
Пересечение обучения с подкреплением и извлечения моделей в кибербезопасности
18 апреля 2024 г.:::информация Авторы:
(1) Мария Ригаки, факультет электротехники, Чешский технический университет в Праге, Чешская Республика, и maria.rigaki@fel.cvut.cz;
(2) Себастьян Гарсия, факультет электротехники, Чешский технический университет в Праге, Чехия, и sebastian.garcia@agents.fel.cvut.cz.
:::
Таблица ссылок
Справочная информация и сопутствующая работа
Заключение, благодарности и ссылки
3 Предыстория и сопутствующая работа
В этом разделе представлена справочная информация и обобщены соответствующие работы в области обхода вредоносных программ с помощью машинного обучения и извлечения моделей. В нем также представлена некоторая важная справочная информация об обучении с подкреплением и средах, используемых для обучения агентов уклонению от вредоносных программ.
3.1 Обучение с подкреплением
Обучение с подкреплением (RL) — это подобласть машинного обучения, в которой оптимизация функции вознаграждения выполняется агентами, взаимодействующими с окружающей средой. Агент выполняет действия в среде и получает в ответ наблюдения (вид нового состояния) и вознаграждение. Цель RL — обучить политике, которая предписывает агенту предпринимать определенные действия для максимизации получаемого вознаграждения с течением времени [40].
Более формально, агент и окружающая среда взаимодействуют в течение последовательности временных шагов t. На каждом шаге агент получает состояние из среды st и выполняет действие at из заранее определенного набора действий A. Среда создает новое состояние st+1 и вознаграждение, которое агент получает за свое действие. Посредством этого взаимодействия с окружающей средой агент пытается изучить политику π(a|s), которая отображает вероятность выбора действия в данном состоянии s, чтобы ожидаемое вознаграждение было максимальным. Одним из существенных аспектов RL является свойство Маркова, которое предполагает, что будущие состояния процесса зависят только от текущего состояния.
Некоторые из наиболее успешных алгоритмов RL представляют собой безмодельные подходы, т. е. они не пытаются построить модель окружающей среды. Недостатком безмодельных алгоритмов является то, что они, как правило, требуют большого количества данных и работают в предположении, что взаимодействие с окружающей средой не требует больших затрат. Напротив, алгоритмы обучения с подкреплением на основе моделей изучают модель окружающей среды и используют ее для улучшения обучения политике. Довольно стандартный подход к RL на основе моделей заключается в чередовании оптимизации политики и обучения модели. На этапе обучения модели данные собираются в результате взаимодействия с окружающей средой, а для изучения модели среды используется метод контролируемого обучения. Впоследствии, на этапе оптимизации политики, обученная модель исследует методы улучшения политики [21]..
Что касается приложений безопасности, обучение с подкреплением было предложено для использования в нескольких приложениях, таких как приманки [11,17], Интернет вещей и киберфизические системы [26,42], сетевая безопасность [44], обнаружение вредоносного ПО [13,43]. и уклонение от вредоносных программ [2,14,22,23,29,30,38]. В большинстве статей по уклонению от вредоносных программ используется Malware-gym или его расширения для проверки предлагаемых ими алгоритмов, поэтому ниже мы представляем основные концепции среды более подробно.
