

Последнее звание, которое нам нужно? Видение Qdylora на будущее настройки LLM
2 июля 2025 г.Таблица ссылок
Аннотация и 1. Введение
- Предложенный метод: квантовая Dylora
- Эксперименты и оценка
- На полуосорвантном поведении Qdylora
- Заключение, ограничения и ссылки
А. Дополнительный материал
А.1 Гиперпараметры
А.2. Сгенерированное качество текста
5 Заключение
Qdylora предлагает эффективную и эффективную технику для тонких настраивающих LLM на основе LORA на нижестоящих задачах. Устранение необходимости точной настройки нескольких моделей, чтобы найти оптимальный ранг LORA и предлагая возможность тонкой настройки более крупных LLMS, являются двумя основными преимуществами Qdylora. Экспериментальные результаты показали, что оптимальный ранг для Qdylora может быть удивительно низким, но он последовательно превосходит Qlora. Qdylora обеспечивает большую гибкость для развертывания LLMS в различных контекстах и представляет собой многообещающий шаг к тому, чтобы сделать тонкую настройку больших языковых моделей более доступными и эффективными.
Ограничения
В то время как 4-битная Qdylora демонстрирует заметную производительность, она не достигает достижения уровня производительности полной точной настройки. Одним из возможных растворов может быть динамическая квантовая Dylora (dyqdylora), в котором уровень квантования также может варьироваться во время создания. В частности, стратегия создания может динамически переключаться между различными уровнями квантования на основе предопределенной обратной связи обучения. Кроме того, необходимы дальнейшие исследования для изучения влияния скаляра Лоры и диапазона основных рангов в Qdylora.
Ссылки
Армен Агаджаньян, Люк Зеттлемуер и Сонал Гупта. 2020. Внутренняя размерность объясняет эффективность точной настройки языка. Arxiv Preprint arxiv: 2012.13255.
Хёнг Вон Чунг, Ле Хоу, Шейн Лонгпра, Баррет Зоф, Йи Тэй, Уильям Федус, Эрик Ли, Сюэжи Ван, Мостафа Дехгани, Сиддхартха Брахма и др. 2022. Масштабирование моделей с финикой инструкций. Arxiv Preprint arxiv: 2210.11416.
Карл Кобб, Винеет Косараджу, Мохаммад Баварский, Марк Чен, Хивоо Джун, Лукаш Кайзер, Матиас Плапперт, Джерри Творек, Джейкоб Хилтон, Рейхиро Накано, et al. 2021. Обучение проверки для решения задач по математике. Arxiv Preprint arxiv: 2110.14168.
Тим Деттмерс, Артидоро Пагнони, Ари Хольцман и Люк Зеттлемойер. 2023. Qlora: Эффективное создание квантовых LLMS. Arxiv Preprint arxiv: 2305.14314.
Нин Дин, Юдзия Цинь, Гуан Ян, Фучао Вей, Зонган Ян, Юшэн С.У., Шенгидинг Ху, Юлин Чен, Чи-Чан, Вайз Чен и др. 2023. Параметр-эффективная тонкая настройка крупномасштабных предварительных языковых моделей. Интеллект природы, 5 (3): 220–235.
Али Эдалати, Марзи Тахей, Иван Кобизев, Вахид Партови Ния, Джеймс Дж. Кларк и Мехди Резагхолизаде. 2022. Крона: Параметр эффективная настройка с адаптером кронекера. Arxiv Preprint arxiv: 2212.10650.
Junxian He, Chunting Zhou, Xuezhe MA, Taylor Bergkirkpatrick и Graham Neubig. 2021. На пути к единому представлению параметров-эффективного переноса обучения. Arxiv Preprint arxiv: 2110.04366.
Дэн Хендриккс, Коллин Бернс, Стивен Басарт, Энди Зу, Мантас Мазейка, песня рассвета и Джейкоб Стейнхардт. 2020. Измерение массивного многозадачного языка понимания. Arxiv Preprint arxiv: 2009.03300.
Нил Хоулсби, Андрей Джургиу, Станислав Ястзбски, Бруна Моррон, Квентин де Ларуссилхе, Андреа Гесмундо, Мона Аттарияян и Сильвен Гелли. 2019. Параметр-эффективное обучение передачи для NLP. На Международной конференции по машинному обучению, страницы 2790–2799. PMLR.
Эдвард Дж. Ху, Йелонг Шен, Филипп Уоллис, Зейуан Аллен-зху, Юаньжи Ли, Шин Ван, Лу Ван и Вейху Чен. 2021. LORA: Низкая адаптация крупных языковых моделей. Arxiv Preprint arxiv: 2106.09685.
