

Простота tRPC с мощью GraphQL
15 декабря 2022 г.Я большой поклонник tRPC. Идея экспортировать типы с сервера и импортировать их в клиент, чтобы иметь безопасный контракт между ними, даже без шага времени компиляции, просто блестящая. Спасибо всем, кто участвует в tRPC, вы делаете потрясающую работу.
Тем не менее, когда я смотрю на сравнения между tRPC и GraphQL, мне кажется, что мы сравниваем яблоки и апельсины.
Это становится особенно очевидным, когда вы смотрите на публичный дискурс вокруг GraphQL и tRPC. Look at this diagram by theo например:
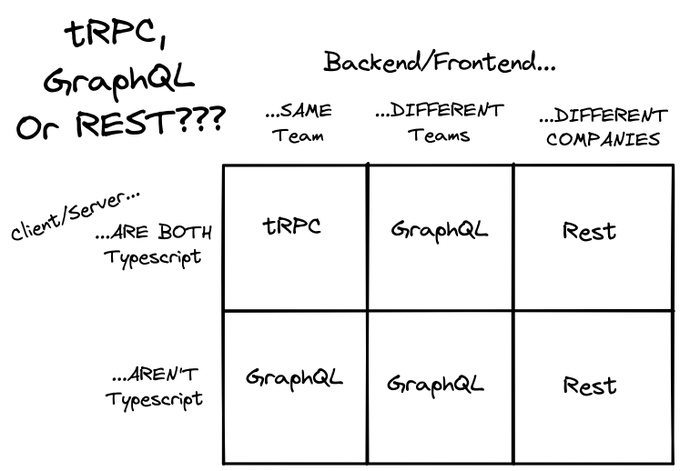
Тео подробно объяснил эту диаграмму, и, на первый взгляд, она имеет большой смысл. tRPC не требует этапа компиляции, невероятно удобен для разработчиков и намного проще, чем GraphQL.
Но действительно ли это полная картина или эта простота достигается за счет чего-то еще? Давайте выясним это, создав простое приложение с использованием tRPC и GraphQL.
Давайте создадим клон Facebook с помощью tRPC
Давайте представим дерево файлов со страницей для ленты новостей, компонентом для списка ленты и компонентом для элемента ленты.
src/pages/news-feed
├── NewsFeed.tsx
├── NewsFeedList.tsx
└── NewsFeedItem.tsx
В самом верху страницы ленты нам нужна информация о пользователе, уведомления, непрочитанные сообщения и т.д.
При отображении списка фида нам нужно знать количество элементов фида, есть ли другая страница и как ее получить.
Для элемента канала нам нужно знать автора, содержание, количество отметок «Нравится» и понравился ли он пользователю.
Если бы мы использовали tRPC, мы бы создали «процедуру» для загрузки всех этих данных за один раз. Мы вызываем эту процедуру в верхней части страницы, а затем передаем данные компонентам.
Наш компонент фида будет выглядеть примерно так:
import { trpc } from '../utils/trpc'
export function NewsFeed() {
const feed = trpc.newsFeed.useQuery()
return (
<div>
<Avatar>{feed.user}</Avatar>
<UnreadMessages> {feed.unreadMessages} unread messages </UnreadMessages>
<Notifications> {feed.notifications} notifications </Notifications>
<NewsFeedList feed={feed} />
</div>
)
}
Далее рассмотрим компонент списка каналов:
export function NewsFeedList({ feed }) {
return (
<div>
<h1>News Feed</h1>
<p>There are {feed.items.length} items</p>
{feed.items.map((item) => (
<NewsFeedItem item={item} />
))}
{feed.hasNextPage && (
<button onClick={feed.fetchNextPage}>Load more</button>
)}
</div>
)
}
И, наконец, компонент фида:
export function NewsFeedItem({ item }) {
return (
<div>
<h2>{item.author.name}</h2>
<p>{item.content}</p>
<button onClick={item.like}>Like</button>
</div>
)
}
Имейте в виду, что мы по-прежнему единая команда, все это TypeScript, единая кодовая база, и мы по-прежнему используем tRPC.
