Эта статья не связана с разработкой продукции, но касается программирования. Я расскажу о динамическом программировании (ДП) и о том, как эффективно использовать предыдущий опыт вычислений. Надеюсь, вам будет интересно.
Введение в динамическое программирование
Термин динамическое программирование впервые употребил известным американским математиком, одним из ведущих специалистов в области компьютерных технологий. , Ричард Беллман, еще в 1950-х годах. Динамическое программирование (ДП) – это метод решения сложных задач путем разбиения их на более мелкие подзадачи.

Тип проблем, которые может решить DP, должен соответствовать двум критериям:
<сильный>1. Оптимальная основа. Динамическое программирование означает, что решение более мелких подзадач можно использовать для решения первоначальной. Оптимальная подструктура — основная характеристика парадигмы «Разделяй и властвуй».
Классическим примером реализации является алгоритм сортировки слиянием, в котором мы рекурсивно разбиваем задачу на простейшие подзадачи (массивы размера 1), после чего производим вычисления на основе каждой из них. Результаты используются для решения следующего уровня (более крупных подзадач) до тех пор, пока не будет достигнут начальный уровень.
<сильный>2. Перекрывающиеся подзадачи. В информатике говорят, что проблема имеет перекрывающиеся подзадачи, если проблему можно разбить на подзадачи, которые используются повторно несколько раз. Другими словами, запуск одного и того же кода с теми же входными данными и теми же результатами. Классический пример этой задачи — вычисление N-го элемента последовательности Фибоначчи, который мы рассмотрим ниже.
Можно сказать, что ДП — это частный случай использования парадигмы «разделяй и властвуй» или ее более сложная версия. Паттерн хорошо подходит для решения задач комбинаторики, где рассчитывается большое количество различных комбинаций, но N-количество элементов зачастую монотонно и одинаково.
В задачах оптимальной подструктуры и перекрывающихся подзадачах мы имеем многочисленные повторяющиеся вычисления и операции, если применить метод грубой силы. DP помогает нам оптимизировать решение и избежать удвоения вычислений, используя два основных подхода: мемоизацию и табуляцию:
<сильный>1. Мемоизация (нисходящий подход) реализуется посредством рекурсии. Задача разбивается на более мелкие подзадачи, их результаты сохраняются в памяти и объединяются для решения исходной задачи путем многократного использования.
* Минусы: этот подход использует стековую память посредством рекурсивных вызовов методов. * Плюсы: Гибкость в решении задач DP.
<сильный>2. Табуляция (подход «снизу вверх») реализуется итеративным методом. Подзадачи от самой маленькой до начальной вычисляются последовательно, итеративно.
* Минусы: ограниченный спектр применения. Этот подход требует первоначального понимания всей последовательности подзадач. Но в некоторых задачах это неосуществимо. * Плюсы: эффективное использование памяти, поскольку все выполняется в рамках одной функции.
Теория может показаться утомительной и непонятной — давайте рассмотрим несколько примеров.
Задача: последовательность Фибоначчи
Классическим примером DP является вычисление N-го элемента последовательности Фибоначчи, где каждый элемент представляет собой сумму двух предыдущих, а первый и второй элементы равны 0 и 1.
По гипотезе мы изначально ориентируемся на природу оптимальной подструктуры, так как для вычисления одного значения нам необходимо найти предыдущее. Чтобы вычислить предыдущее значение, нам нужно найти то, что было до этого, и так далее. Характер перекрывающихся подзадач показан на диаграмме ниже.
Для этой задачи мы рассмотрим три случая:
- Простой подход: какие минусы?
- Оптимизированное решение с использованием мемоизации.
- Оптимизированное решение с использованием таблиц
- Каждое дерево начинается с верхнего узла (вершины дерева). Затем дерево расширяется в глубину.
