Сложности Интернета легко принять как должное, поскольку мы ежедневно беспрепятственно просматриваем различные веб-сайты. Мы вводим URL-адрес в наш браузер, и через несколько секунд появляется целый веб-сайт. Но задумывались ли вы когда-нибудь о технологиях и процессах, которые делают это возможным? В этой статье рассматриваются различные компоненты и технологии, которые превращают, казалось бы, легкий доступ в Интернет в реальность.
Кроме того, вам не нужно знать, как работает Интернет, чтобы писать код. Но это поможет вам понять всю систему.
Что происходит, когда мы пытаемся получить доступ к веб-сайту
Мы знаем, что код нашего веб-сайта не хранится на нашем компьютере. Нам нужно получить код на наш компьютер или браузер, где он хранится, чтобы посетить веб-сайт. Как это происходит?
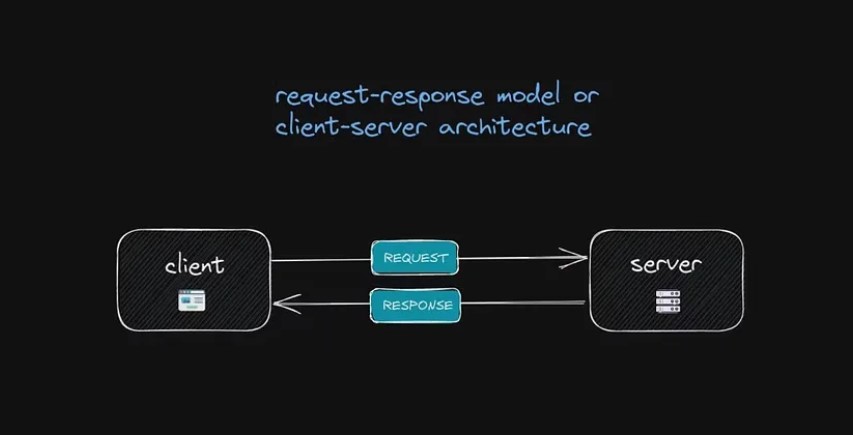
Процесс довольно прост. Когда мы вводим URL-адрес в наш браузер, браузер отправляет запрос необходимых данных на сервер. Затем сервер отвечает, отправляя код и данные для веб-сайта. Браузер интерпретирует коды и отображает веб-сайт для просмотра. Этот процесс известен как модель запрос-ответ или архитектура клиент-сервер.
Что такое клиенты и серверы?
Клиенты – это устройства, подключенные к Интернету, например наши телефоны или компьютеры, подключенные к мобильной сети или Wi-Fi. Клиент — это место, где происходит все взаимодействие с пользователем. В контексте Интернета клиент обычно представляет собой программное обеспечение для доступа к сети, такое как браузер, такой как Chrome, Firefox или Safari, которое запрашивает веб-страницы и другие ресурсы с сервера. Клиент (веб-браузер) получает код веб-сайта, а затем отображает его для просмотра пользователем. Хотя мы заходим на веб-сайт из браузера, мы можем рассматривать все устройство как клиент клиент-серверной архитектуры.
На другом конце спектра находятся серверы, специализированные компьютеры, предназначенные для хранения и управления данными, веб-сайтами и веб-приложениями. Эти серверы называются так потому, что они обслуживают код или данные в ответ на запросы клиентов. Сервер ожидает поступления запросов от клиентов, обрабатывает запрос, а затем отправляет обратно запрошенную информацию. Существуют различные типы серверов, такие как веб-серверы, файловые серверы и серверы баз данных, каждый со своей конкретной функцией. В этой статье мы сосредоточимся в первую очередь на веб-серверах.
Что такое URL и как его разрешить?
URL (унифицированный указатель ресурса) – это строка символов, указывающая расположение ресурса в Интернете. URL-адреса используются для идентификации и поиска веб-страниц, изображений, видео и других ресурсов во всемирной паутине. URL-адреса обычно состоят из нескольких частей, включая протокол, доменное имя и путь.
