

Теоретическая структура: запоминание трансформатора и динамика производительности
19 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 Связанная работа
3 модели и 3.1 ассоциативные воспоминания
3.2 трансформаторные блоки
4 Новая энергетическая функция
4.1 Слоистая структура
5 Потеря по перекрестной энтропии
6 Эмпирические результаты и 6.1 Эмпирическая оценка радиуса
6.2 Обучение GPT-2
6.3 Тренировка ванильных трансформаторов
7 Заключение и подтверждение
Приложение A. отложенные таблицы
Приложение B. Некоторые свойства энергетических функций
Приложение C. отложенные доказательства из раздела 5
Приложение D. Трансформатор Подробности: Использование GPT-2 в качестве примера
Ссылки
Абстрактный
Увеличение размера модели трансформатора не всегда приводит к повышению производительности. Это явление не может быть объяснено эмпирическими законами масштабирования. Кроме того, улучшенная способность обобщения происходит, когда модель запоминает обучающие образцы. Мы представляем теоретическую структуру, которая проливает свет на процесс запоминания и динамику производительности языковых моделей на основе трансформаторов. Мы моделируем поведение трансформаторов с ассоциативными воспоминаниями с использованием сети Hopfield, так что каждый блок трансформатора эффективно проводит приблизительный поиск в ближайшем соседстве. Основываясь на этом, мы разрабатываем энергетическую функцию, аналогичную функции в современной непрерывной сети Hopfield, которая обеспечивает проницательное объяснение механизма внимания. Используя метод минимизации мажоризации, мы строим глобальную энергетическую функцию, которая отражает слоистую архитектуру трансформатора. В определенных условиях мы показываем, что минимально достижимая потери перекрестной энтропии ограничена ниже ниже постоянными приблизительно равными 1. Мы подтверждаем наши теоретические результаты, проводя эксперименты с GPT-2 по различным размерам данных, а также обучают ванильные трансформаторы в наборе набора 2M токен.
1 Введение
Нейронные сети, основанные на трансформаторах, продемонстрировали мощные возможности в выполнении множества задач, таких как генерация текста, редактирование и отвлечение вопросов. Эти модели коренится в архитектуре трансформатора (Vaswani et al., 2017), в которой используются механизмы самоуважения для захвата контекста, в котором появляются слова, что приводит к превосходной способности справляться с зависимостью дальнего действия и повышению эффективности обучения. Во многих случаях модели с большим количеством параметров приводят к повышению производительности, измеренной с недоумением (Kaplan et al., 2020), а также к точности конечных задач (Khandelwal et al., 2019; Rae et al., 2021; Chowdhery et al., 2023). В результате в отрасли разрабатываются более крупные и более крупные модели. Недавние модели (Smith et al., 2022) могут достигать до 530 миллиардов параметров, обученных сотням миллиардов жетонов с более чем 10 тысяч графических процессоров.
Тем не менее, не всегда так, что более крупные модели приводят к лучшей производительности. Например, модель 2B Minicpm (Hu et al., 2024) демонстрирует сопоставимые возможности для более крупных языковых моделей, таких как Llama2-7B (Touvron et al., 2023), Misstral-7b (Jiang et al., 2023), Gemma-7b (Banks and Warkentin, 2024) и Llama-13b (Touv. Кроме того, по мере увеличения вычислительных ресурсов для обучения более крупных моделей размер доступных высококачественных данных может не идти в ногу. Было задокументировано, что способности обобщения ряда моделей увеличиваются с количеством параметров и уменьшаются, когда увеличивается количество обучающих образцов (Belkin et al., 2019; Nakkiran et al., 2021; D’Ascoli et al., 2020), что указывает на то, что обобщение происходит за пределы запоминания. Следовательно, крайне важно понять динамику сходимости потери обучения во время запоминания, как в отношении размера модели, так и набора данных под рукой. Был растущий интерес к эмпирическим законам масштабирования в рамках ограничений на размер набора данных обучающих данных (Muennigoff et al., 2024). Пусть n обозначает количество параметров модели и D обозначает размер набора данных. Обширные эксперименты привели к завершению следующих законов эмпирического масштабирования (Kaplan et al., 2020) с точки зрения производительности модели, измеренной с помощью потерь перекрестной энтропии Test Los Of Ot Out:
