LIME расшифровывается как «Локальные интерпретируемые модельно-независимые объяснения». Это метод, используемый исследователями машинного обучения для объяснения надежности модели и измерения достоверности алгоритма.
Теперь у вас будет явное сомнение в том, что у нас есть много показателей эволюции для измерения производительности моделей, независимо от того, являются ли они контролируемой или неконтролируемой категорией. Итак, зачем нам LIME?
Проблема с метриками математической оценки заключается в том, что они не могут объяснить причины прогноза простым понятным способом. LIME не является методом, противоположным традиционным показателям оценки, а представляет собой набор рекомендаций по повышению надежности модели в дополнение к достоверности статистических показателей с некоторой дополнительной интерпретируемой информацией.
Интуиция, стоящая за концепцией LIME в AI & МЛ
Предположим, что мы создали алгоритм классификации изображений, чтобы предсказать, является ли человек мужчиной или женщиной, если мы предоставим фотографию в качестве входных данных.

Модель будет предсказывать изображение 1 как мужчину, а изображение 2 как женщину на основе некоторых показателей оценки, таких как точность, достоверность, полнота или оценка f1.
Теперь, в чем причина этих показателей оценки, которые склонны предсказывать входные данные как мужчину или женщину?
Кажется запутанным?
Возьмем другой пример,
Джон страдает от лихорадки. Он обратился к врачу, чтобы проверить, вызвана ли его лихорадка коронавирусом или нет. Он объяснил симптомы, с которыми он сталкивается в настоящее время, такие как чихание, боль в теле, головная боль и т. д. Врач провел несколько медицинских анализов и сказал Джону, что это не коронная лихорадка, а обычная, одним словом (Да/Нет). Как вы думаете, Джона удовлетворит вывод врача только потому, что врач является экспертом в области медицины?

Нет, он будет несколько растерян и не уверен, потому что ответ врача выглядит как наивно-бинарный ответ Да/Нет.
Приведенный выше случай аналогичен любой модели машинного обучения. Большинство моделей, развернутых в производственной среде, представляют собой черные ящики, то есть люди, которые используют их как наивные пользователи, не знают о математической логике, закодированной внутри модели для выполнения прогноза. Реализация прогнозов такой модели может привести к убыткам, даже если метрики оценки надежно расположены.
Предположим, что доктор говорит Джону, что -
«Джон, я провел тест на антиген, чтобы определить, присутствует ли SARS-CoV-2 в вашем организме или нет. К счастью, его нет. Кроме того, я также провел серологические тесты для обнаружения антител, которые показывают, инфицированы ли вы вирусом или нет. Результат отрицательный. Вас не затронул коронавирус… Будьте счастливы!!!»
Теперь Джон будет очень уверен в выводах, сделанных врачом, и его доверие к врачу возросло. Он больше не будет беспокоиться о состоянии своего здоровья. Он был немного сбит с толку, когда доктор дал ему наивно-бинарный ответ. В этом фактическая разница между LIME и традиционным принятием прогнозов. Вместо прогноза, рекомендованного моделью, LIME принуждает интерпретировать объяснение, лежащее в основе способности модели рассуждать.
В нашем примере с классификацией изображений пользователь будет гораздо более удовлетворен, если модель укажет математическую причину прогноза, а не наивно классифицирует изображение как мужское или женское, например:
- У человека на изображении 1 борода и усы. Кажется, у него жесткий оттенок кожи и короткие волосы. Следовательно, человек должен быть мужчиной (точность — 90% и точность — 85%).
- У человека на изображении 2 нет ни бороды, ни усов. Кажется, у нее мягкий оттенок кожи и длинные волосы. Следовательно, человек должен быть женского пола (точность — 90% и точность — 85%).
n Теперь прогноз кажется более легко интерпретируемым и приемлемым, поскольку модель объясняет причину прогнозного вывода.
Это не что иное, как ЛАЙМ. Давайте посмотрим на интуицию и интерпретацию LIME. ИЗВЕСТЬ — это сокращенная форма —
- Местный
- Интерпретируемый
- Не зависит от модели
- Пояснение
«объяснение — это не что иное, как уточнение и описательное утверждение, которое может кратко передать четкие и непредвзятые причины, лежащие в основе прогнозного вывода.

