:::информация Авторы:
(1) Натан Ламберт, Институт искусственного интеллекта Аллена;
(2) Роберто Каландра, Технический университет Дрездена.
:::
Таблица ссылок
Понимание несоответствия целей
4. Понимание несоответствия целей
Цельное несоответствие в RLHF возникает по трем основным причинам: во-первых, общепринятая практика в разработке RL гласит, что по мере увеличения вознаграждения модель улучшается. Во-вторых, методы оценки, доступные для моделей, обученных с помощью RLHF, часто являются неполными по сравнению с их последующими вариантами использования. В-третьих, предположение, что обученная модель вознаграждения является подходящей функцией вознаграждения для оптимизации. По этим причинам объективное несоответствие возникает из-за предположения, что последующая оценка будет коррелировать с оценкой модели вознаграждения для текущей политики, что не доказано.
4.1 Причины несоответствия
Объективное несоответствие в RLHF является результатом взаимодействия между тремя различными подкомпонентами, а не только двумя (т. е. моделью динамики и политикой) из MBRL: это баланс обучения модели вознаграждения, цель получения калиброванная функция вознаграждения, обучение политике, процесс единообразного извлечения информации из модели вознаграждения и часто специальные методы оценки, используемые для моделей RLHF, процесс справедливой оценки многоцелевой модели. Между каждой парой из этих трех существует интерфейс, который обеспечивает ось для ошибочных предположений относительно истинной проблемы оптимизации, но важность каждого звена не является одинаковой для смягчения последствий.
Обучение модели вознаграждения ↔ Обучение модели политики Равномерное извлечение информации из модели вознаграждения в политику и предотвращение взлома вознаграждений, свойственного RL (Пан, Бхатия и Стейнхардт, 2022), которое может привести к чрезмерной оптимизации модели вознаграждения (Gao et al., 2022) занимают центральное место в RLHF. Хорошая модель вознаграждения может быть не такой, на которой эмпирически легко обучить политику с высоким вознаграждением, а скорее такой, которая хорошо коррелирует с последующими показателями оценки. Обычная практика в RLHF, особенно с более крупными моделями, где градиенты менее стабильны, состоит в том, чтобы тратить дополнительные вычисления на поиск «стабильных» обучающих прогонов с увеличивающимся вознаграждением, что увеличивает вероятность несоответствия.
Обучение модели вознаграждения ↔ инструменты оценки Хотя для изучения современных моделей вознаграждения существует относительно мало работы и ресурсов, соответствие сигнала вознаграждения, который они предоставляют, предполагаемому варианту использования окончательной политики (через метрики оценки) имеет решающее значение для решения проблемы несоответствия целей. Модели вознаграждения обучаются на агрегированных наборах данных, чтобы максимизировать согласованность модели с заданным набором данных, которая на практике часто достигает максимальной точности только на 60-75% (Bai et al., 2022; Ouyang et al., 2022). Учитывая сложную задачу, связанную с моделированием вознаграждения, маловероятно, что модели сходятся со 100% точностью, но изучение источников этой разницы в производительности может указать на источники несоответствия. Необходимы новые инструменты для оценки моделей вознаграждения, которые лучше соответствуют их концептуальным основам в качестве представления человеческих ценностей для решения проблемы согласования (Leike et al., 2018) и для практической реализации в качестве целей для оптимизации Ламберт, Гилберт и Зик (Leike et al., 2018) 2023).