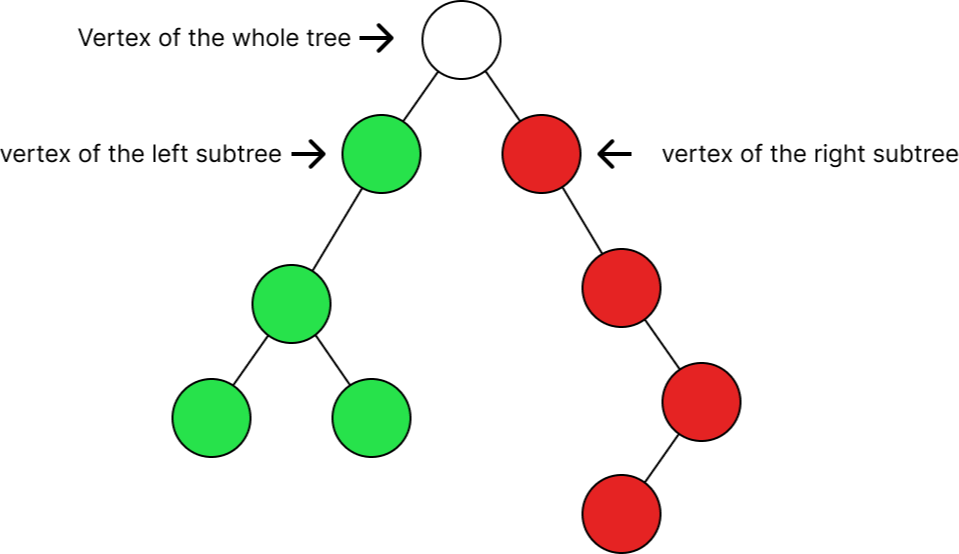
- Каждый узел является началом нового дочернего дерева (поддерева), как показано на экране. Левое поддерево окрашено в зеленый цвет, а правое — красный. У каждого своя вершина.
Простой подход/грубый подход
Первое, о чем вы можете подумать, — это ввести рекурсию, суммировать два предыдущих элемента и выдать их результат.
/**
* Straightforward(Brute force) approach
*/
fun fibBruteForce(n: Int): Int {
return when (n) {
1 -> 0
2 -> 1
else -> fibBruteForce(n - 1) + fibBruteForce(n - 2)
}
}
На экране ниже вы можете увидеть стек вызовов функций для вычисления пятого элемента последовательности.
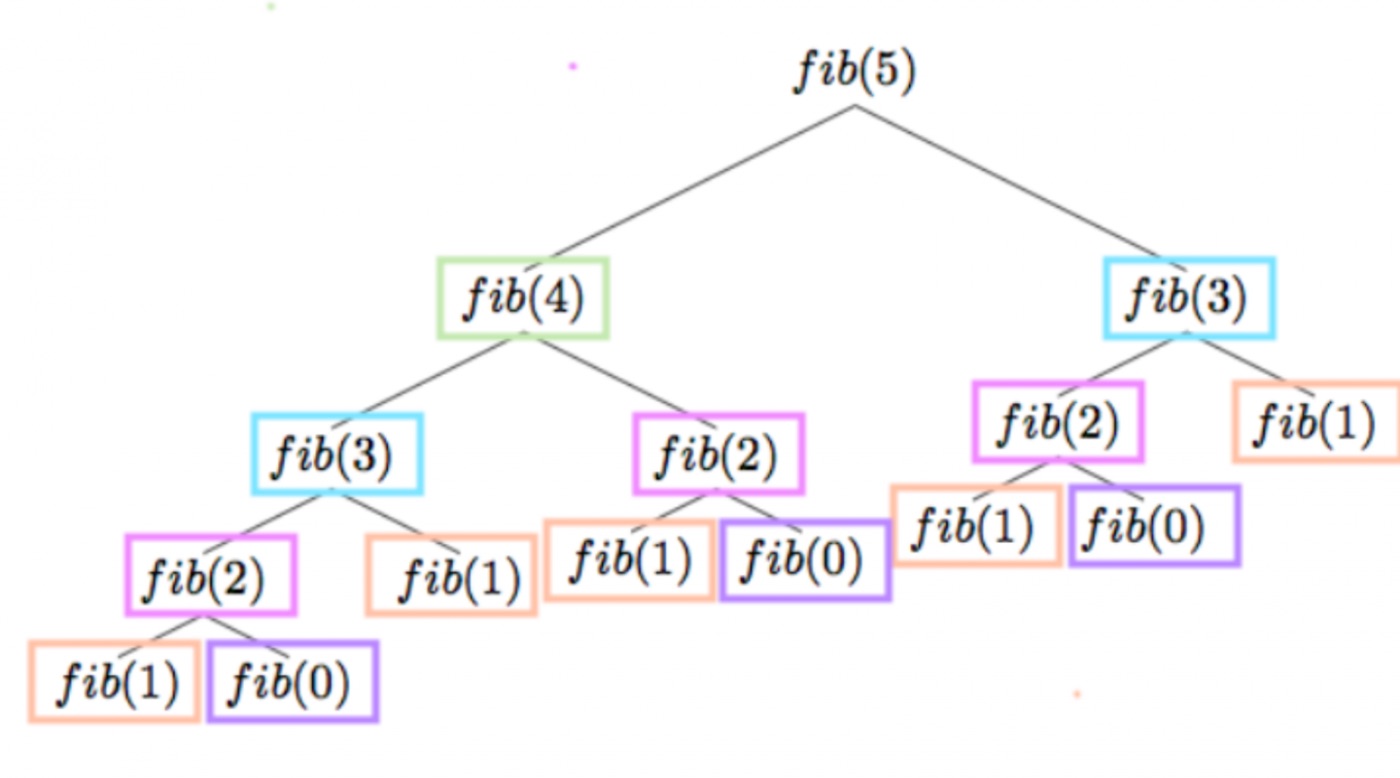
Обратите внимание, что функция fib(1) вызывается пять раз, а fib(2) три раза. Функции с одной сигнатурой, с одинаковыми параметрами запускаются неоднократно и делают одно и то же. При увеличении числа N дерево увеличивается не линейно, а экспоненциально, что приводит к колоссальному дублированию вычислений.
==Математический анализ:==
==Временная сложность:== O(2n),
==Пространственная сложность:== O(n) -> пропорциональна максимальной глубине рекурсивного дерева, поскольку это максимальное количество элементов, которые могут присутствовать в стеке неявных вызовов функций.
==Результат:== Такой подход крайне неэффективен. Например, для вычисления 30-го элемента необходимо 1 073 741 824 операции.
Мемоизация (нисходящий подход)
При таком подходе реализация не сильно отличается от предыдущего решения «грубой силы», за исключением распределения памяти. Пусть это будет переменная memo, в которую мы собираем результаты вычислений любой завершенной функции fib() в нашем стеке.
==Следует отметить, что было бы достаточно иметь массив целых чисел и обращаться к нему по индексу, но для концептуальной ясности была создана хэш-карта.==
/**
* Memoization(Top-down) approach
*/
val memo = HashMap<Int, Int>().apply {
this[1] = 0
this[2] = 1
}
fun fibMemo(n: Int): Int {
if (!memo.containsKey(n)) {
val result = fibMemo(n - 1) + fibMemo(n - 2)
memo[n] = result
}
return memo[n]!!
