

Важность эффективной архитектуры обработки данных при создании чат-ботов с искусственным интеллектом
4 апреля 2023 г.В AISPEECH мы предоставляем услуги разговорного ИИ и решения для взаимодействия на естественном языке для широкого круга организаций, включая финансовые учреждения, правительство, а также компании IoV и IoT. Если вы верите в идею о том, что большие данные — это топливо для искусственного интеллекта, вы увидите, насколько важна для нас производительная архитектура обработки данных. В этом посте я расскажу вам, какие инструменты и методы работы с данными мы используем для поддержки наших сервисов ИИ.
Реальное время и офлайн: от разделения к единству
До 2019 г. мы использовали Apache Hive + Apache Kylin для создания нашего автономного хранилища данных и Apache Spark + MySQL для хранилища аналитических данных в реальном времени:
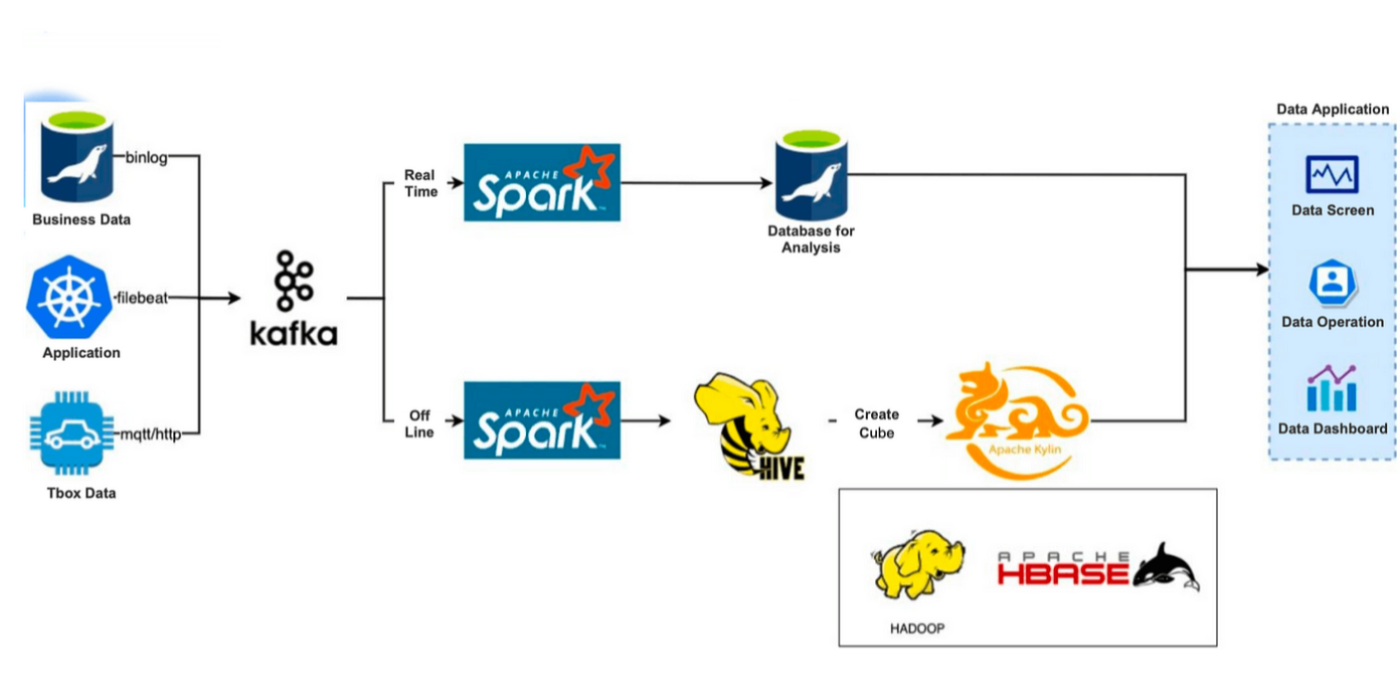
Примерно у нас есть три источника данных:
* Бизнес-базы данных, такие как MySQL * Системы приложений, такие как журналы контейнеров K8s * Журналы автомобильных T-Box
Мы записываем такие данные в Kafka через протокол MQTT/HTTP, бизнес-базу данных Binlog и сбор логов Filebeat. Затем данные будут перенаправлены по двум каналам: в режиме реального времени и в автономном режиме.
Ссылка на данные в реальном времени: данные, кэшированные Kafka, будут вычисляться Spark и передаваться в MySQL для дальнейшего анализа.
Автономная ссылка на данные: данные, очищенные Kafka, будут помещены в Hive. Затем мы использовали Apache Kylin для создания кубов, но перед этим нам нужно было предварительно построить модель данных, которая содержит таблицы ассоциаций, таблицы измерений, индексные поля и соответствующие функции агрегирования. Создание куба регулярно запускается системой планирования. Созданные кубы будут храниться в HBase.