Давайте выясним, какие данные нам действительно нужны для рендеринга страницы. Нам нужен пользователь, непрочитанные сообщения, уведомления, элементы фида, количество элементов фида, следующая страница, автор, контент, количество отметок «Нравится» и понравилось ли это пользователю.
Где можно найти подробную информацию обо всем этом? Чтобы понять требования к данным для аватара, нам нужно взглянуть на компонент Аватар. Есть компоненты для непрочитанных сообщений и уведомлений, так что нам нужно посмотреть и на них. Компоненту списка фида требуется количество элементов, следующая страница и элементы фида. Компонент элемента фида содержит требования для каждого элемента списка.
В целом, если мы хотим понять требования к данным для этой страницы, нам нужно рассмотреть 6 различных компонентов. В то же время мы на самом деле не знаем, какие данные на самом деле нужны для каждого компонента. Каждый компонент не может объявить, какие данные ему нужны, поскольку в tRPC нет такой концепции.
Имейте в виду, что это всего лишь одна страница. Что произойдет, если мы добавим похожие, но немного разные страницы?
Допустим, мы создаем вариант новостной ленты, но вместо последних сообщений мы показываем самые популярные сообщения.
Мы могли бы более или менее использовать те же компоненты, с небольшими изменениями. Допустим, у популярных сообщений есть специальные значки, для которых требуются дополнительные данные.
Должны ли мы создать новую процедуру для этого? Или, может быть, мы могли бы просто добавить еще несколько полей в существующую процедуру?
Хорошо ли этот подход масштабируется, если мы добавляем все больше и больше страниц? Разве это не похоже на проблему, с которой мы столкнулись с REST API? У нас даже есть известные названия для этих проблем, такие как Overfetching и Underfetching, и мы даже не дошли до того, что говорим о проблеме N+1.
В какой-то момент мы можем решить разделить процедуру на одну корневую процедуру и несколько подпроцедур. Что, если мы извлекаем массив на корневом уровне, а затем для каждого элемента массива нам приходится вызывать другую процедуру для получения дополнительных данных?
Другим открытием может быть введение аргументов в исходную версию нашей процедуры, например. trpc.newsFeed.useQuery({withPopularBadges: true}).
Это сработает, но похоже, что мы начинаем заново изобретать функции GraphQL.
Давайте создадим клон Facebook с помощью GraphQL
Теперь давайте сравним это с GraphQL. В GraphQL есть концепция фрагментов, которая позволяет нам объявлять требования к данным для каждого компонента. Такие клиенты, как Relay, позволяют объявлять один запрос GraphQL вверху страницы и включать в запрос фрагменты дочерних компонентов.
Таким образом, мы по-прежнему делаем одну выборку в верхней части страницы, но платформа фактически поддерживает нас при объявлении и сборе требований к данным для каждого компонента.
Давайте рассмотрим тот же пример с использованием GraphQL, Fragments и Relay. Из соображений лени код не на 100% правильный, потому что я использую Copilot для его написания, но он должен быть очень близок к тому, как он будет выглядеть в реальном приложении.
import { graphql } from 'react-relay'
export function NewsFeed() {
const feed = useQuery(graphql`
query NewsFeedQuery {
user {
...Avatar_user
}
unreadMessages {
...UnreadMessages_unreadMessages
}
notifications {
...Notifications_notifications
}
...NewsFeedList_feed
}
`)
return (
<div>
<Avatar user={feed.user} />
<UnreadMessages unreadMessages={feed.unreadMessages} />
<Notifications notifications={feed.notifications} />
<NewsFeedList feed={feed} />
</div>
)
}
Далее, давайте посмотрим на компонент списка каналов. Компонент списка фида объявляет фрагмент для себя и включает фрагмент для компонента элемента фида.