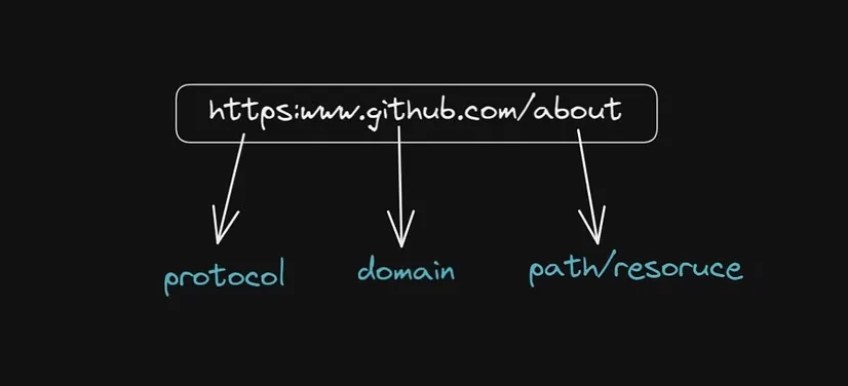
* Протокол — это метод, используемый для передачи данных через Интернет. Наиболее распространенным протоколом, используемым в Интернете, является HTTP (протокол передачи гипертекста) или HTTPS (HTTP Secure), более безопасная версия HTTP, которая шифрует данные для дополнительной безопасности. * Доменное имя — это уникальное имя, которое идентифицирует веб-сайт или веб-сервер в Интернете. Чтобы получить доступ к веб-сайту, имя вводится в адресную строку браузера. Например, «github.com» — это доменное имя веб-сайта Github. * Путь указывает расположение ресурса на сервере. Эта часть URL-адреса обычно включает имя файла или папки, содержащей ресурс, например «о» или «контакт». Например, «github.com/about» — это путь к странице «О сайте» веб-сайта «github.com». * При желании URL-адрес может также включать строку запроса, набор символов, добавленный в конец URL-адреса, который содержит дополнительную информацию или параметры для ресурса.
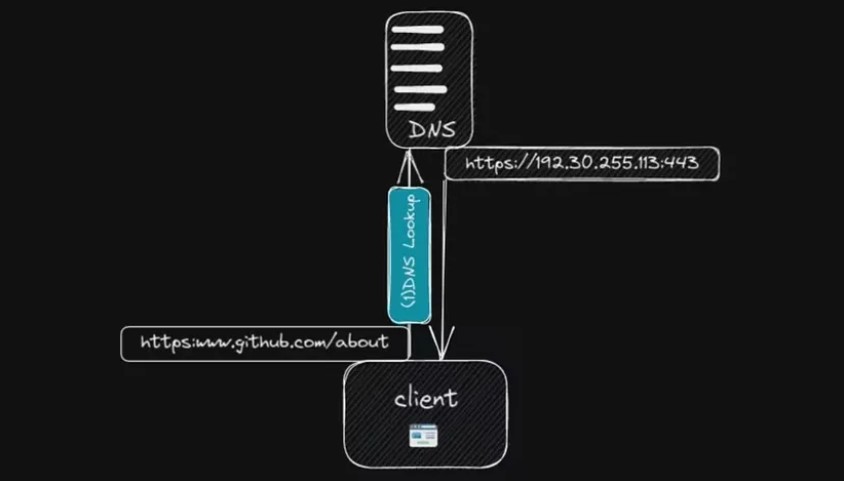
Интересно отметить, что доменное имя, которое мы вводим в браузере, не является фактическим физическим адресом веб-сайта. Каждый веб-сайт и устройство, подключенное к Интернету, имеет уникальный IP-адрес, цифровую метку, которую часто трудно запомнить. Чтобы облегчить запоминание, мы используем доменные имена. При вводе URL-адреса браузер сначала отправляет запрос на сервер DNS (система доменных имен), который сопоставляет доменное имя с соответствующим IP-адресом веб-сайта. Это называется поиском DNS. Этот процесс поддерживается вашим интернет-провайдером и возвращает IP-адрес, включая номер порта сервера, к которому осуществляется доступ.