Эта архитектура представляет собой бесшовную интеграцию с технологиями Hadoop, а Apache Kylin обеспечивает превосходную производительность в сценариях предварительного вычисления, агрегации, точной дедупликации и высокопараллельного доступа. Но с течением времени выявляются некоторые неприятные проблемы:
* Слишком много зависимостей: Kylin 2.x и 3.x сильно зависят от Hadoop и HBase. Слишком большое количество компонентов приводит к увеличению времени разработки, повышению нестабильности и увеличению затрат на обслуживание.
* Сложное создание куба в Kylin: это утомительный процесс, включающий создание плоской таблицы, дедупликацию столбцов и создание куба. Каждый день мы выполняли от 1000 до 2000 задач, но как минимум 10 из них не выполнялись, поэтому нам приходилось тратить много времени на написание сценариев автоматического O&M.
* Расширение измерения/словаря. Расширение измерения означает увеличение времени создания кубов, когда модель анализа данных включает слишком много полей без сокращения данных; Расширение словаря происходит, когда глобальная точная дедупликация занимает слишком много времени и приводит к увеличению размера словарей и увеличению времени их создания. И то, и другое может снизить общую производительность анализа данных.
* Низкая гибкость модели анализа данных: любые изменения в полях вычислений или бизнес-сценариях могут повлечь за собой возврат данных.
* Отсутствие поддержки запросов с разбивкой: мы не смогли запросить разбивку данных с этой архитектурой. Возможным решением было передать эти запросы в Presto, но введение Presto означало бы больше проблем с O&M.
Поэтому мы начали искать новый OLAP-движок, который мог бы наилучшим образом удовлетворить наши потребности. Позже мы сузили свой выбор до ClickHouse и Apache Doris. Из-за высокой сложности O&M, множества типов таблиц и отсутствия поддержки связанных запросов мы в итоге выбрали Apache Doris.
В 2019 году мы создали архитектуру обработки данных на основе Apache Doris, в которой для анализа в Apache Doris будут передаваться как данные в режиме реального времени, так и офлайн:
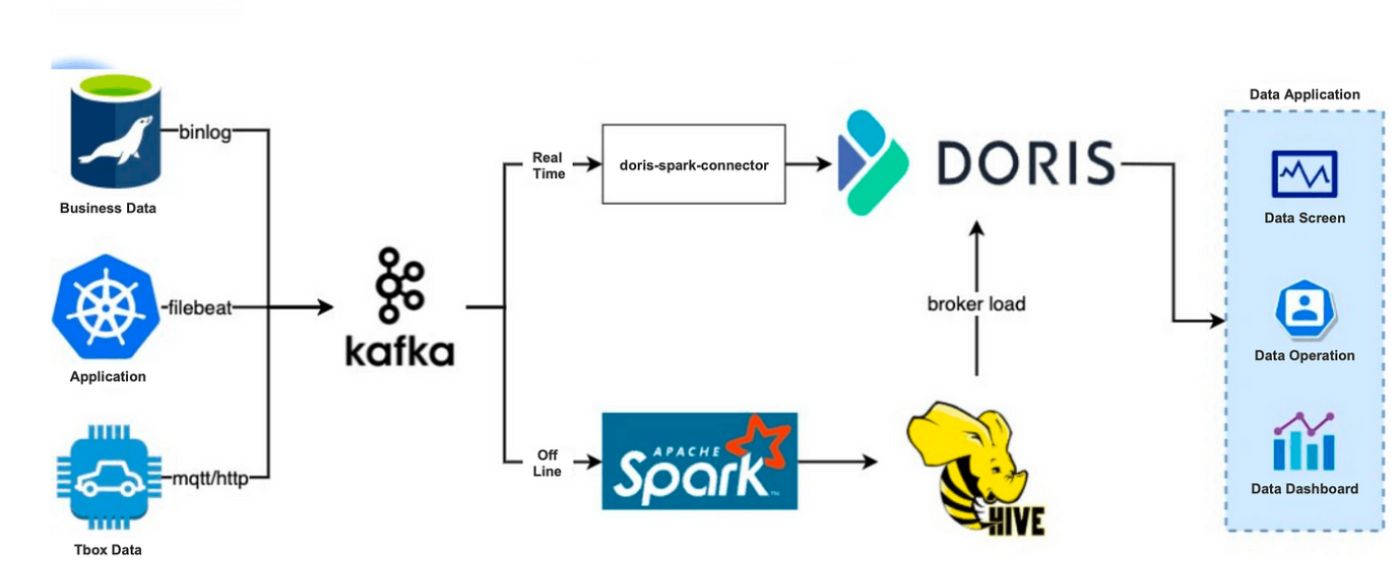
Мы могли бы создать автономное хранилище данных непосредственно в Apache Doris, но из-за устаревших причин было бы сложно перенести туда все наши данные, поэтому мы решили сохранить верхнюю половину нашей предыдущей автономной ссылки на данные.