}
Давайте снова сосредоточимся на стеке вызовов функций:
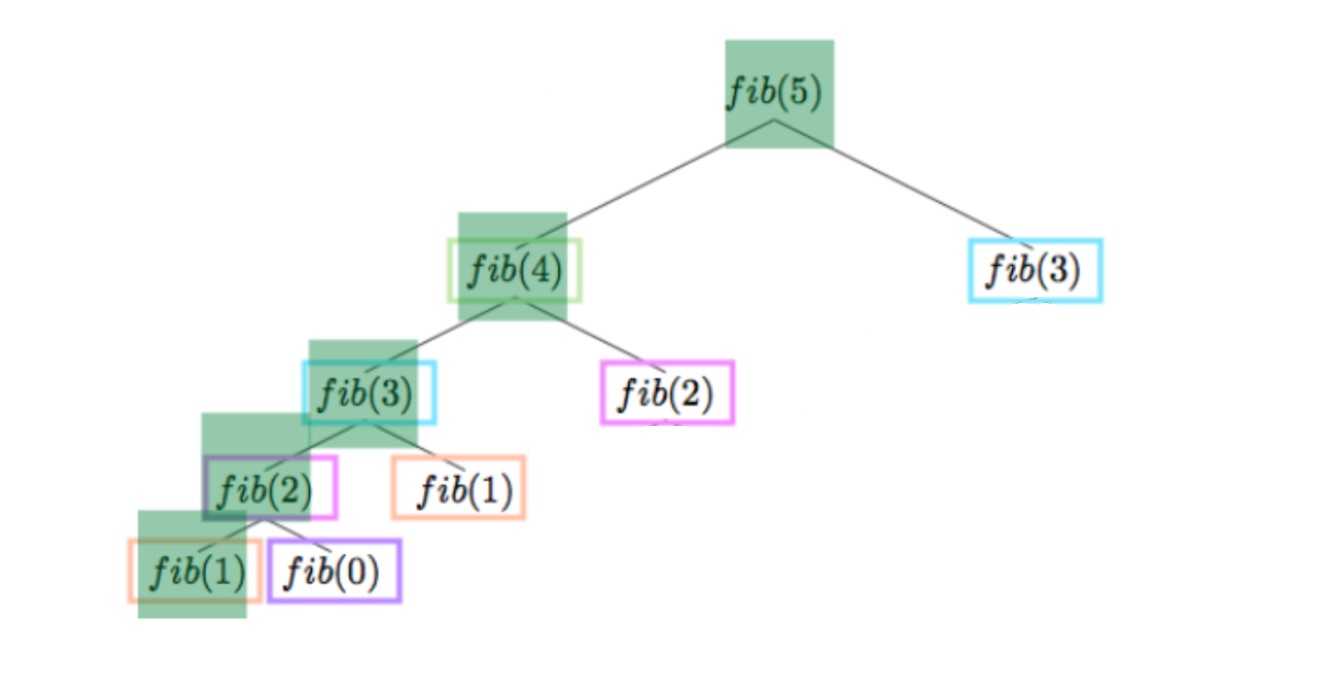
* Первой завершенной функцией, которая записывает результат в заметку, является выделенный fib(2). Он возвращает управление выделенному fib(3).
* Выделенный fib(3) находит свое значение после суммирования результатов вызовов fib(2) и fib(1), вводит свое решение в заметке и возвращает управление fib(4).
* Мы достигли стадии повторного использования предыдущего опыта — когда управление возвращается в fib(4), вызов fib(2) ожидает своей очереди в нем. fib(2), в свою очередь, вместо вызова (fib(1) + fib(0)) использует все готовое решение из заметки и сразу же возвращает его.
* fib(4) вычисляется и возвращает управление fib(5), которому достаточно запустить fib(3). В последней аналогии fib(3) немедленно возвращает значение из заметки без вычислений.
Мы можем наблюдать сокращение количества вызовов функций и вычислений. Кроме того, когда N увеличивается, сокращений будет экспоненциально меньше.
==Математический анализ:==
==Временная сложность: O(n)==
==Пространственная сложность: O(n)==
==Результат:== Существует явная разница в асимптотической сложности. Этот подход свел его к линейности во времени по сравнению с примитивным решением и не увеличил объем памяти.