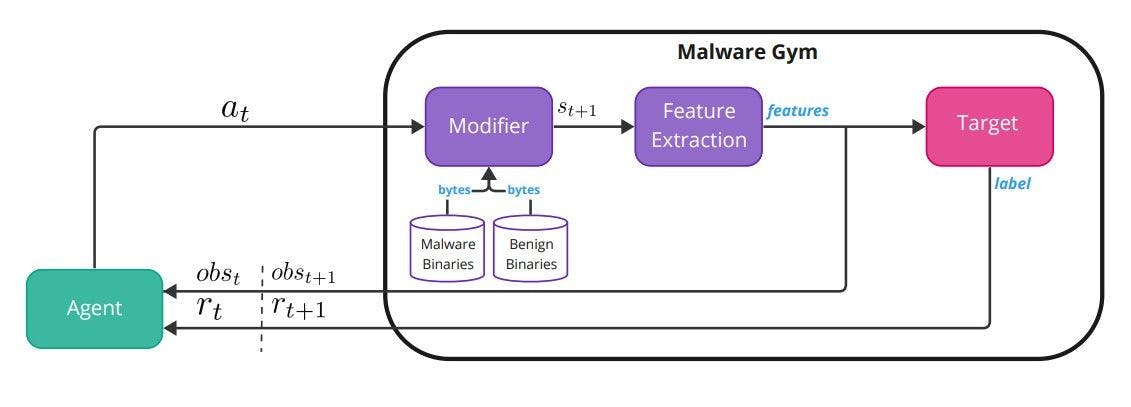
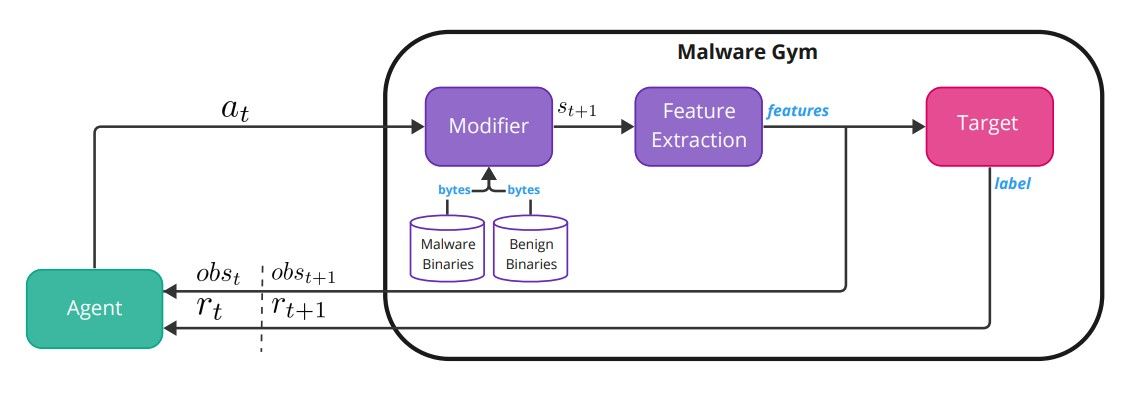
Malware-Gym Среда Malware-Gym — это среда обучения с подкреплением, основанная на OpenAI Gym [5], впервые представленная в [2]. На рис. 1 показана внутренняя архитектура среды.
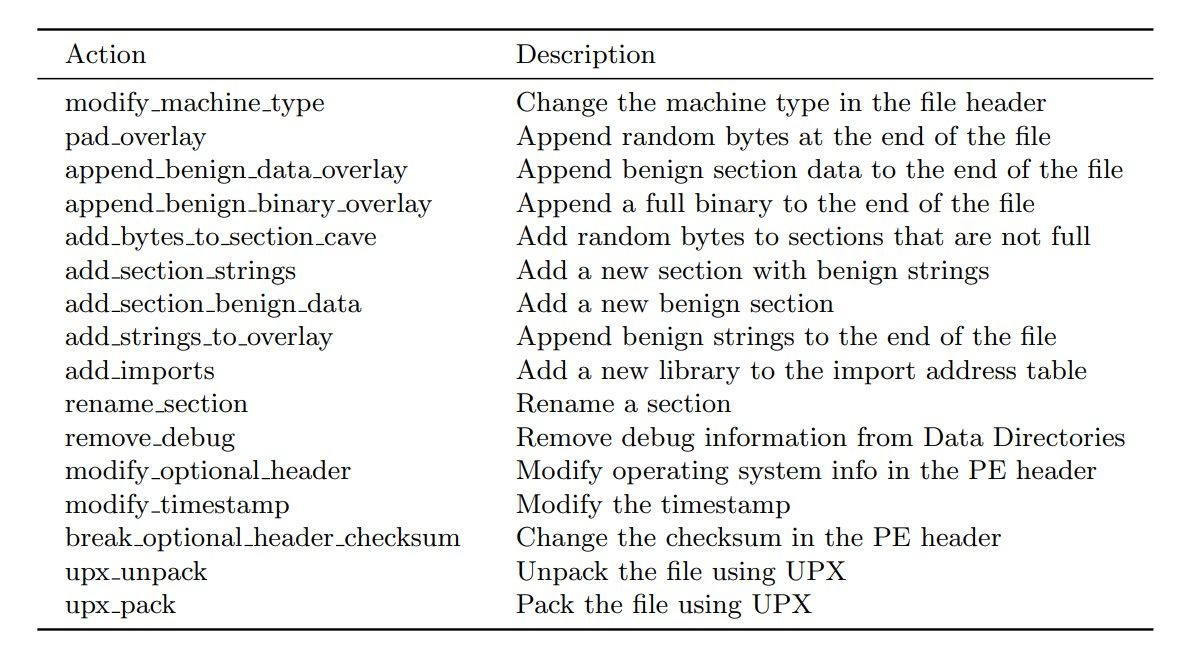
Среда инкапсулирует целевую модель, которая считается черным ящиком. Цель принимает в качестве входных данных извлеченные функции из двоичного файла и выводит метку или оценку прогноза. Байты двоичного файла представляют собой состояние st, а извлеченные признаки — это наблюдение ot, которое агент получает из окружающей среды в момент времени t. Наблюдение также передается в целевую модель, которая выводит оценку или метку. Оценка преобразуется в вознаграждение rt, которое возвращается агенту, который должен решить, какое действие предпринять, at. Действие передается обратно в среду, которая изменяет двоичный код с помощью функции перехода (модификатора) для создания следующего двоичного состояния st+1, наблюдения ot+1 и вознаграждения rt+1. Список доступных действий в последней версии Malware-Gym можно найти в Таблице 1. Перечисленные действия направлены на сохранение функциональности, и в идеале модифицированный двоичный файл должен оставаться действительным. Для некоторых действий требуется безопасный набор данных, чтобы использовать строки и разделы из безопасных файлов.
