
Наука, стоящая за аудиозависимыми языковыми моделями
18 июня 2025 г.Таблица ссылок
Аннотация и 1 введение
2 подхода
2.1 Архитектура
2.2 Multimodal Trancing Paneletuning
2.3 Учебное обучение программы с эффективным характеристиком параметров
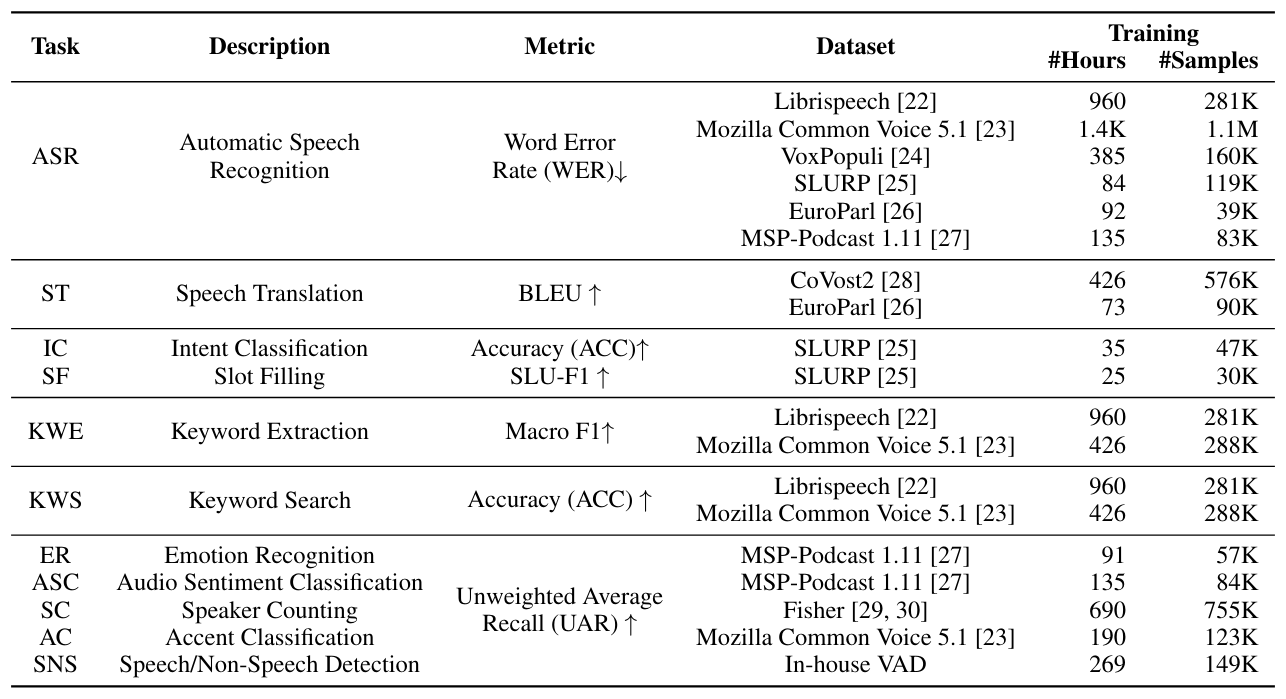
3 эксперименты
4 Результаты
4.1 Оценка моделей речи.
4.2 Обобщение между инструкциями
4.3 Стратегии повышения производительности
5 Связанная работа
6 Заключение, ограничения, заявление о этике и ссылки
Приложение
A.1 Audio Encoder перед тренировкой
A.2 Гиперпараметры
A.3 Задачи
2.1 Архитектура
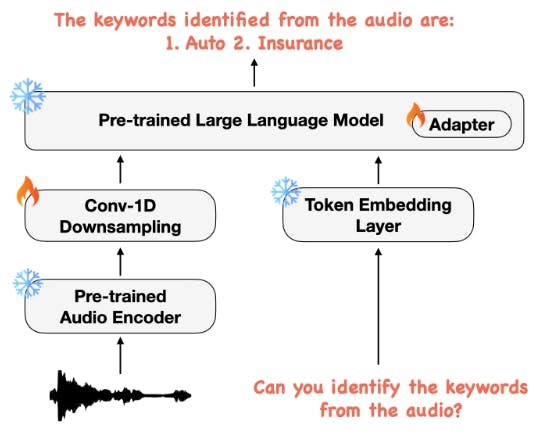
Как показано на рисунке 2, наша мультимодальная модельная архитектура состоит из трех основных компонентов: (1) предварительно обученный аудиокодер для кодирования аудиосигнала в последовательность функций, (2) модуль 1-D свертки, который работает над последовательности аудио функций, чтобы сократить длину последовательности и (3) предварительно обученные LLM для использования функций Audio и текстовых инструкций для выполнения необходимых задач. Детали каждой из этих подсистем описаны ниже.

2.2 Multimodal Trancing Paneletuning

2.3 Учебное обучение программы с эффективным характеристиком параметров

На первом этапе мы тренируем только модуль снижения свертки и веса промежуточного слоя без введения адаптеров LORA. Кроме того, на этом этапе используются только образцы из задачи автоматического распознавания речи (ASR). Поскольку кодируемые векторы речевых функций могут сильно отличаться от встроенных токенов текстового ввода, этот этап может помочь выровнять их в общем пространстве встраивания, изучив только параметры для модуля снижения свертки в ограниченном пространстве задачи ASR. Это позволяет предварительно обученному текстовому LLM для участия в содержании аудио последовательности и генерировать транскрипцию речи.
На втором этапе мы теперь представляем адаптеры Lora для обучения модели. На этом этапе веса промежуточного слоя, модуль снижения, а также адаптеры LORA не являются нереховыми. Поскольку адаптеры LORA тренируются с нуля, мы сначала позволяем весам адаптера прогреваться, тренируясь только по задаче ASR, чтобы быть выровненным с общим пространством встраивания, изученного модулем снижения свертки на первом этапе. Наконец, мы вводим дополнительные задачи поверх задачи ASR и продолжаем тренироваться, сохраняя при этом предварительно обученный аудиокодер и веса LLM заморожены. Поскольку разминка с использованием только задачи ASR позволяет модели понять содержимое
Аудио, наш подход к обучению учебным программам приводит к более быстрому конвергенции по различным речевым задачам, которые полагаются на разговорное содержание звука.
Авторы:
(1) Nilaksh Das, AWS AI Labs, Amazon и равный вклад;
(2) Saket Dingliwal, AWS AI Labs, Amazon (skdin@amazon.com);
(3) Шрикант Ронанки, AWS AI Labs, Amazon;
(4) Рохит Патури, AWS AI Labs, Amazon;
(5) Zhaocheng Huang, AWS AI Labs, Amazon;
(6) Prashant Mathur, AWS AI Labs, Amazon;
(7) Цзе Юань, AWS AI Labs, Amazon;
(8) Дхануш Бекал, AWS AI Labs, Amazon;
(9) Син Ниу, AWS AI Labs, Amazon;
(10) Sai Muralidhar Jayanthi, AWS AI Labs, Amazon;
(11) Xilai Li, AWS AI Labs, Amazon;
(12) Карел Мунднич, AWS AI Labs, Amazon;
(13) Моника Сункара, AWS AI Labs, Amazon;
(14) Даниэль Гарсия-Ромеро, AWS AI Labs, Amazon;
(15) Кю Дж. Хан, AWS AI Labs, Amazon;
(16) Катрин Кирххофф, AWS AI Labs, Amazon.
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27352)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)