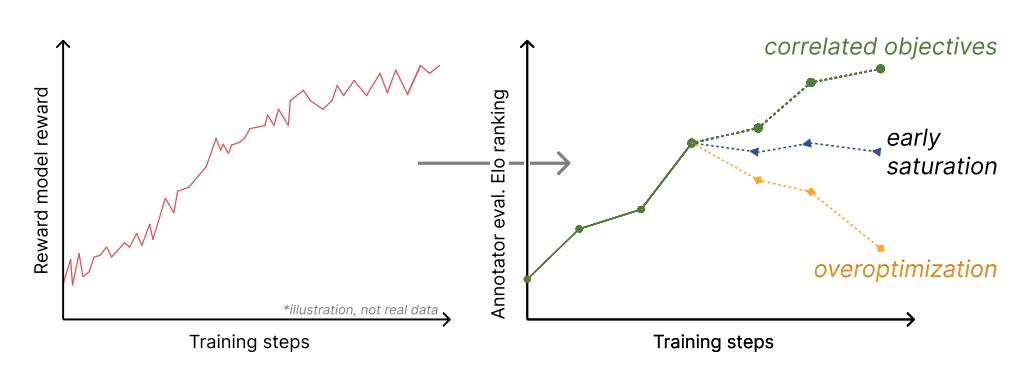
Обучение модели политики ↔ инструменты оценки Третье звено в наименьшей степени способствует возникновению несоответствий, но является самой простой осью для визуализации потенциальных признаков объективного несоответствия. Непосредственное сопоставление обучения RL с любыми дополнительными показателями оценки является технически сложной задачей. В MBRL такое решение могло бы быть с использованием дифференцируемого симулятора (R. Wei et al., 2023), но из-за сложности RLHF такие решения менее достижимы. Изучение любых типов регуляризации или калибровки обучения по отношению к окончательным оценкам является жизнеспособным в качестве направления исследований, но эта область исследования лучше всего подходит для визуализации признаков объективного несоответствия, как показано на рис. 3.
4.2 Расследования и решения
Уже проводятся исследования многих потенциальных причин несоответствия в RLHF, однако дальнейшая работа может быть вдохновлена решениями из более широкой литературы по RL. Многие решения проблемы несоответствия целей в MBRL не применимы напрямую, поскольку в MBRL они получают истинное вознаграждение от окружающей среды, и по этой причине необходимы исследования, чтобы понять результаты моделей вознаграждения. Ниже следует серия исследований, которые необходимо расширить, чтобы уменьшить объективное несоответствие:
• Оценка модели вознаграждения Существует множество осей, по которым ожидается поведение модели вознаграждения, чтобы она была разумным приближением к функции вознаграждения, но они обычно не изучаются. Модели вознаграждения необходимо оценивать на предмет согласованности, устойчивости к состязательным атакам, калибровки в разных дистрибутивах и т. д., как обсуждалось в Ламберте, Гилберте и Зике (2023). Понимание эффективности моделей вознаграждения является основой решения проблемы несоответствия. Оценка моделей вознаграждения будет косвенным, но полезным способом измерения различных наборов данных о предпочтениях, используемых для открытых моделей RLHF.
• Методы обучения модели вознаграждения Чтобы устранить ограничения моделей вознаграждения в более эффективных методах оценки, будет разработано множество новых методов обучения. Ранние исследования уже показали, что ансамбли моделей вознаграждения могут помочь смягчить чрезмерную оптимизацию (Coste et al., 2023). Необходимы дальнейшие исследования для интеграции методов, которые улучшают производительность алгоритмов RL на основе моделей, таких как вероятностные функции потерь для динамических моделей и планирования (Чуа, Каландра, Макаллистер и Левин, 2018), калиброванные оценки вероятности (Малик и др.) ., 2019) при обучении модели вознаграждения в качестве классификатора и других решений (R. Wei et al., 2023). Кроме того, следует изучить связи между моделями вознаграждения обратного обучения с подкреплением (IRL) (Ng, Russell и др., 2000), подполем, которому поручено изучить функцию вознаграждения на основе поведения агента, и моделями RLHF. Ранние исследования также показывают, что переформатирование обучения модели вознаграждения для лучшего соответствия предпочтениям учебной литературы может повысить производительность (Knox et al., 2023).
