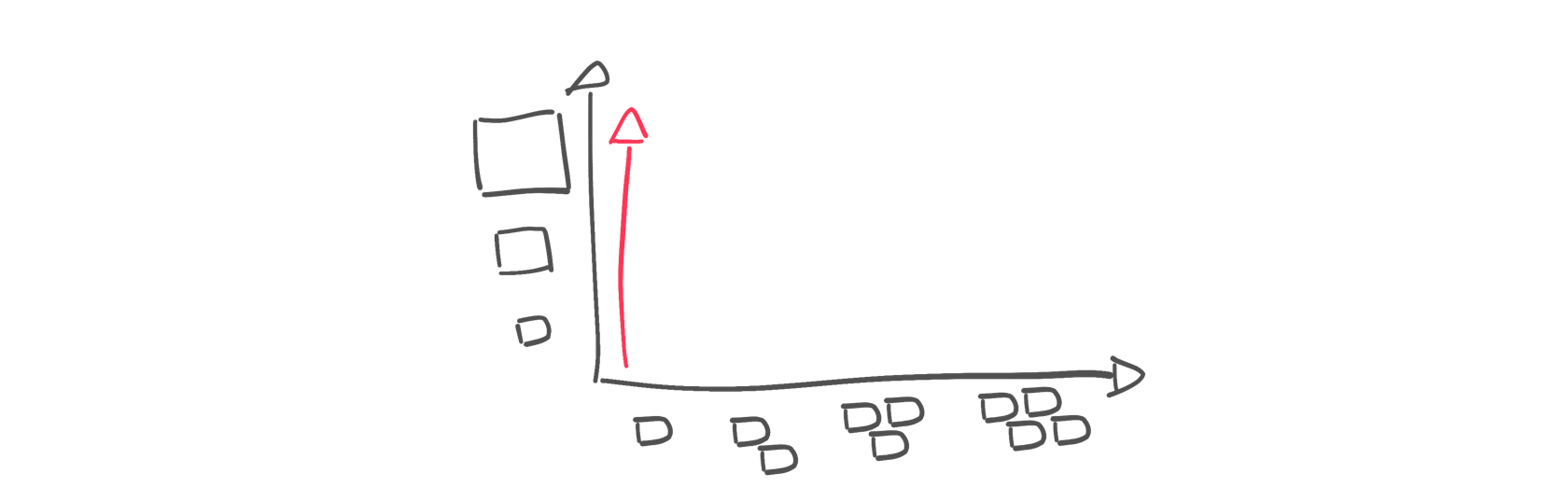
Вертикальная масштабируемость обычно означает «купить большую коробку»: то, чего нельзя достичь с сервером размера X, можно достичь с сервером размера 2X. Существует множество платформ данных, которые допускают такой тип масштабирования, и со всеми вариантами, доступными сейчас на рынке облачных вычислений, вертикальная масштабируемость может дать вам ооооооооооооооооооооооооооооооооооооооооойчехххххх.
За:
- Без изменений в архитектуре
- Простая оценка новой эффективности.
Минусы:
- Ограничения ресурсов на одном компьютере
- Стоимость одной большой машины превышает стоимость нескольких небольших машин.
- Нагрузка распараллеливается только внутри машины.