Чтобы стать независимой от модели, LIME обычно не углубляется в подходы, используемые внутри алгоритма, но чтобы выяснить, какая часть интерпретируемых входных данных способствует предсказанию, мы искажаем входные данные. вокруг него и посмотрите, как ведут себя прогнозы модели.
Например,
Давайте представим, что мы создаем модель для анализа отношения к фильму — хорошего или плохого — на основе отзывов, размещенных в Интернете. Учтите, что рецензент пишет, что «мне понравился фильм». Теперь LIME рекомендует возмущать такие предложения, как «Я любил», «Я фильм», «Мне понравился фильм», «Я фильм» и т. д. в качестве входных данных для модели. Теперь, после некоторых итераций, модель может интуитивно понять, что слово «любимый» является самым важным словом для измерения настроения рецензента. Остальные слова, такие как «я», «фильм», «тот» и т. д., не так важны с точки зрения алгоритмов.

«Интерпретируемость» — это не что иное, как одна из характеристик LIME, которая позволяет пользователю понять причины и объяснения в очень ясной и легкой форме. Не должно быть высокоуровневой математики или научных концепций, чтобы наивному пользователю было трудно понять причину предсказаний модели.
Например,
При встраивании слов мы видим, что модель объясняет выводы на сложных диаграммах, которые выглядят не очень привлекательно и легко для понимания. LIME может интерпретировать такую информацию в простых формах (например, в предложениях и словах на английском языке).
Результатом LIME является список объяснений, отражающих вклад каждой функции в прогноз точки данных. Это обеспечивает локальную интерпретируемость, а также позволяет нам определить, какие изменения функций окажут наибольшее влияние на прогноз.