Награда рассчитывается на основе выходных данных классификатора/цели. Если оценка ниже заранее определенного порога принятия решения, двоичный файл считается безвредным, т. е. он уклонился от цели, и возвращаемое вознаграждение равно 10. Если оценка выше порога, двоичный файл считается вредоносным и рассчитывается вознаграждение. как разница между предыдущим и текущим баллами. Процесс продолжается до тех пор, пока двоичный файл не станет уклончивым или не будет достигнуто заранее определенное количество максимальных итераций. Агент получает текущее наблюдение (функции) и вознаграждение и принимает решение о следующем действии, если вредоносная программа не уклоняется, тогда она переходит к следующему двоичному файлу. Цель агента — изучить политику π, которая хорошо обобщается и может быть применена к будущим вредоносным двоичным файлам.
Таблица 1. Область действий в последней версии Malware-Gym
3.2. Уклонение от вредоносного ПО
Основная цель уклонения от вредоносного ПО — сделать его необнаружимым системами безопасности, чтобы оно могло незаметно выполнять свои вредоносные действия. Создатели вредоносного ПО постоянно разрабатывают новые методы уклонения от обнаружения, из-за чего экспертам по безопасности становится трудно идти в ногу с меняющимся ландшафтом угроз. Эта концепция развилась и теперь включает в себя обход классификаторов машинного обучения, а также использование методов машинного обучения для обхода антивирусных (AV) систем. Для целей этой работы нас в основном интересуют подходы машинного обучения, которые злоумышленники могут использовать для создания уклончивых полнофункциональных вредоносных программ для Windows PE, чтобы они не могли быть обнаружены классификаторами вредоносных программ и антивирусами.
