
Теоретическая эффективность памяти повышается с LORA для однократных и мульти-GPU настройки
18 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 фон
3 Экспериментальная настройка и 3,1 наборов данных для продолжения предварительной подготовки (CPT) и создания инструкций (IFT)
3.2 Измерение обучения с помощью кодирования и математических показателей (оценка целевой области)
3.3 Забыть метрики (оценка доменов источника)
4 Результаты
4.1 Lora Underperforms Полное создание в программировании и математических задачах
4.2 Лора забывает меньше, чем полное создание
4.3 Обмен на обучение
4.4 Свойства регуляризации Лоры
4.5 Полная производительность на коде и математике не изучает низкие возмущения
4.6 Практические выводы для оптимальной настройки LORA
5 Связанная работа
6 Обсуждение
7 Заключение и ссылки
Приложение
А. Экспериментальная установка
B. Поиски скорости обучения
C. Обучающие наборы данных
D. Теоретическая эффективность памяти с LORA для однократных и мульти-GPU настройки
D Теоретическая эффективность памяти повышается с LORA для однократных и мульти-GPU настройки
Современные системы для обучения нейронных сетей хранят и работают на следующих объектах (после конвенций в Rajbhandari et al. (2020)). Большинство требований к памяти связаны с состояниями модели, которые включают:
• Веса параметров
• градиенты
• Количество оптимизации более высокого порядка, такие как импульс оптимизатора и дисперсия в оптимизаторе ADAM и импульс в оптимизаторе льва
Остальные требования к памяти поступают изостаточные состояния:
• Активации (которые зависят от размера партии и максимальной длины последовательности образцов)
• Временные буферы для промежуточных величин в прямом и обратном проходе.
который потребует большей памяти при увеличении размера партии и максимальной длины последовательности.
Лора предлагает экономию памяти по отношению кСостояния модели.В следующих двух разделах описываются эти сбережения памяти в одном графическом процессоре и настройке мульти-GPU с примерами, которые свободно вдохновлены Rajbhandari et al. (2020).
Данные, хранящиеся в одиночной точности, включают:
• «Мастерная копия» весов настроенных параметров
• градиент
• Все состояния оптимизатора (как импульс, так и дисперсия для Адама и просто импульс для лев)
Для простоты мы не учитываем обучение смешанного назначения, которое включает в себя хранение критических данных при единственной точности (FP32; 4 байта на число) при выполнении некоторых вычислений с половиной точностью (FP16 или BFLOAT16; 2 байта на число).
D.1 Обучение на одном GPU
В единой настройке графического процессора разница в требованиях к памяти между LORA и Full Menetuning особенно радикальной при использовании оптимизатора ADAM (Hu et al., 2021; Rajbhandari et al., 2020).
Хранение основных весов в FP32 требует 4 байта на параметр, в то время как хранение градиента в FP32 требует 4 байта на настроенный параметр. Чтобы поддерживать состояние оптимизатора в FP32 для Adam, требуются 8 байтов на настроенный параметр; 4 байта для термина импульса и 4 байта для термина дисперсии. Пусть ψ - количество параметров модели. Следовательно, в настройке полного создания ADAM модели параметра ψ = 7B общие требования к памяти, по крайней мере, примерно 4 × ψ + 4 × ψ + 8 × ψ = 112 ГБ.
Оптимизатор львов использует только термин импульса в расчете градиента, а термин дисперсии в Адаме, следовательно, исчезает. В настройке полного создания льва модели параметра ψ = 7b, следовательно, общие требования к памяти составляют примерно 4 × ψ + 4 × ψ + 4 × ψ = 84 ГБ.
Лора, с другой стороны, не рассчитывает градиенты и не поддерживает состояния оптимизатора (импульс и термины дисперсии) для большинства параметров. Следовательно, объем памяти, используемой для этих терминов, резко уменьшается.
Настройка LORA с ADAM, которая только настраивает матрицы, которые составляют 1% от общего количества параметров (например, ψ = 7b базовая модель с 70 млн. Дополнительными параметрами, используемыми LORA), требуется примерно 4 × ψ (1 + 0,01) + 4 × ψ × 0,01 + 8 × ψ × 0,01 = 29,12 ГБ памяти. Теоретически это может быть уменьшено дальше до 2 × ψ + 16 × ψ × 0,01 = 15,12 ГБ, если веса не настраиваемых параметров хранятся в BFLOAT16. Мы используем это предположение для последующих примеров.
Обратите внимание, что эти числа не принимают во внимание размер партии или длину последовательности образца, которые влияют на требования к памяти активаций.
D.2 Обучение на множественном параллелизме
Прошлые подходы к обучению LLMS в нескольких графических процессорах включают параллелизм модели, где различные слои LLM хранятся на разных графических процессорах. Однако это требует высоких накладных расходов и имеет очень плохую пропускную способность (Rajbhandari et al., 2020). Полностью нарушенные данные параллелизма данных (FSDP) поступает параметры, градиент и состояния оптимизатора в графических процессорах. Это невероятно эффективное и на самом деле конкурентоспособно с экономией памяти, предлагаемой Лорой в определенных настройках.