Давайте посмотрим на этот пример с визуальной точки зрения-
Представьте, что мы работаем над задачей бинарной классификации.
Учтите, что синий кружок обозначает границу решения (область прогнозирования) этой модели в двух измерениях признаков — X и Y.
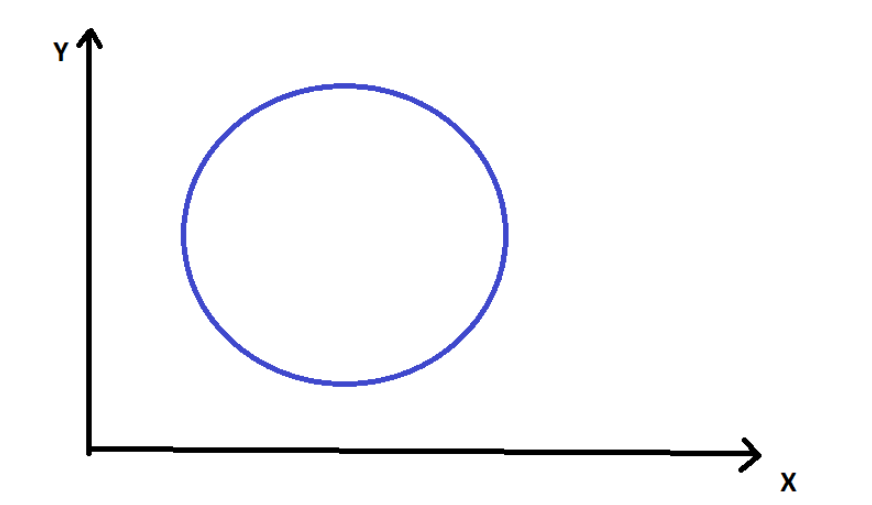
Зеленый ромб — это конкретная точка данных, а красные круги — искаженные точки данных (те, которые мы сгенерировали/настроили). Размер кружков указывает на близость исходной точки данных. Точкам данных можно присвоить определенные веса приоритета в зависимости от их близости.
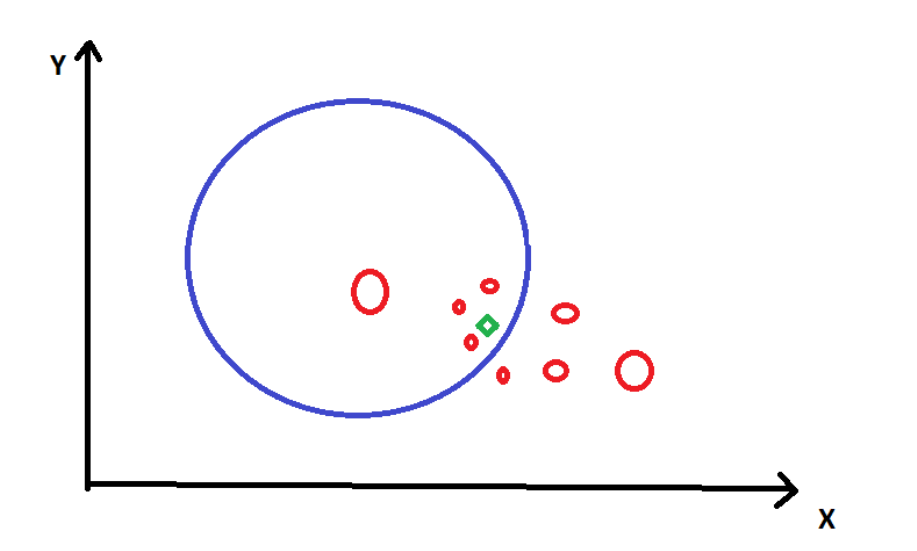
Теперь нам нужно выяснить, как прогноз модели меняется при возмущении входных данных. Для этого мы должны обучить суррогатную модель набора данных, используя искаженные точки данных в качестве цели.
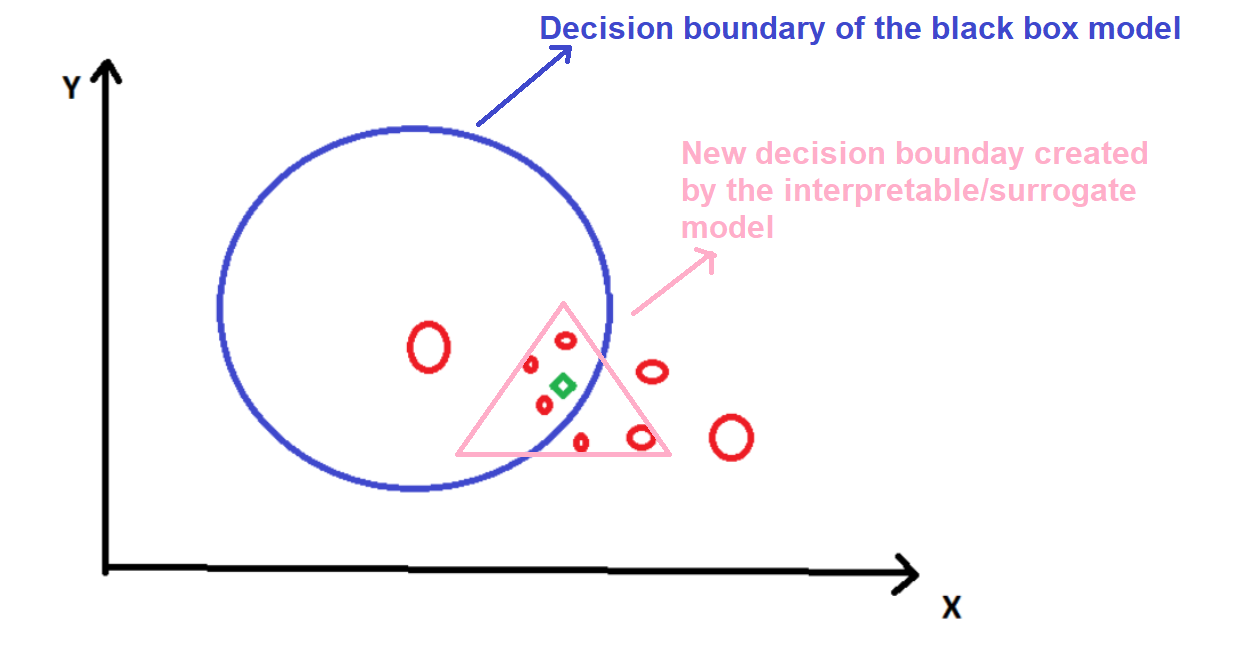
Это объяснение и выводы могут быть неприемлемы в глобальном масштабе, но приемлемы для локального региона вокруг зеленого ромба.
Вот стандартная пошаговая процедура:

«Местный» относится к локальному доверию или локальному убеждению, т. е. мы хотим, чтобы объяснение отражало поведение классификатора «вокруг» прогнозируемого экземпляра. Мера точности (насколько хорошо интерпретируемая модель аппроксимирует предсказания черного ящика) дает нам представление о том, насколько надежна интерпретируемая модель в объяснении предсказаний черного ящика в окрестности интересующей точки данных.

