

The Times против Microsoft/OpenAI: несанкционированное воспроизведение Times работает при обучении модели GPT (10)
2 января 2024 г.:::совет Судебное заявление компании New York Times против корпорации Microsoft от 27 декабря 2023 г. является частью серии юридических PDF-серий HackerNoon . Вы можете перейти к любой части этого файла здесь. Это часть 10 из 27.
:::
IV. ФАКТИЧЕСКИЕ ОБЪЯВЛЕНИЯ
С. Несанкционированное использование и копирование материалов Times ответчиками
82. Microsoft и OpenAI создавали и распространяли репродукции контента The Times несколькими независимыми способами в ходе обучения своих LLM и использования продуктов, которые их включают.
1. Несанкционированное воспроизведение времени работает во время обучения модели GPT
83. Модели GPT ответчиков представляют собой семейство LLM, первая из которых была представлена в 2018 году, за ней последовали GPT-2 в 2019 году, GPT-3 в 2020 году, GPT-3,5 в 2022 году и GPT-4 в 2023 году. LLM в стиле чата, GPT-3.5 и GPT-4, разрабатывались в два этапа. Во-первых, модель трансформатора была предварительно обучена на очень большом объеме данных. Во-вторых, модель была «точно настроена» на гораздо меньшем контролируемом наборе данных, чтобы помочь модели решать конкретные задачи.
84. Этап предварительного обучения включал сбор и хранение текстового контента для создания наборов обучающих данных и обработку этого контента с помощью моделей GPT. Хотя OpenAI не выпускала обученные версии GPT-2 в дальнейшем, «из-за опасений [OpenAI] по поводу вредоносного применения этой технологии», OpenAI опубликовала общую информацию о своем процессе предварительного обучения для моделей GPT.[12] ]
85. GPT-2 включает 1,5 миллиарда параметров, что в 10 раз больше GPT.[13] Набор обучающих данных для GPT-2 включает в себя внутренний корпус OpenAI под названием «WebText», который включает в себя «текстовое содержимое 45 миллионов ссылок, опубликованных пользователями социальной сети Reddit».[14] Содержимое набора данных WebText было создан как «новый веб-сканер, который подчеркивает качество документа». [15] Набор данных WebText содержит ошеломляющее количество извлеченного из The Times контента. Например, домен NYTimes.com входит в число «15 лучших доменов по объему» в наборе данных WebText[16] и пятый «лучший домен» в наборе данных WebText с 333 160 записями.[17]
86. GPT-3 включает 175 миллиардов параметров и был обучен на наборах данных, перечисленных в таблице ниже.[18]
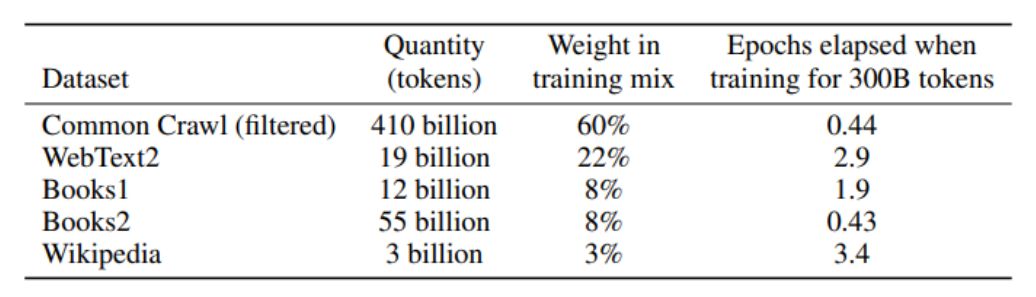
