
Механика моделей вознаграждения в RLHF
17 января 2024 г.:::информация Авторы:
(1) Натан Ламберт, Институт искусственного интеллекта Аллена;
(2) Роберто Каландра, Технический университет Дрездена.
:::
Таблица ссылок
Понимание несоответствия целей
3 Фон
3.1 Обучение модели вознаграждения
Модели вознаграждения обучаются с использованием данных о предпочтениях человека, которые чаще всего состоят из задачи, заданной в подсказке модели, т. е. запроса или инструкции, и оценок выполнения или ответа. Обратная связь может состоять из выбора лучшего из групп ответов (Ziegler et al., 2019), оценок и ранжирования группы ответов-кандидатов (Ouyang et al., 2022), выбора между парой ответов (Bai et al., 2022). ., 2022) (выберите лучший ответ между двумя вариантами) и даже более детальные данные (Z. Wu et al., 2023). Нанятым работникам обычно даются подробные инструкции о том, каким стилям, явлениям или ценностям следует отдать приоритет в своих ярлыках.
Модели вознаграждения, обученные для RLHF, чаще всего обучаются как классификаторы между выбранным и отклоненным завершением для запроса перед оптимизацией с помощью RL, где они возвращают скалярное значение для каждого фрагмента текста. Учитывая два варианта завершения y из подсказки x и баллы, которые они получают в результате скалярного вывода r из изначально необученной головы значения в LLM или модели ценности, следует потеря для модели вознаграждения (Askell et al., 2021; Оуян и др., 2022)

3.2 Углубленное изучение языка

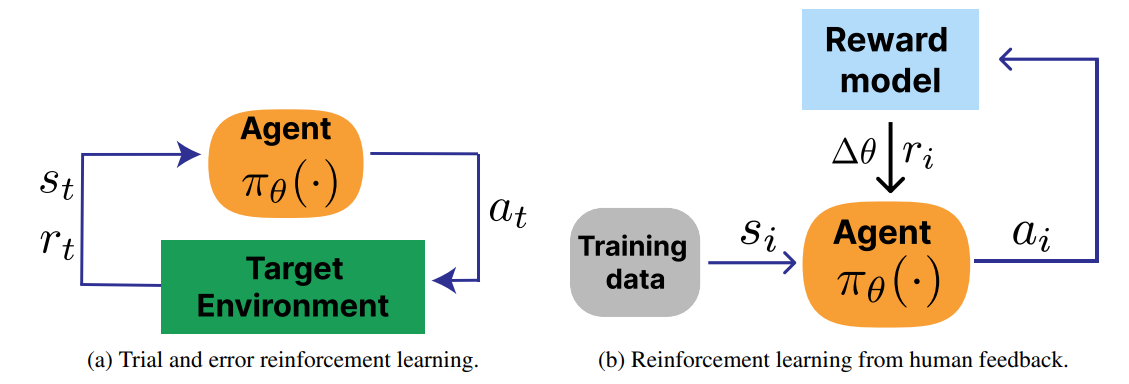
В рамках LLM генерирующая модель называется моделью политики. В RLHF коэффициент дисконтирования вознаграждения установлен равным 1, и никаких дальнейших действий для данной подсказки не предпринимается, что делает проблему контекстуальной бандитской проблемой. Пример петли RLHF показан на рис. 2b в сравнении со стандартной петлей RL, показанной на рис. 2a.
:::информация Этот документ доступен на arxiv по лицензии CC 4.0.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27087)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)