Установка протоколов
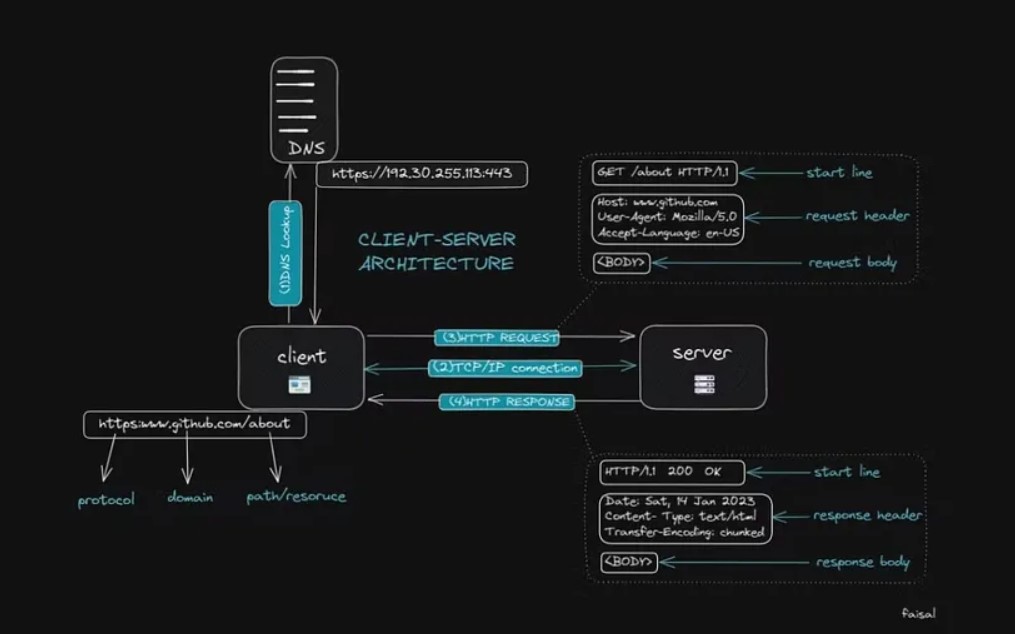
Когда мы вводим веб-адрес и получаем фактический IP-адрес веб-сайта в браузере, между браузером и сервером устанавливается соединение, известное как сокет TCP/IP. Это соединение остается активным, пока файлы передаются с сервера на клиент.
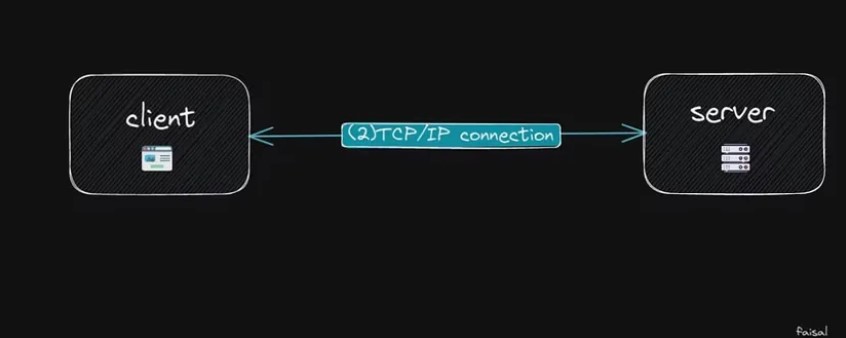
TCP (протокол управления передачей) и IP (интернет-протокол) — два основных протокола, составляющих набор интернет-протоколов (IP). Вместе они обеспечивают основу для общения в Интернете.
TCP (протокол управления передачей) — это один из основных протоколов набора интернет-протоколов (TCP/IP), который используется для установления и поддержания соединений между устройствами в сети. Основная функция TCP — обеспечить надежную доставку данных между устройствами.

TCP разбивает данные на небольшие фрагменты, называемые пакетами, прежде чем они будут отправлены по сети. Каждый пакет помечен заголовком TCP, который включает номера портов источника и получателя, а также заголовком IP, состоящим из IP-адресов источника и получателя, для его идентификации. Каждый пакет также содержит порядковый номер, который позволяет принимающему устройству собирать пакеты в правильном порядке. Если пакет потерян или поврежден во время передачи, TCP автоматически повторно передаст пакет, чтобы убедиться, что все пакеты получены правильно.
Этот протокол также обеспечивает управление потоком и контроль перегрузки. Управление потоком гарантирует, что отправитель не перегружает получателя, отправляя слишком много данных за раз, а управление перегрузкой гарантирует, что сеть не будет перегружена из-за слишком большого трафика.
Это протокол, ориентированный на установление соединения, который устанавливает виртуальное соединение между отправителем и получателем перед обменом какими-либо данными. После установления соединения обе стороны могут надежно и упорядоченно обмениваться данными.
TCP широко используется во многих приложениях, включая просмотр веб-страниц, электронную почту, передачу файлов и онлайн-игры. Это надежный и эффективный протокол, обеспечивающий доставку данных правильно и в правильном порядке, что делает его неотъемлемой частью интернет-инфраструктуры.