87. Один из этих наборов данных, WebText2, был создан для определения приоритетности ценного контента. Как и оригинальный WebText, он состоит из популярных исходящих ссылок с Reddit. Как показано в таблице выше, корпус WebText2 имел вес 22 % в обучающем наборе для GPT-3, несмотря на то, что составлял менее 4 % от общего числа токенов в обучающем наборе. Контент Times — в общей сложности 209 707 уникальных URL-адресов — составляет 1,23% всех источников, перечисленных в OpenWebText2, воссоздании с открытым исходным кодом набора данных WebText2, используемого при обучении GPT-3. Как и исходный WebText, OpenAI описывает WebText2 как «высококачественный» набор данных, который представляет собой «расширенную версию набора данных WebText… собранную путем очистки ссылок в течение более длительного периода времени».[19]
88. Самый взвешенный набор данных в GPT-3, Common Crawl, представляет собой «копию Интернета», предоставленную одноименной организацией 501(c)(3), управляемой богатыми венчурными инвесторами.[20] Домен www.nytimes.com является наиболее широко представленным частным источником (и третьим в общем зачете после Википедии и базы данных патентных документов США), представленным в отфильтрованном англоязычном подмножестве снимка Common Crawl за 2019 год, что составляет 100 миллионов токены (основные единицы текста): [21]
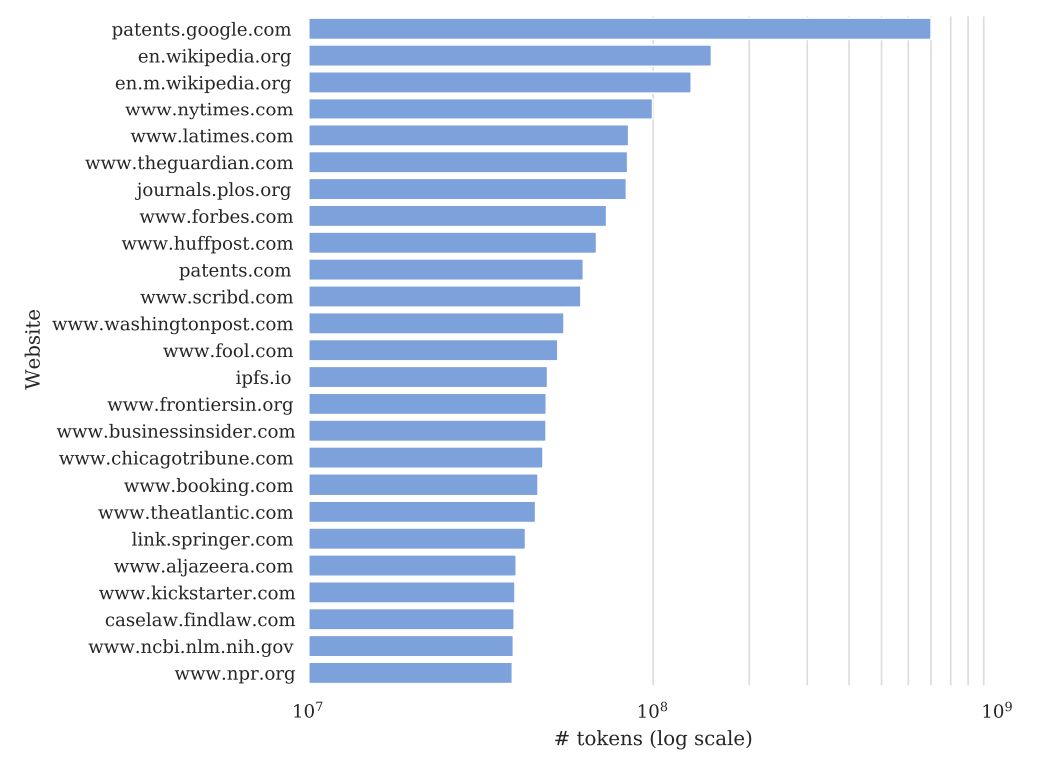
89. Набор данных Common Crawl включает не менее 16 миллионов уникальных записей контента из The Times в разделах News, Cooking, Wirecutter и The Athletic, а также более 66 миллионов записей контента из Times.
90. Что особенно важно, OpenAI признает, что «наборы данных, которые мы считаем более качественными, отбираются чаще» во время обучения.[22] Соответственно, по собственному признанию OpenAI, качественный контент, в том числе контент из The Times, был более важным и ценным для обучения моделей GPT, чем контент, взятый из других, менее качественных источников.
91. Хотя OpenAI не опубликовала много информации о GPT-4, эксперты подозревают, что GPT-4 включает 1,8 триллиона параметров, что более чем в 10 раз больше, чем GPT-3, и был обучен примерно на 13 триллионах токенов.[23] Обучающий набор для GPT-3, GPT-3.5 и GPT-4 состоял из 45 терабайт данных — эквивалент документа Microsoft Word длиной более 3,7 миллиарда страниц. [24] Между наборами данных Common Crawl, WebText и WebText2 Ответчики, вероятно, полностью использовали миллионы произведений, принадлежащих Times, для обучения моделей GPT.
92. Ответчики неоднократно копировали эту массу контента, защищенного авторским правом Times, без какой-либо лицензии или другой компенсации The Times. В рамках обучения моделей GPT Microsoft и OpenAI совместно разработали сложную, специальную суперкомпьютерную систему для хранения и воспроизведения копий набора обучающих данных, включая копии контента, принадлежащего The Times. Миллионы раз Работы были скопированы и обработаны (несколько раз) с целью «обучения» моделей GPT Ответчиков.