Табулирование (подход «снизу вверх»)
Как упоминалось выше, этот подход предполагает итеративные вычисления от меньшей к большей подзадаче. В случае Фибоначчи наименьшими «подзадачами» являются первый и второй элементы последовательности, 0 и 1 соответственно.
Мы прекрасно знаем, как элементы соотносятся друг с другом, что выражается формулой: fib(n) = fib(n-1) + fib(n-2). Поскольку мы знаем предыдущие элементы, мы можем легко разработать следующий, следующий за ним и так далее.
Суммируя известные нам значения, мы можем найти следующий элемент. Эту операцию мы реализуем циклически, пока не найдем нужное значение.
/**
* Tabulation(Bottom-up) approach
fun fibTab(n: Int): Int {
var element = 0
var nextElement = 1
for (i in 2 until n) {
val newNext = element + nextElement
element = nextElement
nextElement = newNext
}
return nextElement
}
==Математический анализ:==
==Временная сложность: O(n)==
==Пространственная сложность: O(1)==
==Результат:== Этот подход так же эффективен, как и мемоизация, с точки зрения скорости, но требует постоянного объема памяти.
Проблема: уникальные двоичные деревья
Давайте рассмотрим более сложную задачу: нам нужно найти количество всех структурно уникальных бинарных деревьев, которые может быть создан из N узлов.
A ==двоичное дерево== — это иерархическая структура данных, в которой каждый узел имеет не более два потомка. Как правило, первый узел называется родительским и имеет двух дочерних узлов — левый дочерний и правый дочерний.
Предположим, что нам нужно найти решение для N = 3. Для трех узлов имеется 5 структурно уникальных деревьев. Мы можем посчитать их в уме, но если N увеличить, вариации значительно возрастут, и визуализировать их в голове будет невозможно.
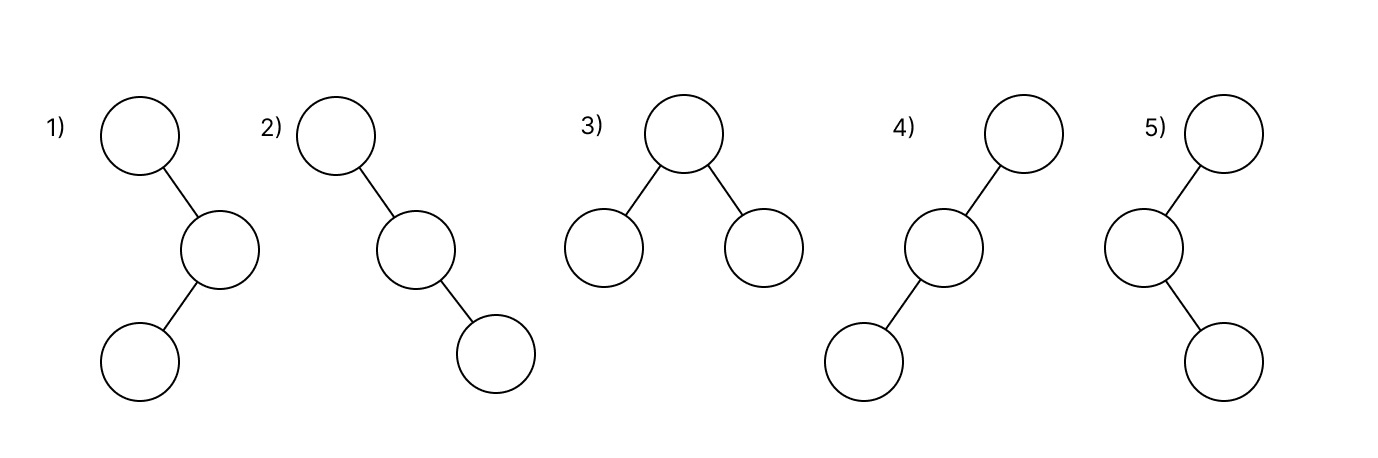
Эту задачу можно отнести к комбинаторике. Давайте разберемся, какие комбинации могут образовываться и как найти закономерность их образования.