Это пример, упомянутый в исследовательской работе. Здесь классификатор предсказывает электрическую гитару, даже если изображение содержит акустическую гитару. Объясняющее изображение показывает причину своего предсказания. (Эта библиотека все еще не может объяснить причины в формате предложения, и в настоящее время причины объясняются в формате изображения для задач классификации изображений. Есть некоторые библиотеки, которые могут объяснить причины в формате предложения в Python и R).

Это еще один пример из исследовательской работы, где модель построена так, чтобы предсказать, предлагает ли абзац христианство или атеизм на основе слов, используемых в абзаце.

Прежде всего, нам нужно понять разницу между инструментами интерпретации, специфичными для модели, и инструментами, не зависящими от модели, чтобы понять, как это реализовано в LIME-
Инструменты интерпретации для конкретных моделей
Инструменты интерпретации для конкретных моделей относятся к одной модели или группе моделей. Эти инструменты сильно зависят от работы и возможностей конкретной модели.
Например,
- Линейная регрессия зависит от различных параметров, таких как наклон, коэффициент и т. д., чтобы делать прогнозы.
- Дерево решений использует метод, называемый энтропией, чтобы найти наилучшее разделение узлов, чтобы повысить прогностическую способность модели.
- Нейронные сети имеют миллионы параметров для соединения нейронов и создания прогнозов.
- Все перечисленные выше параметры и методы относятся к архитектуре модели. Эти правила, рекомендации или параметры модели не могут применяться глобально для интерпретаций. Они называются интерпретациями, специфичными для модели.
Инструменты интерпретации, не зависящие от модели
Независимые от модели инструменты можно использовать в любой модели машинного обучения, какой бы сложной она ни была. Эти независимые методы обычно работают, анализируя входные и выходные пары признаков. Интерпретации, специфичные для модели, будут иметь большую точность, поскольку их архитектура модели будет сложной и хорошо построенной, например, линейная регрессия, случайный лес, нейронная сеть и т. Д., Но интерпретация, не зависящая от модели, будет иметь низкую точность, поскольку интерпретации выполняются только путем анализа шаблонов. ввода и вывода.
Итак, как мы можем создавать интерпретируемые модели, не зависящие от модели, которые не ставят под угрозу точность?
Одним из решений этой проблемы является метод глобального суррогата.
Этот метод предлагает использовать дополнительную модель, называемую "интерпретируемой моделью" или "суррогатной моделью", которая может объяснить прогнозы, сделанные моделью черного ящика.
Например,
Если мы хотим построить модель машинного обучения для прогнозирования того, сдаст ли студент экзамен или нет, у нас будет 2 модели:
- Модель черного ящика (чтобы предсказать, сдаст ли студент экзамен или нет)
- Суррогатная модель (для интерпретации приблизительной логики черного ящика, используемого для принятия решений).
Модель черного ящика будет сложным алгоритмом, а суррогатная модель будет простым алгоритмом.
Например,
Нам нужно построить модель машинного обучения для предсказания, сдаст ли студент экзамен или нет. У нас есть сотни независимых переменных. Поэтому мы построили очень сложную нейронную сеть, которую нелегко интерпретировать. Теперь, получив результаты, как мы можем интерпретировать, какие особенности и характеристики переменных-предикторов привели к тому, что учащиеся сдали/не сдали экзамен?
Для этого мы можем построить простое дерево решений, которое намного проще, чем нейронная сеть, и легко интерпретируется. Используя это дерево решений, будет легко найти все факторы, в основном влияющие на успех/неуспех студентов на экзамене, такие как «Оценки за задания», «Оценки на внутренних экзаменах», «Процент посещаемости» и т. д. < /p>
Это делается путем обучения дерева решений предсказаниям модели черного ящика. Как только он обеспечит достаточную точность, мы сможем использовать его для объяснения нейронной сети.
Здесь нейронная сеть — это модель черного ящика, а дерево решений — суррогатная модель. Следовательно, мы можем заключить модель черного ящика, интерпретируя суррогатную модель.
На следующем изображении показаны шаги по созданию суррогатной модели.