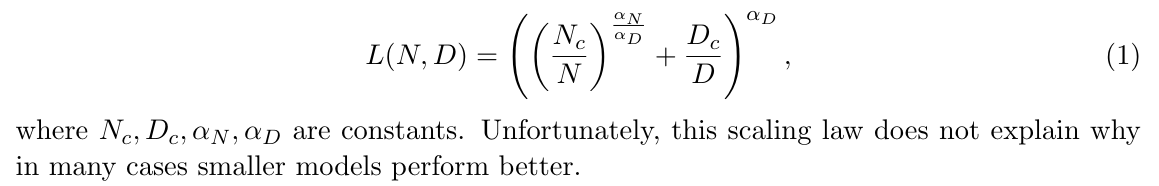
В этой статье мы сосредотачиваемся на теоретических аспектах зависимостей между достижимой производительностью, обозначенной потерей предварительного обучения, для моделей на основе трансформаторов, а также модели и размеров данных во время запоминания. Было отмечено, что семейство крупных языковых моделей имеет тенденцию полагаться на знания, запоминающиеся во время обучения (Hsia et al., 2024), и чем больше модели, тем больше они имеют тенденцию кодировать учебные данные и организовывать память в соответствии с сходством текстового контекста (Carlini et al., 2022; Tirumala et al., 2022). Поэтому мы моделируем поведение слоев трансформатора с ассоциативной памятью, которая связывает ввод с сохраненной шаблоном, а выводы направлены на получение связанных воспоминаний. Модель для ассоциативной памяти, известная как сеть Hopfield, была первоначально разработана для получения хранимых двоичных закономерностей, основанных на части контента (Amari, 1972; Hopfield, 1982). Недавно классическая сеть Hopfield была обобщена для данных с непрерывными значениями. Было показано, что обобщенная модель, современная непрерывная сеть хопфилда (MCHN), демонстрирует эквивалентность механизму внимания (Ramsauer et al., 2020). С помощью MCHN сеть может хранить хорошо разделенные точки данных с экспоненциальным размером в измерении встраивания. Тем не менее, MCHN объясняет только отдельный слой трансформатора и в значительной степени зависит от регуляризации.
Модели на основе трансформаторов состоят из стопки однородных слоев. Слои внимания и подача вклад способствуют большинству параметров, а также являются ключевыми компонентами механизма внимания. Было показано, что слои подачи могут быть интерпретированы как постоянные векторы памяти, и веса подслойки внимания и перемещения могут быть объединены в новый слой всеобщего привлечения без ущерба для производительности модели (Sukhbaatar et al., 2019). Это увеличение обеспечивает унифицированный взгляд, который интегрирует слои с обратной стороны в слои внимания, тем самым значительно облегчая наш анализ. Кроме того, многослойная структура трансформаторных сетей вызывает последовательную оптимизацию, напоминающую технику мажоризации-минимизации (MM) (Ortega and Rheinboldt, 1970; Sun et al., 2016), которая широко используется в разных доменах, таких как обработка сигналов и обучение машинного обучения. Используя структуру MM, мы строим глобальную энергетическую функцию, адаптированную для слоистой структуры сети трансформаторов.
Наша модель предоставляет теоретическую основу для анализа эффективности языковых моделей на основе трансформатора, когда они запоминают обучающие образцы. Модели крупных языков проявляются только для определенных нижестоящих задач после того, как потери тренировок достигают определенного порога (Du et al., 2024). На практике обучение крупных языковых моделей прекращается, когда плато кривых потерь. С одной стороны, убыток проверки предлагает ценную информацию о бюджетных соображениях; Было отмечено, что даже после тренировки до 2t токенов некоторые модели еще не имеют признаков насыщения (Touvron et al., 2023). С другой стороны, ранняя остановка может потенциально поставить под угрозу возможности обобщения модели (Murty et al., 2023). С другой стороны, реализация ранней остановки может потенциально поставить под угрозу возможности обобщения моделей (Murty et al., 2023). Мы проводим серию экспериментов, использующих GPT-2 в спектре размеров данных, одновременно обучающие модели ванильных трансформаторов на наборе данных, содержащий 2-метровые токены. Экспериментальные результаты подтверждают наши теоретические результаты. Мы считаем, что эта работа предлагает ценные теоретические взгляды на оптимальную потерю перекрестной энтропии, которая может информировать и улучшать принятие решений в отношении модельного обучения.
Эта статья есть
Авторы:
(1) Xueyan Niu, Theory Laboratory, Central Research Institute, 2012 Laboratories, Huawei Technologies Co., Ltd.;
(2) Бо Бай Байбо (8@huawei.com);
(3) Lei Deng (deng.lei2@huawei.com);
(4) Вэй Хан (harvey.hanwei@huawei.com).
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)