• Наборы данных для обучения модели вознаграждения Высококачественные наборы данных являются узким местом, замедляющим прогресс в открытых исследованиях RLHF, учитывая большие затраты, необходимые для их приобретения. Доступно несколько наборов данных, но их способность соответствовать производительности лучших моделей не доказана. Набор данных о предпочтениях Stack Exchange (Lambert, Tunstall, Rajani и Thrush, 2023), набор данных Стэнфордских предпочтений по контенту Reddit (Ethayarajh, Choi и Swayamdipta, 2022), синтетические данные о предпочтениях UltraFeedback (Cui et al., 2023), Просмотр Интернета по WebGPT (Накано и др., 2021), обучение обобщению (Stiennon et al., 2020) и набор данных Anthropic HHH (Askell et al., 2021) служат прочной основой для исследований, но исследования необходимы.< /п>
• Методы выборки на основе значений. Во время вывода можно затрачивать больше вычислений, чтобы повысить производительность моделей RLHF за счет использования значений, возвращаемых моделью вознаграждения (Deng & Raffel, 2023). Фэн и др. (2023) исследует это с помощью генерации поиска по дереву Монте-Карло, однако в литературе по планированию можно изучить множество других методов.
• Оценка НЛП, ориентированная на человека. Самый популярный метод оценки для моделей RLHF, настроенных в чате, - это процент предпочтения по сравнению с другими ведущими моделями в наборах подсказок для оценки (как это сделано в открытых моделях RLHF, включая Llama 2 (Touvron et al. , 2023) и Дромадер-2 (Сан и др., 2023)). Этот механизм оценки, хотя и хорошо мотивирован в популярных случаях использования моделей, страдает от предвзятости и проблем с воспроизводимостью. Подсказки можно легко выбрать для поддержки модели, разработанной авторами, и зачастую подсказки не публикуются и не объединяются в будущие тесты. Расширение воспроизводимости и последовательности этих практик будет иметь важное значение для создания надежных практик для RLHF.
• Оптимизаторы RL для языка.e Как обсуждалось в разд. 2.1, для RLHF чаще всего используются оптимизаторы из предыдущей литературы по RL. Теперь появилась возможность для расширения алгоритмов RL в нишу RLHF, где условия узкоспециализированы за счет расширяющегося пространства действий и бандитской формулировки. Новые алгоритмы являются шагом в правильном направлении, например, T. Wu et al. (2023), модифицируя алгоритм PPO для парных предпочтений, или Baheti et al. (2023) предлагают автономный алгоритм RL для действий полного завершения.
• Другие решения Будут существовать и другие творческие решения несоответствия, такие как работа по интеграции политики LLM, модели вознаграждения и функции перехода в единую модель (Сюй, Донг, Арумугам и Ван Рой, 2023). Подобные методы необходимо оценивать во многих масштабах, чтобы подтвердить, что они по-прежнему численно стабильны с более крупными современными моделями, в которых существуют мощные эмерджентные модели поведения.
4.3 Несовпадение прогноза следующего токена
Исходный объект обучения, используемый в популярных архитектурах языковых моделей, авторегрессионное предсказание следующего токена, также страдает от проблемы объективного несоответствия, поскольку почти все методы оценки LLM оценивают весь результат, а не отдельные токены. Хотя это правда, сигнал развития, который дает потеря прогнозирования следующего токена, более ортогонален целям RLHF. В RLHF и большинстве связанных с ним работ по RL сигнал вознаграждения интерпретируется как прямой показатель эффективности. Это предположение создает гораздо более непреднамеренно тонкую структуру исследования, требующую специального изучения его воздействия.
В MBRL изучение динамической модели также часто осуществляется посредством одношаговых переходов, при этом недавние работы посвящены изучению моделей авторегрессии (Janner, Li, & Levine, 2021; Lambert, Wilcox, Zhang, Pister, & Calandra, 2021). , где совокупная ошибка нескольких одношаговых прогнозов хорошо известна как проблема, тесно связанная с объективным несоответствием (Ламберт, Пистер и Каландра, 2022). В случае, когда несоответствие становится фундаментальной проблемой LLM, можно изучить аналогичные решения.
:::информация Этот документ доступен на arxiv по лицензии CC 4.0.
:::