Вышеупомянутая процедура основана на предположении, что – «Когда сложность модели увеличивается, точность увеличивается, а интерпретируемость снижается. Следовательно, имеет смысл делать прогнозы с использованием сложного алгоритма машинного обучения для получения высокоточных прогнозов и использовать те же входные данные и прогнозы из сложной модели машинного обучения для обучения простой модели машинного обучения, чтобы можно было легко вывести интерпретируемость прогнозов. через несложную архитектуру простой модели».
Однако недостатком метода глобальных суррогатов является то, что он может объяснить глобальные особенности и правила, которые могут интерпретировать прогнозы модели черного ящика. Однако он не может интерпретировать, как был сделан один прогноз для данного наблюдения.
Например,
Если мы прогнозируем результаты экзаменов (сдал/не сдал) тысяч студентов в университете, то глобальный суррогатный метод может показать, какие факторы глобально влияют на оценки студентов, такие как «Оценки на внутренних экзаменах», «Оценки в проектах», «Процент посещаемости» и т.д.
Но он не может интерпретировать причину, по которой «Джон (номер в списке -198), выпускник последнего года обучения по программе MBA», не смог сдать экзамен.
Независимый от модели подход LIME становится главной привлекательностью в сценариях такого рода, когда он может интерпретировать такие сценарии.
Преимущества LIME
- Мы можем изменить модель "черного ящика" и по-прежнему использовать ту же локальную суррогатную модель, поскольку она не оказывает сильного влияния на интерпретируемость.
Например,
В нашем приведенном выше примере (рис. 1 и рис. 2) давайте рассмотрим, что выделенная синим цветом граница решения (задача бинарной классификации) создана Kernel SVM, и мы используем дерево решений в качестве локальная суррогатная модель. Мы можем изменить модель черного ящика с ядра SVM на случайный лес и по-прежнему использовать то же дерево решений в качестве суррогатной модели для локальной интерпретации. Иногда локальная суррогатная модель дает гораздо больше информации о важности функции, чем модель черного ящика, что может быть полезным глобальным выводом.
* LIME может быть реализован для любых типов данных, таких как необработанные тексты, изображения, фреймы данных и т. д.
* Встроенные пакеты доступны в R и Python.
Недостатки LIME
- Простых возмущений может быть недостаточно, а сложные возмущения могут привести к систематической ошибке в модели. Следовательно, для внесения возмущений в модель требуются некоторые алгоритмы или методы мягких навыков.
* Хотя LIME не зависит от модели, тип изменений, которые необходимо выполнить с данными, зависит от варианта использования.
Например, модель, которая предсказывает, что изображения в оттенках сепии являются ретро, не может быть объяснена наличием или отсутствием суперпикселей (набор данных Iris)
* Нелинейность в локальных регионах в определенных наборах данных затрудняет интерпретацию модели. Такие модели нелегко адаптировать с помощью LIME.
Заключение
«Объяснимость» результатов машинного обучения на основе сложных моделей черного ящика всегда беспокоила исследователей в области аналитики. В какой-то степени LIME можно считать решением этой проблемы для многих вариантов использования. Есть еще много библиотек, которые разрабатываются в рамках текущих исследований и разработок в области аналитики, и LIME — успешный начальный шаг на этом пути обучения. Надеюсь, вы получили краткое представление об основных принципах LIME в этой статье. Для получения более подробной информации вы можете обратиться к официальному исследовательскому документу, который я упомянул в справочном разделе.
Ссылки
- Марко Тулио Рибейро, Самир Сингх, Карлос Гестрин, "Почему я должен вам доверять?" – Объяснение прогнозов любого классификатора
- Вилоне, Джулия; Лонго, Лука (2021). "Понятия объяснимости и подходы к оценке для объяснимого искусственного интеллекта". Информационное слияние. Декабрь 2021 г. - Том 76: 89–106. doi:10.1016/j.inffus.2021.05.009.
- "Объяснимый искусственный интеллект (XAI)". ДАРПА. ДАРПА. Проверено 17 июля 2017 г.
- Кастельвекки, Давиде (06.10.2016). "Можем ли мы открыть черный ящик ИИ?". Природа. 538 (7623): 20–23.