
Итеративное применение RLHF в языковых моделях
17 января 2024 г.:::информация Авторы:
(1) Натан Ламберт, Институт искусственного интеллекта Аллена;
(2) Роберто Каландра, Технический университет Дрездена.
:::
Таблица ссылок
Понимание несоответствия целей
5 обсуждений
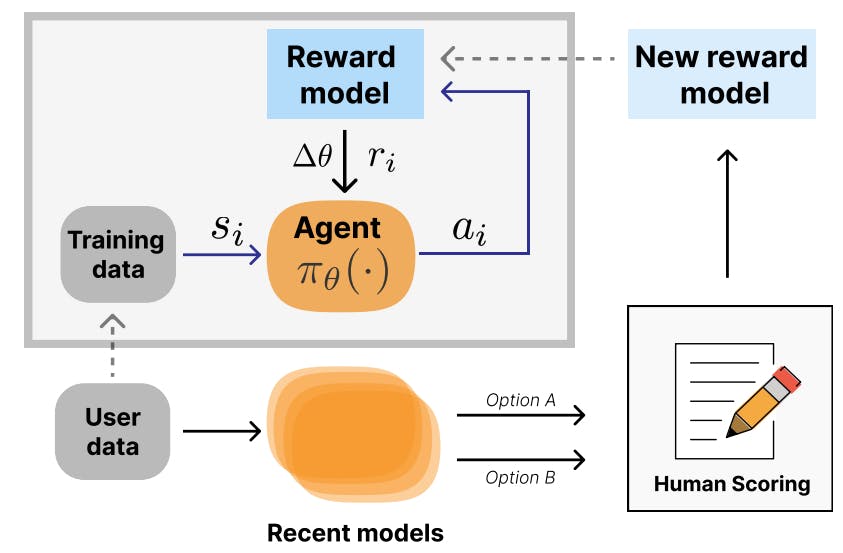
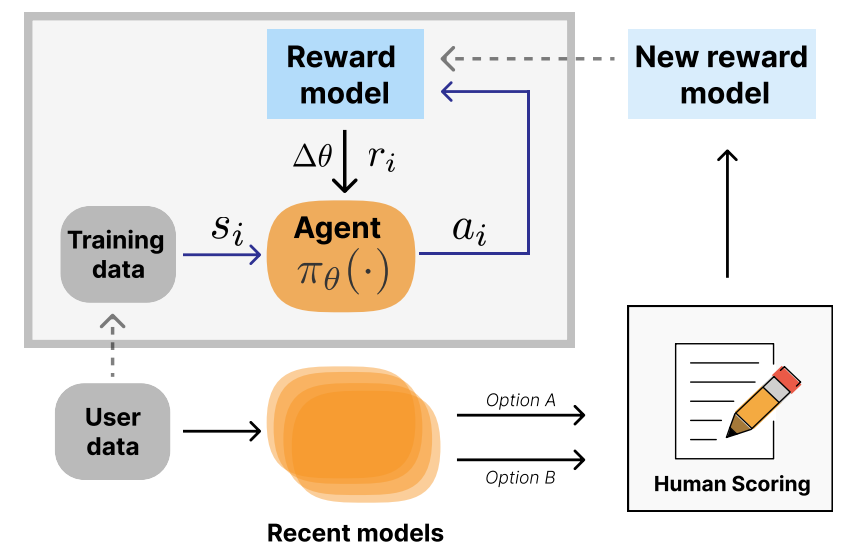
Итеративное развертывание RLHF Итеративная форма развертывания RLHF, при которой модели вознаграждения переобучаются на основе пользовательских данных, что вызывает второй цикл обратной связи, показано на рис. 4. Шульман (2023) обсуждает, как это используется в ChatGPT для устранения таких проблем, как уклончивость, многословие и другие неожиданные и нежелательные качества. Проектирование в этой среде еще больше усложняет инженерные задачи, но позволяет итеративно устранять несоответствия. Этот стиль итеративного развертывания RL понимается как экзогенная обратная связь (Гилберт, Дин, Зик и Ламберт, 2022) и может иметь социальные последствия.
В этом пространстве есть некоторая литература, но расширить соответствующие работы до масштабов использования современных LLM будет сложно. Например, Зур и Арци (2022) демонстрируют теоретические результаты по оптимизации внешнего цикла моделей, настроенных на инструкции.
Контекстные бандиты Изменения, внесенные в RL-оптимизацию RLHF, превращают ее в проблему контекстуальных бандитов, где агент выполняет одно действие, а динамика абстрагируется в одну пару траектория-награда. Работа в этой области исследовала потенциал интеграции частичных, искаженных или зашумленных отзывов людей в процесс оптимизации (Нгуен, Дауме III и Бойд-Грабер, 2017).
Подраздел дуэльных бандитов еще больше конкретизировал проблему, которая тесно связана с RLHF, но в основном в теоретической работе с гораздо меньшими моделями, наборами данных и задачами. Юэ, Бродер, Кляйнберг и Йоахимс (2012) объясняют это пространство в работе, показывая теоретические границы:
«В отличие от традиционных подходов, которые требуют, чтобы абсолютное вознаграждение выбранной стратегии было измеримым и наблюдаемым, наша установка предполагает только наличие (зашумленной) двоичной обратной связи об относительном вознаграждении двух выбранных стратегий. Этот тип относительной обратной связи особенно уместен в приложениях, где абсолютные награды не имеют естественной шкалы или их трудно измерить... но где легко провести парные сравнения».
Это, хотя и тесно связано с RLHF, потребует серьезных экспериментов, чтобы его можно было применить. Другие использовали это в работе, изучая непосредственно человеческие предпочтения (Секхари, Шридхаран, Сан и Ву, 2023) или неявную обратную связь с людьми (Магакян и др., 2022).
:::информация Этот документ доступен на arxiv по лицензии CC 4.0.
:::
Оригинал
🔥 Популярное на этой неделе
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27360)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)