На эту тему было написано несколько работ, а подробную таксономию и определения можно найти в следующих обзорах [10,24]. Андерсон и др. [2] создали Malware-Gym и были первой работой, создавшей состязательное вредоносное ПО, целью которого было сохранение функциональности. Они использовали модель «Актер-критик» с алгоритмом Experience Replay (ACER) и сравнивали ее с исходной моделью Ember. Другие работы расширили Malware-Gym и протестировали различные алгоритмы, такие как Double Deep Q-Network (DQN) [14], Distributional Double DQN [22] и REINFORCE [30].
Помимо тестирования различных алгоритмов, несколько авторов предложили изменения в функции вознаграждения [12,22]. MAB-вредоносное ПО [38] — еще одна структура RL, основанная на многоруких бандитах (MAB). MAB и AIMED [22] — единственные работы, в которых предполагается, что целевая модель предоставляет только жесткую метку вместо прогнозируемой оценки. В разных работах предлагается разное количество разрешенных модификаций: от 5 до 80. Однако ни одна из предыдущих работ не накладывает ограничений на количество запросов к цели и не обсуждает, является ли неограниченный доступ к запросам реалистичным сценарием. .
Другие атаки «черного ящика» для обхода классификаторов вредоносного ПО предлагали различные подходы, такие как генетические алгоритмы [9], объяснимость [33] или использование более простых, но эффективных методов, таких как упаковка [6].
3.3 Извлечение модели
Извлечение модели или кража модели – это семейство атак, целью которых является получение параметров модели, таких как веса нейронной сети или функциональная аппроксимация, с использованием ограниченного бюджета запросов. Эти типы атак обычно тестируются на приложениях машинного обучения как услуги (MLaaS). В большинстве атак с извлечением моделей используются подходы, основанные на обучении, при которых они запрашивают целевую модель с помощью нескольких образцов данных X и извлекают метки или оценки прогнозирования y для создания воровского набора данных. Используя набор данных вора, они обучают суррогатную модель, которая ведет себя аналогично целевой модели в данной задаче. Атаки по извлечению моделей могут преследовать разные цели [19]. При атаке на точность злоумышленник стремится создать суррогатную модель, которая максимально точно изучает границы принятия решения цели, включая ошибки, которые совершает цель. Эти суррогатные модели можно использовать позже в других задачах, таких как создание состязательных образцов. При атаке на точность задачи злоумышленник стремится создать суррогатную модель, которая будет работать так же хорошо или лучше, чем целевая модель, в конкретной задаче, такой как классификация изображений или вредоносного ПО. Конечная цель злоумышленника влияет на выбор набора данных вора, показатели успешной атаки и саму стратегию атаки.
Атаки на извлечение моделей на основе обучения используют различные стратегии для выбора образцов, которые они используют для запроса цели, такие как активное обучение [7,28], обучение с подкреплением [27], генеративные модели [34] или просто выбор случайных данных [8]. . В области безопасности извлечение модели было предложено в качестве первого шага атаки, целью которой является создание уклончивого вредоносного ПО [33,16,32]. И [33], и [32] генерируют уклончивое вредоносное ПО в два этапа: сначала создают суррогат, а затем используют его для уклонения от цели. Ху и др. [16] используют генеративно-состязательную сеть (GAN) и суррогатный детектор для обхода детектора вредоносного ПО, который работает с вызовами API. Ни в [16], ни в [33] не учитывается количество запросов, которые они делают к цели, тогда как в [32] авторы измеряли только эффективность запроса при извлечении модели, а не эффективность последующей задачи уклонения от вредоносного ПО.
:::информация Этот документ доступен на arxiv по лицензии CC BY-NC-SA 4.0 DEED.
:::
Оригинал
🔥 Популярное на этой неделе
-
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27521)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)