Горизонтальная масштабируемость
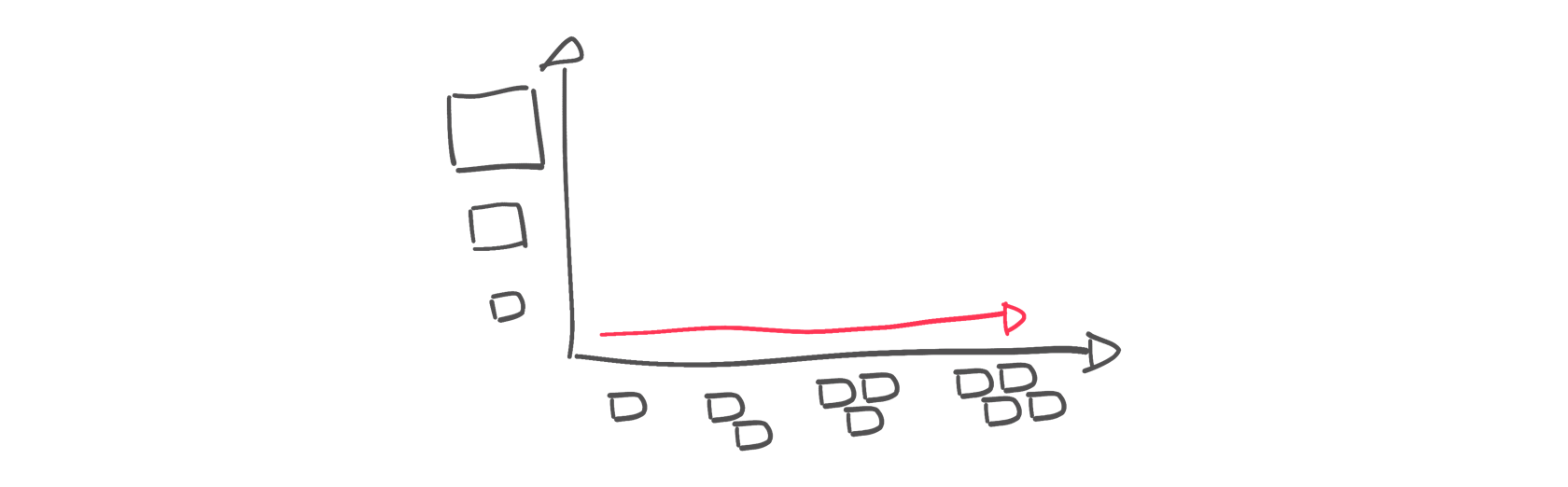
Горизонтальная масштабируемость идет в противоположном направлении: вместо более крупной машины мы распределяем рабочую нагрузку между несколькими меньшими машинами. Обычно он доступен в распределенных системах, где рабочая нагрузка распределяется между узлами. Apache Kafka — отличный пример: его распределенный характер позволяет подключать узлы к кластеру и отключать их, а также выполнять автоматическую перебалансировку данных и обязанностей между узлами.
За:
- Простое/быстрое подключение новых ресурсов
- Стоимость более мелких машин обычно меньше стоимости одной большой машины.
- Нагрузка распределяется по всему кластеру
Минусы:
- Доступно только в распределенных системах.
- Изменение архитектуры кластера для каждого нового добавляемого узла
- Данные реплицируются
- Может привести к согласованности.
Диагональная масштабируемость
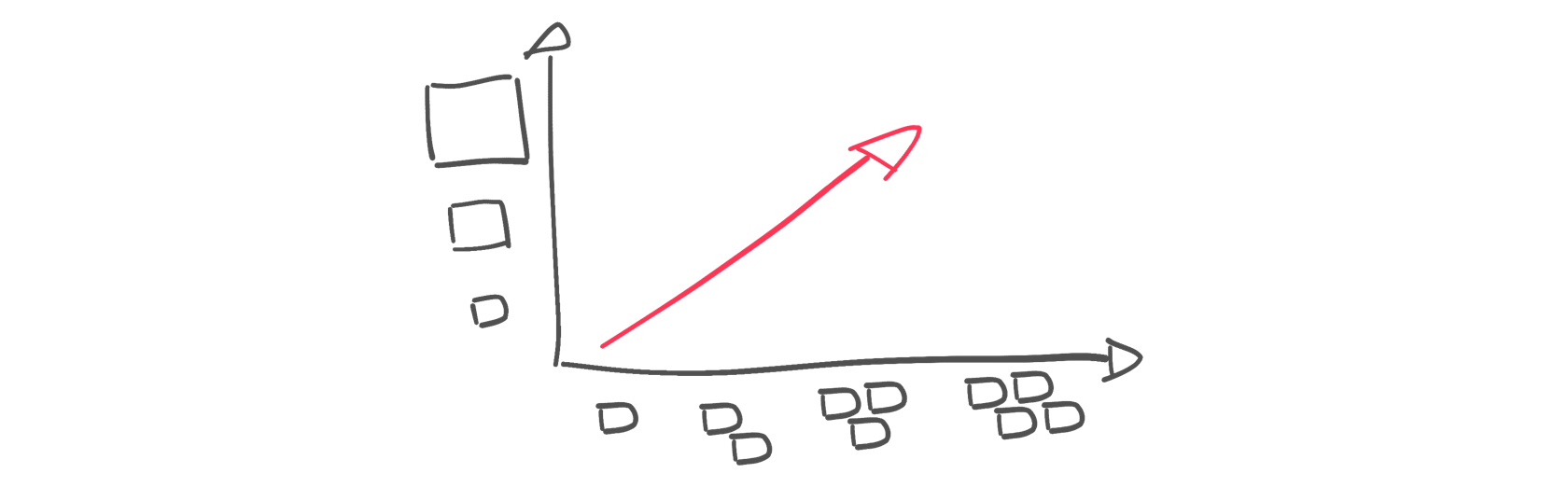
Конечно, возможно сочетание этих двух способов в ситуациях, когда мы можем добавить узлы в кластер и в то же время заменить существующие узлы новыми узлами повышенной емкости. Обычно сценарий аналогичен горизонтальной масштабируемости, единственное изменение заключается в том, что новые узлы имеют другие (обычно повышенные) характеристики по сравнению с предыдущими.
