В этой статье я собираюсь пролить свет на один важный аспект наблюдаемости — трассировку.
Если метрики и журналы — довольно понятные термины, мы рассмотрели их в предыдущие статьи, трассировка — это новый и современный термин, который, вероятно, немного сложнее понять.
На самом деле понять этот термин нетрудно, я собираюсь показать вам это. С другой стороны, сложно сделать реализацию или внедрить ее в уже работающую систему (конечно, если ваша система сложнее, чем две простые виртуальные машины).
Стрейс
strace — это инструмент для отслеживания того, какие вызовы используются процессом, он показывает время, затраченное на каждый системный вызов, аргументы и возвращаемые значения. Многие системные администраторы и разработчики знакомы с этим инструментом, потому что он очень полезен в повседневной жизни.
По сравнению с strace трассировка по наблюдаемости аналогична. Но это немного сложнее, strace используется для наблюдения за приложением (внутри), а трассировка используется в распределенных системах. В этом разница.
Трассировки обычно выглядят как журналы, эти структуры данных содержат время, затраченное на каждую единицу, уникальный идентификатор трассы и т. д.
Простые понятия о трассировке
Простой пример
Давайте рассмотрим простой пример. Мы можем использовать систему клиент-сервер. Один сервер отправляет запросы (клиент), а другой отвечает чем-то по сети. Неважно, какой протокол используется для связи между клиентом и сервером. Это может быть двоичный файл или протокол HTTP и т. д.
Это показано на рис. 1 ниже.

n Вы можете построить такую систему, запустив на стороне сервера следующее:
$ nc -l 10000
и на клиенте:
$ nc <server> 10000
n Что здесь происходит?
Клиент отправляет запросы по сети, сервер получает, обрабатывает (фактически вначале разбирает запрос), затем готовит ответ и отправляет его. Это очень понятный процесс.
Но обработка запросов на стороне сервера требует времени, если количество подключенных клиентов значительно увеличивается, время на обработку тоже увеличивается.
В этом случае клиент может ничего не получить и закрыть соединение по тайм-ауту. Иногда случаются такие ситуации. Это типичная клиент-серверная архитектура любого современного приложения.
Как профессионалы DevOps, мы должны отслеживать такое поведение и принимать превентивные/корректирующие меры. Мы должны понимать архитектуру и то, где может возникнуть узкое место.
Давайте посмотрим на рисунок 2 ниже.
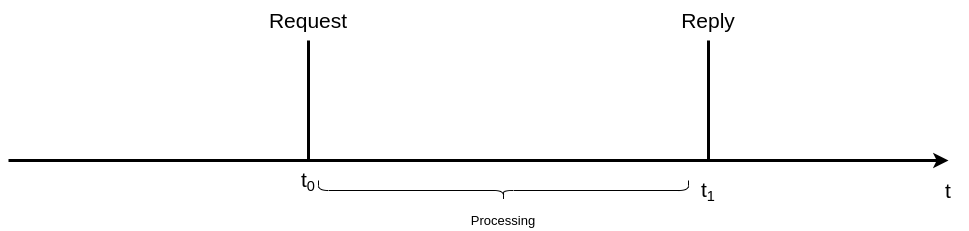
n В момент t0 сервер получает запрос. И в момент t1 клиенту отправляется ответ. Мы не учитываем задержки сети и т. д.
n t1-t0 - нормальное время, затраченное на обработку. На рисунке 1 мы видим только одну простую схему. Конечно, в современной распределенной и микросервисной архитектуре гораздо больше элементов. Это относится ко всем сложным системам, а не только к микросервисным приложениям.
Не очень простой пример
Итак, мы рассмотрели довольно простой пример, где у нас был только один сервер и один клиент. Современные системы содержат различные компоненты. Просто для пояснения возьмем простое веб-приложение. Он содержит внешний интерфейс (веб-сервер, который обслуживает статические файлы и передает файлы интерпретатору, такому как python или php). Также он содержит бэкенд и как минимум базу данных, скажем, PostgreSQL.
Эта система представлена на рис. 3 ниже.

Что у нас здесь?
Мы видим три компонента, и каждый из них приводит к задержке при обработке запроса клиента.
Я предлагаю перерисовать картинку, чтобы лучше понять запрос.
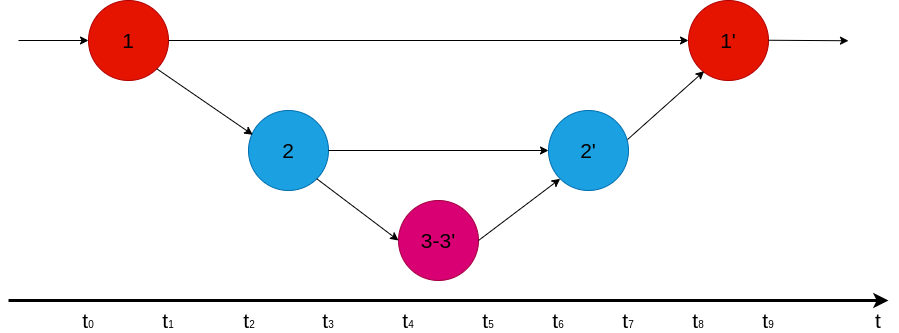
п
На данный момент:
t0 — фронтенд получает запрос клиента
t1 — интерфейс отправляет запрос серверу
t2 — серверная часть получает запрос
t3 — серверная часть отправляет запрос (запрос SQL) в базу данных
t4 — база данных получает запрос
t5 — база данных возвращает ответ серверной части
t6 — серверная часть получает ответ от базы данных
t7 — серверная часть возвращает ответ интерфейсу
t8 — внешний интерфейс получает ответ от внутреннего интерфейса
t9 — внешний интерфейс возвращает ответ клиенту
Другими словами, интервал
t0 - t1 - время обработки клиентского запроса во внешнем интерфейсе
t2 - t3 - время обработки клиентского запроса в бэкенде
t4 - t5 - время обработки запроса в системе управления базой данных
t6 - t7 - время обработки запроса к базе данных в бэкенде
t8 - t9 - время обработки ответа бэкенда во внешнем интерфейсе
или:
t2 - t7 -время, которое бэкенд тратит на обработку запроса фронтенда, включая запрос к СУБД, допустим 200 мс
t0 - t9 - общее время, которое система тратит на обработку запроса клиента, например, 500 мс
То есть запрос к базе данных занимает 300 мс.