Давайте рассмотрим пример задачи, где N = 6 на концептуальном уровне. Мы вызовем нашу функцию расчета == numOfUniqueTrees(n: Int)==.
В нашем примере задано 6 узлов, один из которых по указанному ранее принципу образует вершину дерева, а остальные 5 — остаток.
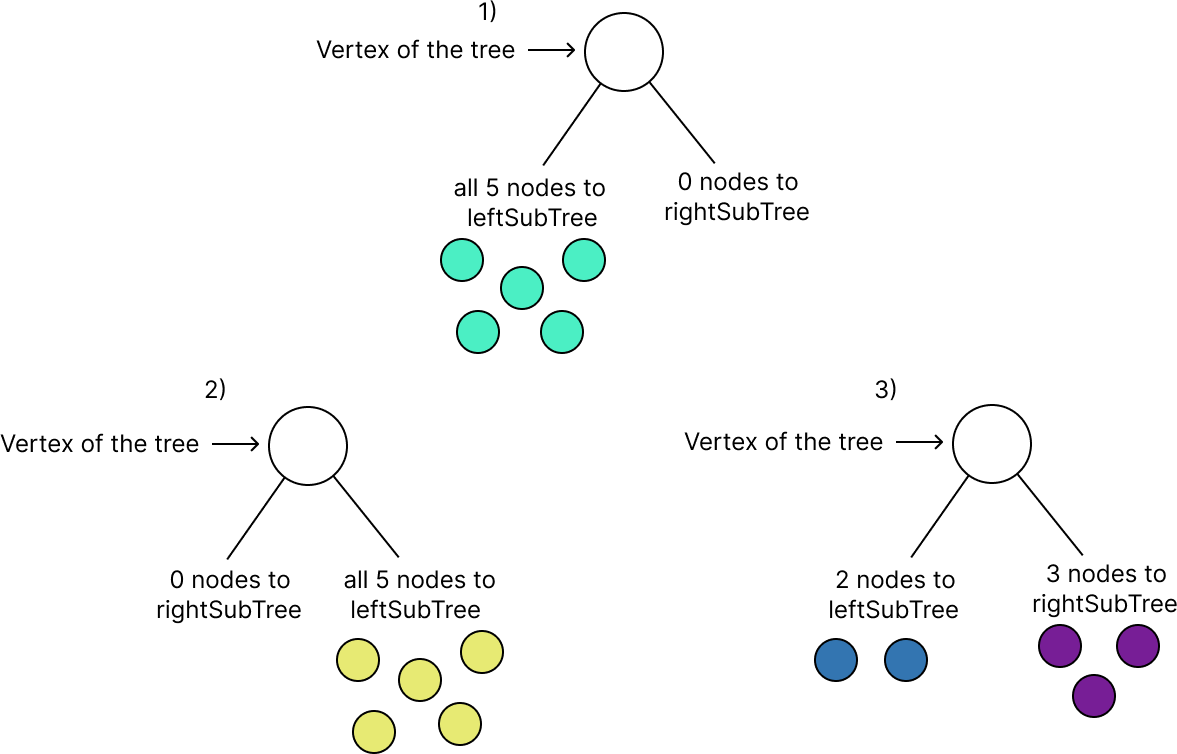
С этого момента мы взаимодействуем с остальными узлами. Это можно сделать разными способами. Например, используя все пять узлов для формирования левого поддерева или отправив все пять в правое поддерево. Или разделив узлы на два — 2 слева и 3 справа (см. скрин ниже), мы получим ограниченное количество таких вариантов.