Другой способ масштабирования «по диагонали» — создание разных узлов для разных целей. Взяв, к примеру, PostgreSQL, можно выбрать вертикальное масштабирование основного сервера, а также горизонтальное масштабирование для создания одной или нескольких «реплик только для чтения», которые могли бы выполнять весь трафик только для чтения, освобождая основной сервер от части рабочей нагрузки.
За:
- Свобода масштабирования в обоих направлениях
Минусы:
- Не всегда доступно
- Для некоторых технологий рабочая нагрузка (например, операции записи) не может быть разделена между всеми узлами.
Межтехнологическая масштабируемость
Не все рабочие нагрузки должны выполняться в рамках одной технологии данных: как и в предыдущем примере с репликами PostgreSQL только для чтения, разные узлы кластера могут выполнять разные рабочие нагрузки. Продолжая пример, можно масштабировать, сохраняя транзакционные данные в PostgreSQL, а затем интегрируя ClickHouse для аналитических рабочих нагрузок. Такая межтехнологическая масштабируемость позволяет оптимизировать каждый компонент для одного использования и масштабировать независимо друг от друга.
За:
- Платформы данных, оптимизированные для рабочих нагрузок
- Независимый, зависящий от рабочей нагрузки, масштабируемый
Минусы:
- Синхронизация данных между технологиями
Проблемы масштабирования платформы данных
Если бы масштабирование платформы данных было простой задачей, мы бы не говорили об этом много. Операция масштабирования сопряжена с некоторыми проблемами.
Где хранятся данные?
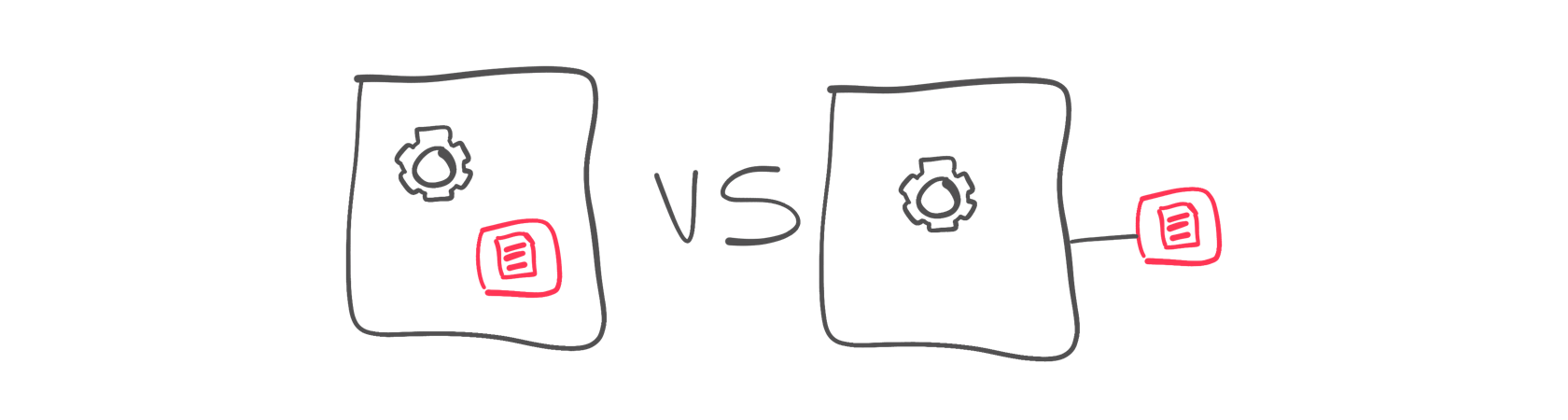
Для достижения оптимальной производительности и сведения к минимуму любых задержек в сети платформы данных исторически сохраняли совместное хранилище данных и вычислительные ресурсы. В последнее время новая тенденция отделения вычислений от хранилища (см. Snowflake, neon) позволила использовать дополнительные варианты масштабирования для независимого увеличения диска и ЦП за счет (небольшой) дополнительной задержки. Компромисс между производительностью (немедленный локальный доступ), изоляцией рабочей нагрузки/независимым масштабированием.