93. По имеющейся информации и предположениям, Microsoft и OpenAI действовали совместно при крупномасштабном копировании материалов The Times, связанных с созданием моделей GPT, запрограммированных для точной имитации содержания The Times и авторов. Microsoft и OpenAI сотрудничали при разработке моделей GPT, выборе наборов обучающих данных и контроле процесса обучения. Как заявил г-н Наделла:
Итак, я называю это множеством вариантов дизайна продукта, когда вы думаете об ИИ и безопасности ИИ. Тогда давайте подойдем к этому с другой стороны. Вы должны по-настоящему заботиться о предварительно обученных данных, поскольку модели обучаются на предварительно обученных данных. Каково качество и происхождение этих предварительно обученных данных? Здесь мы проделали большую работу.[25]
94. В той степени, в которой Microsoft не отбирала произведения, использованные для обучения моделей GPT, она действовала в рамках самопровозглашенного «партнерства» с OpenAI в отношении этого выбора, знала или умышленно не знала о идентичности выбранных работ в силу своих знание природы и особенностей обучающих корпусов и критериев отбора, используемых OpenAI, и/или имело право и возможность препятствовать использованию OpenAI какой-либо конкретной работы для обучения посредством физического контроля над суперкомпьютером, который он разработал для этой цели, и его юридическое и финансовое влияние на Ответчиков OpenAI.
95. По имеющейся информации и предположениям, Microsoft и OpenAI продолжают создавать несанкционированные копии Times Works в форме синтетических результатов поиска, возвращаемых их продуктами Bing Chat и Browse with Bing. Microsoft активно собирает копии Times Works, используемые для получения таких результатов в процессе сканирования Интернета, чтобы создать индекс для своей поисковой системы Bing.
96. По имеющейся информации и предположениям, Microsoft и OpenAI в настоящее время или в ближайшем будущем начнут создавать дополнительные копии Times Works для обучения и/или точной настройки LLM GPT-5 следующего поколения.
97. Крупномасштабное коммерческое использование контента Times Ответчиками не лицензируется, а Ответчики не получили разрешения от The Times на копирование и использование ее работ для создания своих инструментов GenAI.
:::совет Продолжить чтение здесь.
:::
[12] OpenAI, Лучшие языковые модели и их последствия, OPENAI (14 февраля 2019 г.), https://openai.com/research/better-language-models.
[13] То же.
[14] Карта модели GPT-2, GITHUB (ноябрь 2019 г.), https://github.com/openai/gpt-2/blob/master/model_card.md.
[15] РЭДФОРД И ДР., ЯЗЫКОВЫЕ МОДЕЛИ — МНОГОЗАДАЧНЫЕ УЧАЩИЕСЯ БЕЗ КОНТРОЛЯ 3 (2018), https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf.
[16] Карта модели GPT-2, примечание 14 выше.
[17] GPT-2/domains.txt, GITHUB, https://github.com/openai/gpt-2/blob/master/domains.txt (последнее посещение 21 декабря 2023 г.).
[18] БРАУН И ДР., ЯЗЫКОВЫЕ МОДЕЛИ ДЛЯ НЕСКОЛЬКИХ ИЗУЧАЮЩИХ 9 (2020), https://arxiv.org/pdf/2005.14165.pdf.
[19] Там же. в 8.
[20] COMMON CRAWL, https://commoncrawl.org/ (последнее посещение 21 декабря 2023 г.).
[21] Додж и др., ДОКУМЕНТИРОВАНИЕ БОЛЬШОЙ ВЕБ-ТЕКСТОВОЙ КОРПОРЫ: ПРАКТИЧЕСКОЕ ИССЛЕДОВАНИЕ ОГРОМНОГО ЧИСТОГО КОРПУСА (2021), https://arxiv.org/abs/2104.08758.
[22] BROWN et al., примечание 18 выше.
[23] Максимилиан Шрайнер, Архитектура GPT-4, утечка данных, затраты и многое другое, ДЕКОДЕР (11 июля 2023 г.), https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more -утечка/.
[24] Киндра Купер, OpenAI GPT-3: все, что вам нужно знать [обновлено], SPRINGBOARD (27 сентября 2023 г.), https://www.springboard.com/blog/data-science/machine-learning-gpt -3-open-ai/.
[25] Нилай Патель, Microsoft считает, что искусственный интеллект может превзойти Google в поиске — генеральный директор Сатья Наделла объясняет, почему, THE VERGE (7 февраля 2023 г.), https://www.theverge.com/23589994/microsoft-ceo-satya-nadella -bing-chatgpt-googlesearch-ai.
:::информация О серии документов HackerNoon Legal PDF: мы представляем вам наиболее важные технические и подробные материалы судебных дел, являющиеся общественным достоянием.
Это судебное дело 1:23-cv-11195 получено 29 декабря 2023 г. с сайта nycto-assets.nytimes. com является общественным достоянием. Документы, созданные судом, являются произведениями федерального правительства и в соответствии с законом об авторском праве автоматически становятся общественным достоянием и могут распространяться без юридических ограничений.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27268)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)