import { graphql } from 'react-relay'
export function NewsFeedList({ feed }) {
const list = useFragment(
graphql`
fragment NewsFeedList_feed on NewsFeed {
items {
...NewsFeedItem_item
}
hasNextPage
}
`,
feed
)
return (
<div>
<h1>News Feed</h1>
<p>There are {feed.items.length} items</p>
{feed.items.map((item) => (
<NewsFeedItem item={item} />
))}
{feed.hasNextPage && (
<button onClick={feed.fetchNextPage}>Load more</button>
)}
</div>
)
}
И, наконец, компонент фида:
import { graphql } from 'react-relay'
export function NewsFeedItem({ item }) {
const item = useFragment(
graphql`
fragment NewsFeedItem_item on NewsFeedItem {
author {
name
}
content
likes
hasLiked
}
`,
item
)
return (
<div>
<h2>{item.author.name}</h2>
<p>{item.content}</p>
<button onClick={item.like}>Like</button>
</div>
)
}
Далее давайте создадим вариант ленты новостей с популярными значками на элементах ленты. Мы можем повторно использовать одни и те же компоненты, так как можем использовать директиву @include для условного включения популярного фрагмента значка.
import { graphql } from 'react-relay'
export function PopularNewsFeed() {
const feed = useQuery(graphql`
query PopularNewsFeedQuery($withPopularBadges: Boolean!) {
user {
...Avatar_user
}
unreadMessages {
...UnreadMessages_unreadMessages
}
notifications {
...Notifications_notifications
}
...NewsFeedList_feed
}
`)
return (
<div>
<Avatar user={feed.user} />
<UnreadMessages unreadMessages={feed.unreadMessages} />
<Notifications notifications={feed.notifications} />
<NewsFeedList feed={feed} />
</div>
)
}
Далее давайте посмотрим, как может выглядеть обновленный элемент списка каналов:
import { graphql } from 'react-relay'
export function NewsFeedItem({ item }) {
const item = useFragment(
graphql`
fragment NewsFeedItem_item on NewsFeedItem {
author {
name
}
content
likes
hasLiked
...PopularBadge_item @include(if: $withPopularBadges)
}
`,
item
)
return (
<div>
<h2>{item.author.name}</h2>
<p>{item.content}</p>
<button onClick={item.like}>Like</button>
{item.popularBadge && <PopularBadge badge={item.popularBadge} />}
</div>
)
}
Как видите, GraphQL достаточно гибок и позволяет нам создавать сложные веб-приложения, включая варианты одной и той же страницы, без необходимости дублировать слишком много кода.
Фрагменты GraphQL позволяют нам объявлять требования к данным на уровне компонентов
Кроме того, фрагменты GraphQL позволяют нам явно объявлять требования к данным для каждого компонента, которые затем поднимаются вверх страницы, а затем извлекаются в одном запросе.
GraphQL отделяет реализацию API от получения данных
Прекрасный опыт tRPC для разработчиков достигается за счет объединения двух совершенно разных задач в одну концепцию: реализация API и потребление данных.
Важно понимать, что это компромисс. Бесплатных обедов не бывает. Простота tRPC достигается за счет гибкости.
С GraphQL вам придется вкладывать гораздо больше средств в разработку схемы, но эти инвестиции окупаются, когда вам нужно масштабировать приложение на множество, но связанных страниц.
Отделив реализацию API от извлечения данных, становится намного проще повторно использовать одну и ту же реализацию API для разных вариантов использования.
Цель API — отделить внутреннюю реализацию от внешнего интерфейса
Есть еще один важный аспект, который следует учитывать при создании API. Возможно, вы начинаете с внутреннего API, который используется исключительно вашим собственным интерфейсом, и tRPC может отлично подойти для этого варианта использования.
Но как насчет будущего вашего начинания? Какова вероятность того, что вы будете расширять свою команду? Возможно ли, что другие команды или даже третьи лица захотят использовать ваши API?
И REST, и GraphQL созданы для совместной работы. Не все команды будут использовать TypeScript, и если вы выходите за границы компании, вам нужно предоставлять API таким образом, чтобы их было легко понять и использовать.
Существует множество инструментов для демонстрации и документирования REST и GraphQL API, а tRPC явно не предназначен для этого варианта использования.
Так что, хотя начинать с tRPC здорово, вы, скорее всего, в какой-то момент перерастете его, о чем, я думаю, Тео также упомянул в одном из своих видео.
Конечно, можно сгенерировать спецификацию OpenAPI из API tRPC, инструментарий существует, но если вы строите бизнес, который в конечном итоге будет полагаться на предоставление API третьим сторонам, ваши RPC не смогут конкурировать с хорошо спроектированными REST и API-интерфейсы GraphQL.