FSDP -нарушение параметров и состояний оптимизатора по N -устройствам приводит к меньшему использованию памяти по сравнению с LORA. Лора, с другой стороны, обеспечивает тренировок по графическим процессорам с гораздо меньшим количеством памяти, а также обретает тренировку, не требуя столько графических процессоров, чтобы противостоять.
Например, в настройке полного создания ADAM A модели параметра ψ = 7B на 8 графических процессорах с FSDP общая потребность в памяти для каждого GPU примерно (4 × ψ + 4 × ψ + 8 × ψ)/8 = 14 ГБ. Это уменьшается до 3,5 ГБ для FSDP с 32 графическими процессорами (см. Таблицу S1).
LORA с установкой ADAM на 8 графических процессорах (где базовая модель ψ = 7B и есть 70 м дополнительных параметров LORA) требует примерно (2 × ψ + 16 × ψ × 0,01)/8 = 1,89 ГБ памяти на графический процессор. С 32 графическими процессорами это уменьшается до 0,4725 ГБ.
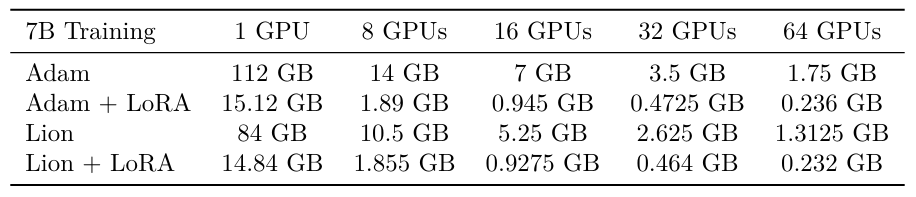
Стандартные графические процессоры на уровне отраслевого уровня имеют память на установке между 16 ГБ (например, V100) до 80 ГБ (например, A100 и H100). Как показывает таблица S1, требования к памяти на GPU для обучения модели параметра 7B резко уменьшаются по мере увеличения графических процессоров. Требования к памяти для обучения модели 7b с Adam + Lora на одном графическом процессоре составляют 15,12 ГБ, но то же самое требования к памяти на GPU для обучения модели 7B с ADAM, но без LORA на 8 графических процессоров составляет 14 ГБ. В этом сценарии 8 графических процессоров эффективность от Лоры исчезает.
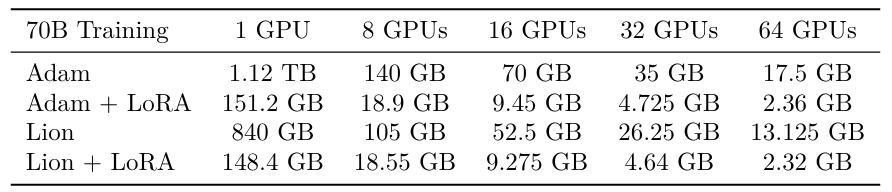
Таблица S2 применяет аналогичные расчеты к модели параметров 70B. Создание такой большой модели на 8 графических процессорах возможна только с использованием такой техники, как Лора; Там, где Адам требуется 140 ГБ на графический процессор, Адам+Лора требует 18,9 ГБ на графический процессор. Поэтому повышение эффективности LORA относительно FSDP зависит от размера модели и соображений доступности/затрат на GPU.
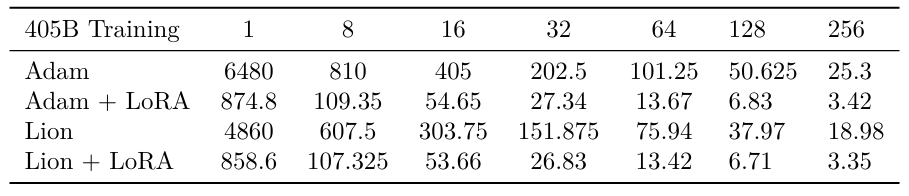
Мы проводим тот же анализ для модели параметров 405B, чтобы подчеркнуть, как Лора полезно, как шкалы размера модели (таблица S3).
Авторы:
(1) Дэн Бидерман, Колумбийский университет и Databricks Mosaic AI (db3236@columbia.edu);
(2) Хосе Гонсалес Ортис, DataBricks Mosaic AI (j.gonzalez@databricks.com);
(3) Джейкоб Портес, DataBricks Mosaic AI (jportes@databricks.com);
(4) Mansheej Paul, DataBricks Mosaic AI (mansheej.paul@databricks.com);
(5) Филип Грингард, Колумбийский университет (pg2118@columbia.edu);
(6) Коннор Дженнингс, DataBricks Mosaic AI (connor.jennings@databricks.com);
(7) Даниэль Кинг, DataBricks Mosaic AI (daniel.king@databricks.com);
(8) Сэм Хейвенс, DataBricks Mosaic AI (sam.havens@databricks.com);
(9) Vitaliy Chiley, DataBricks Mosaic AI (vitaliy.chiley@databricks.com);
(10) Джонатан Франкл, DataBricks Mosaic AI (jfrankle@databricks.com);
(11) Коди Блакни, DataBricks Mosaic AI (Cody.blakeney);
(12) Джон П. Каннингем, Колумбийский университет (jpc2181@columbia.edu).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)