Кроме того, если данные находятся рядом с вычислительными ресурсами, их необходимо перемещать при выполнении, например, вертикального масштабирования.
Посмотрите это видео на YouTube от Гвен Шапира, чтобы узнать больше
Время масштабироваться
В зависимости от архитектуры время масштабирования может варьироваться от долей секунды (в случае, если необходимо запустить только новый вычислительный экземпляр) до часов (в случае необходимости восстановления огромных резервных копий). Оценка времени масштабирования необходима для понимания порогов масштабирования: например. если можно выполнить масштабирование за 10 секунд, параметр масштабирования может быть запущен при мощности 95 %, если масштабирование занимает несколько часов, пороговое значение необходимо снизить.
Время простоя
Никто не хочет простоя, особенно когда нужно масштабировать, чтобы соответствовать растущему спросу. Однако нужно понимать и оценивать:
* сколько работы можно сделать без изменений в исходной системе * как долго длится время простоя при переключении (если есть) * как и как быстро клиенты могут повторно синхронизировать параметры соединения
Ответы на приведенные выше вопросы помогут понять, как свести к минимуму недоступность системы.
Дополнительная нагрузка, вызванная масштабированием
Операция масштабирования может привести к дополнительной нагрузке на систему, например. при изменении потоковой передачи с одного узла на другой. Оценка того, как дополнительная нагрузка может повлиять на производительность системы, должна быть выполнена заранее, чтобы гарантировать предоставление достаточного обслуживания во время процедуры масштабирования.
Не все рабочие нагрузки одинаковы
Как упоминалось ранее, тип масштабирования зависит от архитектуры и рабочих нагрузок: добавление реплики только для чтения в определенном облачном регионе — это довольно недорогое решение, позволяющее снизить нагрузку на основную базу данных PostgreSQL. Тем не менее, решение не работает, когда в игре много рабочих нагрузок по записи.
Резервное копирование/восстановление
Какое отношение имеет резервное копирование/восстановление к масштабированию? Что ж, некоторые технологии (привет, PostgreSQL!) сначала восстанавливают копию базы данных из резервной копии, а затем начинают потоковую передачу дельты из первичной. Поэтому в таких случаях наличие готовой и актуальной резервной копии позволяет сократить время масштабирования.
Больше данных — больше рисков
В некоторых сценариях, представленных выше, масштабирование выполняется путем добавления новых узлов в кластер или добавления новых технологий. Даже если эти варианты обеспечивают большие преимущества в параллелизме и разделении рабочих нагрузок, они добавляют дополнительные шаги в пути к данным.
Каждый раз, когда данные хранятся на нескольких серверах, всегда существует вероятность несинхронизированных реплик. Каждый раз, когда вы добавляете новый переход данных, всегда возникают дополнительные сложности с сетью, интеграцией и т. д.
Заключение
Эта статья посвящена широкому спектру возможностей масштабирования и связанным с ними вопросам. При разработке платформы данных проблема масштабируемости (не только техническая, см. методологии, чтобы узнать больше) должно быть важным фактором при принятии решения при оценке решения на основе подчеркнутых технологий, ожидаемых рабочих нагрузок и бизнес-ограничений.
:::информация Также опубликовано здесь.
:::
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27222)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)