С другой стороны, IP-адреса и маршрутизация пакетов между устройствами в сети. Он назначает уникальный IP-адрес каждому устройству, подключенному к Интернету. Когда данные отправляются с одного устройства на другое, IP-протокол определяет адрес назначения и наилучший маршрут для данных. Его задача — отправлять и маршрутизировать все пакеты через Интернет.
TCP и IP работают вместе, чтобы обеспечить надежную и эффективную связь в Интернете. IP-адреса и маршруты пакетов данных, в то время как TCP гарантирует, что данные будут доставлены правильно и в правильном порядке. Это протоколы связи или основная система управления Интернетом, которая определяет и устанавливает правила того, как данные перемещаются по сети. Коммуникационный протокол устанавливает правила взаимодействия между двумя или более сторонами.
Как только соединение установлено, процесс связи начинается с HTTP-запроса, отправленного из браузера. HTTP, или протокол передачи гипертекста, является стандартным протоколом для передачи данных через Интернет и является основой всемирной паутины. Он позволяет браузеру отправлять запросы на веб-сервер и получать от него ответ.
HTTP основан на модели запрос-ответ, которую мы обсуждали ранее, в которой клиент (например, веб-браузер) отправляет запрос на сервер, а сервер отправляет ответ.
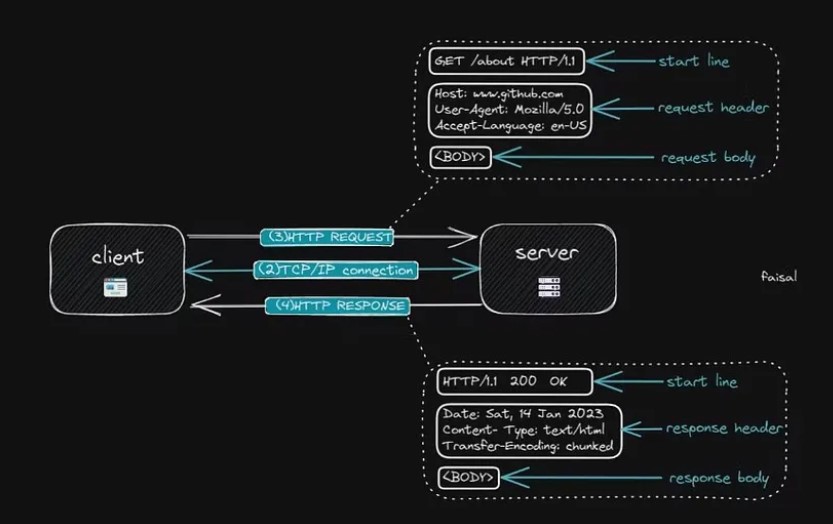
HTTP-запрос состоит из нескольких частей, включая начальную строку (метод HTTP + цель запроса + версия HTTP), заголовок HTTP-запроса и тело запроса.
Наиболее распространенными методами HTTP являются GET, который запрашивает ресурс с сервера, и POST, который отправляет данные на сервер для обработки. Существуют также методы PUT и Patch, которые используются для изменения данных.
HTTP находится поверх стека протоколов TCP/IP. Обычно он используется с протоколами SSL/TLS (Secure Sockets Layer/Transport Layer Security) для обеспечения безопасной и зашифрованной связи через Интернет.
Когда сервер получает запрос, он обрабатывает его и отправляет ответ HTTP. HTTP-ответ состоит из нескольких частей:
* Начальная строка включает версию HTTP, код состояния и сообщение. Версия HTTP указывает, какая версия протокола HTTP используется. Код состояния представляет собой трехзначный числовой код, указывающий на результат запроса. Сообщение о состоянии представляет собой краткое текстовое описание кода состояния. * Заголовок ответа HTTP содержит дополнительную информацию об ответе, например тип содержимого в теле ответа, дату и время отправки ответа и имя сервера. * Тело ответа содержит фактические данные или запрошенный HTML-файл.
Разработчик серверной части отвечает за указание данных, включенных в заголовок ответа. Эти данные могут включать такие вещи, как тип контента, дату и время, а также имя сервера. В теле ответа мы получаем данные или файл HTML, запрошенный в исходном запросе. Если сервер не может найти запрошенную страницу, он отправит сообщение об ошибке HTTP 404, указывающее, что страница не может быть найдена.