Заключение
Как уже говорилось в начале, я большой поклонник идей, лежащих в основе tRPC. Это отличный шаг в правильном направлении, упрощающий получение данных и делающий его более удобным для разработчиков.
С другой стороны, GraphQL, Fragments и Relay — это мощные инструменты, помогающие создавать сложные веб-приложения. В то же время настройка довольно сложна, и нужно изучить множество концепций, пока вы не освоитесь.
Хотя tRPC поможет вам быстро начать работу, весьма вероятно, что в какой-то момент вы перерастете его архитектуру. будущее. Насколько сложными будут требования к извлечению данных? Будут ли несколько команд использовать ваши API? Будете ли вы раскрывать свои API третьим лицам?
Перспективы
С учетом всего сказанного, что, если бы мы могли объединить лучшее из обоих миров? Как будет выглядеть клиент API, сочетающий простоту tRPC с мощью GraphQL? Можем ли мы создать чистый API-клиент TypeScript, который даст нам возможности фрагментов и ретрансляции в сочетании с простотой tRPC?
Представьте, что мы берем идеи tRPC и объединяем их с тем, что мы узнали из GraphQL и Relay.
Вот небольшой предварительный просмотр:
// src/pages/index.tsx
import { useQuery } from '../../.wundergraph/generated/client'
import { Avatar_user } from '../components/Avatar'
import { UnreadMessages_unreadMessages } from '../components/UnreadMessages'
import { Notifications_notifications } from '../components/Notifications'
import { NewsFeedList_feed } from '../components/NewsFeedList'
export function NewsFeed() {
const feed = useQuery({
operationName: 'NewsFeed',
query: (q) => ({
user: q.user({
...Avatar_user.fragment,
}),
unreadMessages: q.unreadMessages({
...UnreadMessages_unreadMessages.fragment,
}),
notifications: q.notifications({
...Notifications_notifications.fragment,
}),
...NewsFeedList_feed.fragment,
}),
})
return (
<div>
<Avatar />
<UnreadMessages />
<Notifications />
<NewsFeedList />
</div>
)
}
// src/components/Avatar.tsx
import { useFragment, Fragment } from '../../.wundergraph/generated/client'
export const Avatar_user = Fragment({
on: 'User',
fragment: ({ name, avatar }) => ({
name,
avatar,
}),
})
export function Avatar() {
const data = useFragment(Avatar_user)
return (
<div>
<h1>{data.name}</h1>
<img src={data.avatar} />
</div>
)
}
// src/components/NewsFeedList.tsx
import { useFragment, Fragment } from '../../.wundergraph/generated/client'
import { NewsFeedItem_item } from './NewsFeedItem'
export const NewsFeedList_feed = Fragment({
on: 'NewsFeed',
fragment: ({ items }) => ({
items: items({
...NewsFeedItem_item.fragment,
}),
}),
})
export function NewsFeedList() {
const data = useFragment(NewsFeedList_feed)
return (
<div>
{data.items.map((item) => (
<NewsFeedItem item={item} />
))}
</div>
)
}
// src/components/NewsFeedItem.tsx
import { useFragment, Fragment } from '../../.wundergraph/generated/client'
export const NewsFeedItem_item = Fragment({
on: 'NewsFeedItem',
fragment: ({ id, author, content }) => ({
id,
author,
content,
}),
})
export function NewsFeedItem() {
const data = useFragment(NewsFeedItem_item)
return (
<div>
<h1>{data.title}</h1>
<p>{data.content}</p>
</div>
)
}
Что вы думаете? Вы бы использовали что-то подобное? Видите ли вы ценность в определении зависимостей данных на уровне компонентов или предпочитаете придерживаться определения удаленных процедур на уровне страницы? Буду рад услышать ваше мнение...
В настоящее время мы находимся на этапе проектирования, чтобы создать лучший способ извлечения данных для React, NextJS и всех других фреймворков. Если вам интересна эта тема, подпишитесь на меня в Twitter, чтобы быть в курсе последних событий.
Если вы хотите присоединиться к обсуждению и обсудить с нами RFC, присоединяйтесь к нашему серверу Discord.
Далее
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27538)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)