Интерфейс может быть веб-сервером с любым интерпретатором, взаимодействующим через CGI или любой другой интерфейс, поэтому мы можем разбить интерфейс на две части. И все это можно применить к бэкенду. Насколько маленькой может быть деталь, зависит от ваших требований, универсального совета нет.
Те части системы, на которые ее можно разделить для измерения времени обработки, с точки зрения трассировки, называются пролетом. Span — это единица любой обработки данных. Набор отрезков является трассировкой. Представление трасс может быть описано как ориентированный ациклический граф (DAG) и может иметь разветвления.
Таким образом, на рис. 3 пролета. 4:
1-1’– корневой пролет2–2’— дочерний элемент диапазона1–1’3-3’— дочерний элемент диапазона2-2’, который указывает на работу внутри базы данных
Обзор решений с открытым исходным кодом для отслеживания
Если у вас нет нужных данных телеметрии, то есть если ваше приложение этого не выдает, ваши разработчики не знают, как это реализовать (я понимаю, это дополнительная нагрузка на разработчиков, им надо копаться во многих вещей, реализовывать собственный протокол и т. д.), существуют решения с открытым исходным кодом, которые можно встроить в ваш код, и ваш код будет генерировать необходимую информацию.
Существует два разных стандарта с открытым исходным кодом
- Opentelemetry (https://opentelemetry.io)
- Opentracing (https://opentracing.io/)
Недавно Opentracing считался заархивированным, поэтому у нас есть только один - OpenTelemetry (или сокращенно OTel).
Вот список популярных решений с открытым исходным кодом для отслеживания:
| Имя | Стандарт | Язык | Домашняя страница | |----|----|----|----| | Джагер | ОТел | Голанг | https://www.jaegertracing.io/ | | Зипкин | Открытая телеметрия | Ява | https://zipkin.io/ | | Сигноз | ОТел | Голанг | https://signoz.io/ | | Часовой | Собственная реализация | Питон | https://docs.sentry.io/product/sentry-basics/tracing | | Эластичный АРМ | ОТел | Ява | https://www.elastic.co/observability/application-performance-monitoring |
Если у вас есть исходники приложения, даже если вы не можете его переписать по какой-либо причине, или вы используете стороннее приложение, для которого у вас нет исходников (например, черный ящик), и вы хотите сделать систему наблюдаемой , оно должно быть инструментировано: то есть приложение должно предоставлять конкретную информацию.
Для сбора трассировки телеметрии существует два подхода:
- Вы используете автоматическое инструментирование, также известное как сервисная сетка. Этот подход применяется к вашему приложению, если у вас нет исходников, ваше приложение похоже на черный ящик, и вы не знаете внутреннюю реализацию. И если ваше приложение уже разработано. Для этого OTell предлагает агенты или специальные расширения (в зависимости от языка).
2. Вы изменяете свой код и добавляете определенные вызовы API OTel. Этот подход предполагает добавление функций в ваш код, и эти функции будут генерировать выходные данные трассировки.
Что еще нужно для создания системы отслеживания следов?
По крайней мере, вам нужно хранилище для телеметрической информации, которую вы получаете от приложений. И приложение для визуализации, которое покажет вам следы. Выше было показано, что существует множество готовых к использованию приложений с открытым исходным кодом, содержащих хранилище и приятный графический интерфейс пользователя. Конечно, с помощью OTel вы можете создать собственную систему или использовать уже имеющуюся. Но это не тривиальная задача.
Заключение
Поначалу, как только вы начинаете свою карьеру в сфере DevOps, у вас возникает множество вопросов, и иногда бывает сложно понять, как внедрить новые технологии в инфраструктуру и как ее улучшить. Информации слишком много, и легко запутаться.
В статье мы рассмотрели один из важных моментов — трассировку в наблюдаемости. Как было показано, трассировка — это подход к обеспечению видимости в вашей распределенной системе. В настоящее время многие организации имеют микросервисную архитектуру, а трассировка позволяет выявить узкие места производительности в распределенных системах и понять странное поведение. Это также полезно при устранении неполадок.
По крайней мере, трассировка облегчает вашу работу и дает больше гибкости, сокращая время на поиск проблем в больших системах. Это становится чрезвычайно важным в современных ИТ-инфраструктурах, в которых недостаточно иметь только мониторинг.
Надеюсь, что эта статья окажется полезной и поможет понять принципы трассировки.
Ведущий образ создан со стабильной диффузией. n
н
н