Что произойдет после того, как наш браузер получит ответ?
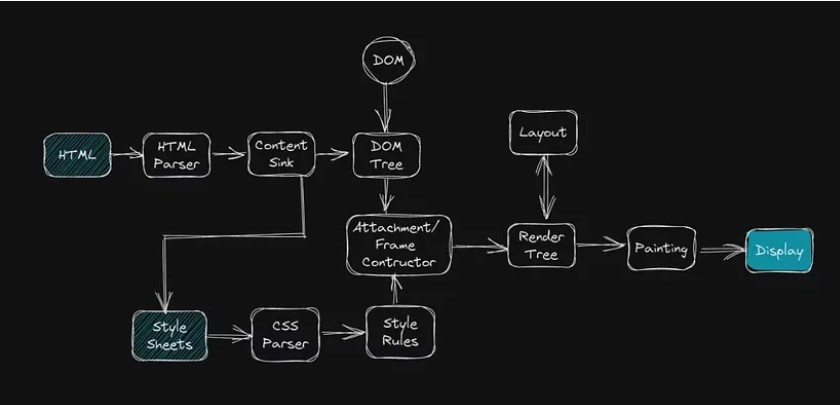
Когда веб-браузер получает документ HTML (язык гипертекстовой разметки) с веб-сервера, он анализирует документ, чтобы преобразовать его в визуальное представление, которое может отображаться пользователю. Процесс анализа HTML-документа включает следующие шаги:
* Браузер начинает с чтения HTML-кода сверху вниз, строка за строкой.
* При чтении кода браузер ищет теги, которые используются для определения структуры и макета документа. Например, тег указывает на начало HTML-документа, а теги
и указывают на начало разделов заголовка и тела документа соответственно. Браузер понимает, как интерпретировать код с помощью алгоритма разбора HTML.* Когда браузер встречает теги, он создает соответствующие элементы в объектной модели документа (DOM), древовидном представлении HTML-документа. Браузер использует его, чтобы понять, как страница должна отображаться и отображаться. Каждый элемент в DOM соответствует одному тегу в коде HTML, и мы можем манипулировать этими элементами с помощью языка сценариев, такого как JavaScript.
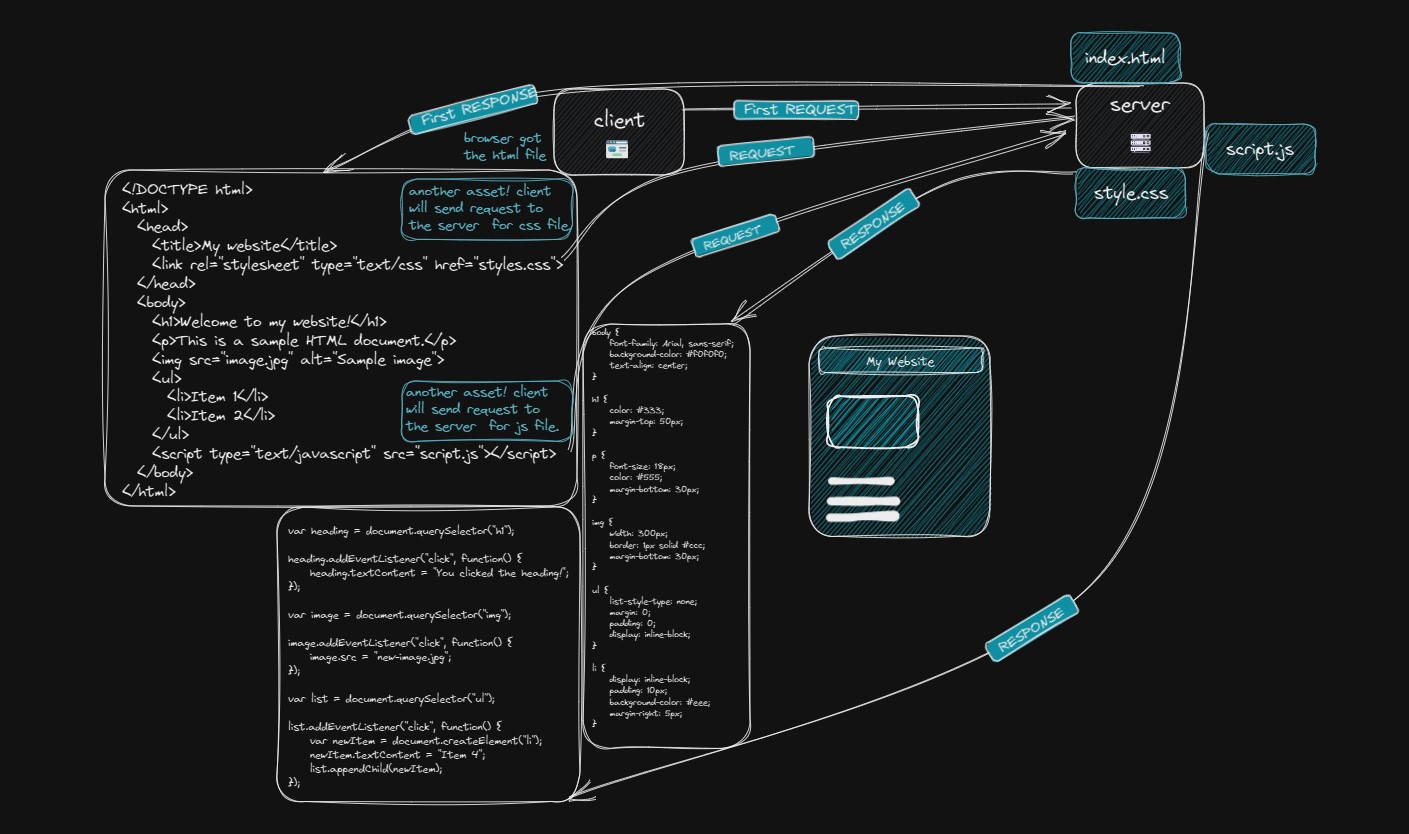
* Браузер сканирует документ на наличие дополнительных ресурсов для правильного отображения страницы. Эти активы могут включать файлы CSS, файлы JavaScript, изображения и другие мультимедийные файлы. Когда браузер встречает ссылку на ресурс в HTML-документе, он отправляет дополнительный запрос на сервер для извлечения этого ресурса. Браузер будет повторять этот процесс для каждого ассета, с которым он столкнется. Например, если HTML-документ ссылается.
* Для файла CSS браузер запросит у сервера получение этого файла. Затем файл CSS будет проанализирован и использован для применения визуальных стилей к элементам, определенным в HTML. Точно так же, если на странице есть изображения, браузер отправит запрос на сервер для каждого изображения и отобразит их на странице. Важно отметить, что браузер будет загружать и анализировать только те ресурсы, которые необходимы