Чтобы добиться результата numOfUniqueTrees(6), нам необходимо рассмотреть все варианты распределения наших узлов. Они показаны в таблице:
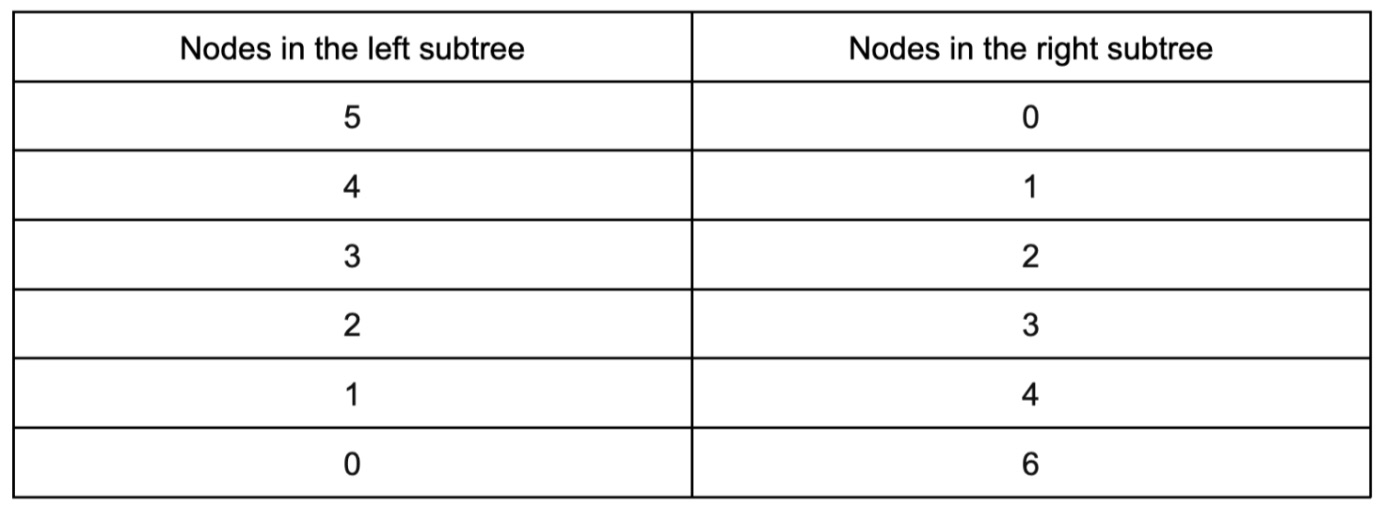
В таблице показано 6 различных распределений узлов. Если мы найдем, сколько уникальных деревьев можно создать для каждого распределения, и просуммируем их, мы получим окончательный результат.
==Как узнать количество уникальных деревьев для раздачи?==
==У нас есть два параметра: левые узлы и правые узлы (левый и правый столбец в таблице).==
==Результат будет равен:== numOfUniqueTrees(leftNodes) * numOfUniqueTrees(rightNodes).
== Почему? Слева у нас будет X уникальных деревьев, и для каждого мы сможем разместить Y уникальных вариаций деревьев справа. Мы умножаем их, чтобы получить результат.==
Итак, давайте выясним варианты для первого распределения (5 слева, 0 справа)
numOfUniqueTrees(5) * numOfUniqueTrees(0), так как справа у нас нет узлов. Результатом будет numOfUniqueTrees(5) — количество уникальных поддеревьев слева с константой справа.
Вычисление numOfUniqueTrees(5).
Теперь у нас есть наименьшая подзадача. Мы будем действовать с ним так же, как и с более крупным. На этом этапе характеристика задач ДП ясна — оптимальная подструктура, рекурсивное поведение.
Один узел (зеленый узел) отправляется в вершину. Остальные (четыре) узла распределяем аналогично предыдущему опыту (4:0), (3:1), (2:2), (1:3), (0:4).
Рассчитаем первое распределение (4:0). Он равен numOfUniqueTrees(4) * numOfUniqueTrees(0) ->gt; numOfUniqueTrees(4) по предыдущей аналогии.