Мандар Джоши, Юнсол Чой, Даниэль С. Уэлд и Люк Зеттлемуер. 2017. Arxiv Preprint arxiv: 1705.03551.
Андреас Кёпф, Янник Килчер, Дмитрий фон Рютт, Сотирис Анагностид, Чжи-Руи Там, Кейт Стивенс, Абдулла Бархум, Нгуен Мин Дук, Оливер Стэнли, Ричард Наджифи, и сэм. 2023. Открытые разговоры-демократизация крупной языковой модели. Arxiv Preprint arxiv: 2304.07327.
SE Jung Kwon, Jeonghoon Kim, Jeongin Bae, Kang Min Yoo, Jin-Hwa Kim, Baeseong Park, Byeongwook Kim, Jung-Woo Ha, Nako Sung и Dongsoo Lee. 2022. Альфатун: квантование с планой параметрической адаптацией крупномасштабных предварительно обученных языковых моделей. Arxiv Preprint arxiv: 2210.03858.
Хакун Лю, Дерек Там, Мохаммед Мукейт, Джей Мохта, Тенгао Хуанг, Мохит Бансал и Колин А. Раффель. 2022. Несколько выстрелов-эффективной тонкой настройки лучше и дешевле, чем в контексте. Достижения в системах обработки нейронной информации, 35: 1950–1965.
Сяо Лю, Ханью Лай, Хао Ю, Ифан Сюй, Аохан Зенг, Чжэнсиао Д.У., Пенг Чжан, Юсиао Донг и Цзе Тан. 2023. WebGlm: На пути к эффективной системе ответов на вопросы, связанной с вайком, с человеческими предпочтениями. Arxiv Preprint arxiv: 2306.07906.
Юнинг Мао, Ламберт Матиас, Руи Хоу, Амджад Альмахайри, Хао Ма, Цзявей Хан, Вэнь-Тау Йи и Мадиан Хабса. 2021. Unipelt: унифицированная структура для настройки модели с параметром. Arxiv Preprint arxiv: 2110.07577.
Yi-Lin Sung, Jaemin Cho и Mohit Bansal. 2022. LST: Лестница боковой настройки для параметров и эффективного переноса в памяти. Достижения в системах обработки нейронной информации, 35: 12991–13005.
Рохан Таори, Ишаан Гулраджани, Тиани Чжан, Янн Дюбуа, Сюэхен Ли, Карлос Гестрин, Перси Лян и Тацунори Б Хасимото. 2023. Стэнфордская Альпака: модель Llama с учетом инструкций.
Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev и Ali Ghodsi. 2022. Dylora: Параметр эффективная настройка предварительно обученных моделей с использованием динамической адаптации с низким уровнем ранга без поиска. Arxiv Preprint arxiv: 2210.07558.
Йижонг Ван, Йегане Корди, Сваруп Мишра, Алиса Лю, Ной А. Смит, Даниэль Хашаби и Ханнане Хаджиширзи. 2022. Самоубийство: выравнивание языковой модели с самого сгенерированными инструкциями. Arxiv Preprint arxiv: 2212.10560.
A.1 Гиперпараметры
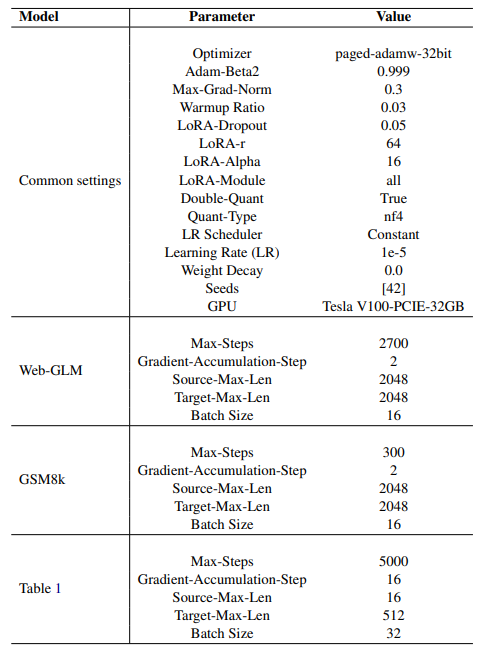
В таблице 4 представлен обзор гиперпараметров и экспериментальных конфигураций, используемых в этом исследовании, которые являются важными конфигурациями, которые определяют различные аспекты учебного процесса и поведения модели в этом исследовании. Распространенные ключевые параметры в экспериментах включают выбор оптимизатора, значение Adam-Beta2, максимальную норму градиента и коэффициент разминки, которые в совокупности влияют на то, как модель корректирует свои веса во время тренировки. Специфичные для LORA параметры, такие как вероятность выбывания LORA, максимальный ранг LORA и альфа-значение контролируют поведение слоев LORA. Кроме того, двойное квантование и тип квантования влияют на точность численных представлений в модели, которые считаются такими же, как базовые. Планирование скорости обучения и распад веса способствуют процессу оптимизации, помогая предотвратить переосмысление и стабилизацию обучения. Случайные семена обеспечивают воспроизводимость, в то время как указанный графический процессор определяет оборудование, используемое для обучения. Каждая конфигурация модели, будь то для веб-GLM, GSM8K или конкретного эксперимента, изложенного в таблице 1, определяют параметры, адаптированные для характеристик набора данных и доступных вычислительных ресурсов. Эти гиперпараметры в совокупности формируют учебный процесс, в конечном итоге влияя на производительность и эффективность моделей в исследовании.