для текущего окна просмотра или видимой части веб-страницы. Это называется ленивой загрузкой. Когда пользователь прокручивает страницу вниз, браузер загружает и анализирует дополнительные ресурсы по мере необходимости. Эта загрузка и анализ дополнительных ресурсов может повлиять на производительность веб-страницы, поскольку для извлечения и обработки этих файлов может потребоваться время. Поэтому разработчикам необходимо оптимизировать загрузку этих ресурсов, чтобы страница загружалась быстро и эффективно.
* Важно понимать, что HTML не предоставляет информацию о том, как веб-сайт должен выглядеть визуально. Он только определяет структуру и сообщает браузеру различные части содержимого, такие как заголовки, изображения и абзацы.
* CSS (каскадные таблицы стилей) обеспечивает визуальное оформление и представление информации для веб-страницы. CSS позволяет разработчикам указывать шрифт, цвет, размер и положение элементов на веб-странице, а также другие визуальные свойства. CSS можно связать с документом HTML, и он будет использоваться для применения стилей к элементам, определенным в HTML.
* Браузер также использует JavaScript для добавления динамических функций на веб-страницы, таких как проверка форм и интерактивные элементы.
* После завершения анализа браузер отображает визуальное представление HTML-документа, с которым пользователь может взаимодействовать и просматривать его в окне браузера.
Процесс синтаксического анализа сложен, но он выполняется быстро и эффективно современными веб-браузерами, что позволяет пользователям беспрепятственно взаимодействовать с веб-страницами. После всего разбора соединение закрывается.
Это все! Однако многие другие сложные процессы и технологии обеспечивают функционирование Интернета. Эта статья должна дать вам обзор основных частей Интернета, но имейте в виду, что в Интернете есть еще много всего, что нужно изучить и изучить.
Также опубликовано здесь
Если вам понравилось это читать, не стесняйтесь связаться со мной в Twitter или проверить мой другие статьи.
Приятного обучения!