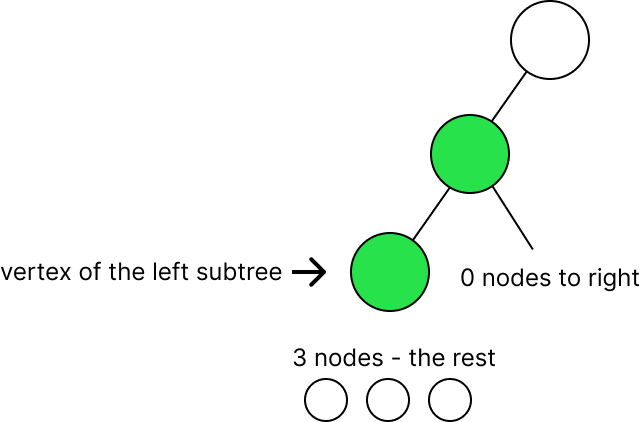
Вычисление numOfUniqueTrees(4). Если мы выделим узел для вершины, у нас останется 3.
Распределения (3:0), (2:1), (1:2), (0:3).
Для 2 узлов существует только два уникальных бинарных дерева, для 1 — одно. Ранее мы уже упоминали, что существует 5 вариантов уникальных бинарных деревьев для трех узлов.
В результате — распределения(3:0), (0:3) равны 5, (2:1), (1:2) — 2. Если просуммировать 5 + 2 + 2 + 5, то получим 14 . numOfUniqueTrees(4) = 14.
Занесем результат расчета в переменную memo по опыту мемоизации. Всякий раз, когда нам понадобится найти варианты для четырех узлов, мы не будем их рассчитывать заново, а повторно воспользуемся предыдущим опытом.
Вернемся к расчету (5:0), который равен сумме распределений (4:0), (3:1), (2:2), (1:3), (0:4). Мы знаем, что (4:0) = 14. Обратимся к памятке, (3:1) = 5, (2:2) = 4 (2 варианта слева * 2 справа), (1:3) = 5, (0:4) = 14. Если суммировать, получим 42, numOfUniqueTrees(5) = 42.
Вернемся к вычислению numOfUniqueTrees(6), которое равно сумме распределений.
(5:0) = 42, (4:1) = 14, (3:2) =10 (5 слева * 2 справа), (2:3) = 10, (1:4) = 14, (0: 5) = 42. Если суммировать, получим 132, numOfUniqueTrees(5) = 132.
Задача решена!
Результат: обратите внимание на перекрывающиеся подзадачи в решении, где N = 6. В простом решении numOfUniqueTrees(3) будет вызываться 18 раз (экран ниже). С увеличением N количество повторений одних и тех же вычислений будет намного больше.

Подчеркиваю, что количество уникальных деревьев для (5 слева, 0 справа) и (0 слева, 5 справа) будет одинаковым. Только в одном случае они будут слева, а в другом справа. Это также работает для (4 слева, 1 справа) и (1 слева, 4 справа).
Мемоизация как подход динамического программирования позволила нам оптимизировать решение такой сложной задачи.
Реализация
class Solution {
fun calculateTees(n: Int, memo:Array<Int?>): Int {
var treesNum = 0
if(n < 1) return 0
if(n == 2) return 2
if(n == 1) return 1
if(memo[n]!=null)
return memo[n]!!
for (i in 1..n){
val leftSubTrees = calculateTees( i - 1, memo)
val rightSubTrees = calculateTees(n - i, memo)
treesNum += if(leftSubTrees>0 && rightSubTrees>0){
leftSubTrees*rightSubTrees
} else
leftSubTrees+leftSubTrees
}
memo[n] = treesNum
return treesNum
}
}
Заключение
В некоторых случаях решение задач средствами динамического программирования позволяет сэкономить огромное количество времени и заставить алгоритм работать с максимальной эффективностью.
Спасибо, что дочитали эту статью до конца. Буду рад ответить на ваши вопросы.
<блок-цитата>Размещено Аятом Рахишевым