А.2 Качество текста сгенерированного текста
Чтобы описать качество текстов, полученных Qdylora, образец запроса, взятого из GSM8K, подается в Falcon-40B, обученный Qdylora. Ниже мы сообщаем о сгенерированных ответах для разных рангов LORA.
ЗапросУтки Джанет откладывают 16 яиц в день. Она ест три на завтрак каждое утро и ежедневно выпекает кексы для своих друзей с четырьмя. Она продает остаток на фермерском рынке ежедневно за 2 доллара за свежее утиное яйцо. Сколько в долларах она зарабатывает каждый день на фермерском рынке?
Ранг = 64: Джанет имеет 16 - 3 - 4 = «16-3-4 = 7» 7 осталось яйца. Она продает 7 - 16 = «7-16 = 9» 9 яиц в
Фермерский рынок. Она делает 9 * 2 = «9 * 2 = 18» 18 на фермерском рынке каждый день.
Ранг = 32:Она ест 3 яйца на завтрак и выпекает 4 кекса в день, поэтому она использует 3 + 4 = «3 + 4 = 7» 7 яиц в день. У нее 16 - 7 = «16- 7 = 9» 9 яиц, оставленных каждый день. Она продает эти яйца на фермерском рынке за 2 доллара за яйцо, поэтому она делает 2 * 9 = «2 * 9 = 18» 18 в день на рынке.
Ранг = 28: Она ест 3 яйца на завтрак и выпекает 4 кекса в день, поэтому она использует 3+4 = «3+4 = 7» 7 яиц в день. Она продает 16-7 = «16-7 = 9» 9 яиц в день за 2 доллара за яйцо. Она делает 9*2 = «9*2 = 18» 18 в день на рынке.
Ранг = 16: Утки Джанет откладывают 16 яиц в день, и она ест 3 на завтрак каждое утро, поэтому у нее осталось 16-3 = 13 яиц. Джанет выпекает 4 кекса каждый день, и она использует 4 яйца, поэтому у нее осталось 13-4 = 9 яиц. Джанет продает оставшиеся яйца на фермерском рынке по 2 доллара каждый, поэтому она зарабатывает 9*2 = «9*2 = 18» 18 долларов в день. Джанет зарабатывает 18 долларов в день на фермерском рынке.
Авторы:
(1) Хоссейн Раджабзаде, Университет Ватерлоо и лабораторию Хуауэя Ноа (hossein.rajabzadeh@uwaterloo.ca);
(2) Mojtaba Valipour, Университет Ватерлоо (mojtaba.valipour@uwaterloo.ca);
(3) Tianshu Zhu, Huawei Noah's Ark Lab (tianshu.zhu@huawei.com);
(4) Марзи Тахей, лаборатория Арк Хуауей Ноа (marzieh.tahaei@huawei.com);
(5) Hyock Ju Kwon, (hjkwon@uwaterloo.ca);
(6) Али Годси, (ali.ghodsi@uwaterloo.ca);
(7) Boxing Chen, Huawei Noah's Ark Lab (boxing.chen@huawei.com);
(8) Мехди Резагхолизаде, лаборатория Арк Хуавей Ноа (mehdi.rezagholizadeh@huawei.com).
Эта статья есть
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Лучшие новогодние подарки для владельцев домашних животных
29 мая 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27342)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)