Отличие заключалось в том, что автономные данные в Hive затем записывались в Apache Doris, а не в Apache Kylin. Метод Broker Load Дорис был быстрым. Ежедневно для загрузки 100–200G данных в Doris требовалось 10–20 минут.
Что касается канала передачи данных в реальном времени, мы использовали Doris-Spark-Connector для загрузки данных из Kafka в Doris.
Что хорошего в новой архитектуре?
- Простой O&M, не зависящий от компонентов Hadoop. Развернуть Apache Doris просто, так как он имеет только внешние и внутренние процессы. Оба типа процессов можно масштабировать, поэтому мы можем создать только один кластер для обработки сотен машин и десятков ПБ данных. Мы используем Apache Doris уже три года, но тратим очень мало времени на техническое обслуживание.
* Простое устранение неполадок. Наличие универсального хранилища данных, способного предоставлять услуги данных в режиме реального времени, интерактивный анализ данных и автономную обработку данных, делает процесс разработки коротким и простым. Если что-то пойдет не так, нам нужно всего лишь проверить несколько точек, чтобы найти основную причину.
* Поддержка запросов JOIN в формате Runtime. Это похоже на ассоциацию таблиц в MySQL. Это полезно в сценариях, требующих частой смены моделей анализа данных.
* Поддержка запросов JOIN, агрегирования и разбивки.
* Поддержка нескольких методов ускорения запросов. К ним относятся сводный индекс и материализованное представление. Сводный индекс позволяет нам реализовать вторичный индекс для ускорения запросов.
* Поддержка федеративных запросов к озерам данных, таким как Hive, Iceberg, Hudi, и базам данных, таким как MySQL и Elasticsearch.
Как Apache Doris расширяет возможности ИИ
В AISPEECH мы используем Apache Doris для запросов данных в режиме реального времени и определяемой пользователем аналитики диалоговых данных.
Запрос данных в реальном времени
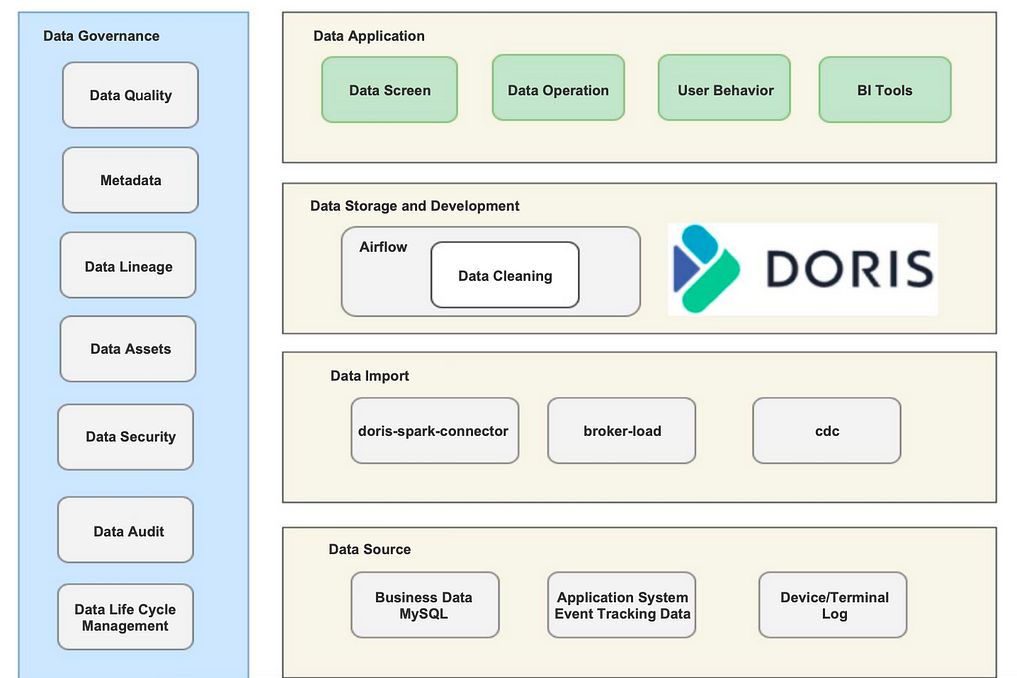
Конвейер обработки данных в реальном времени работает, как указано выше. Мы получаем автономные данные через Broker Load и данные в реальном времени через Doris-Spark-Connector. Мы помещаем почти все наши данные в реальном времени в Apache Doris, а часть наших автономных данных — в Airflow для пакетных задач DAG.
Наши данные в режиме реального времени находятся в огромном объеме, поэтому нам действительно нужно решение, обеспечивающее высокую эффективность запросов. Между тем, у нас есть команда из 20 человек для работы с данными, и нам необходимо предоставить услуги по информационной панели для всех из них. Это может быть сложной задачей для записи данных в реальном времени и требовать параллелизма запросов. К счастью, все это делает Apache Doris.
Анализ пользовательских данных
Это моя любимая часть, потому что мы с гордостью использовали наши возможности обработки естественного языка (NLP) в запросах данных.
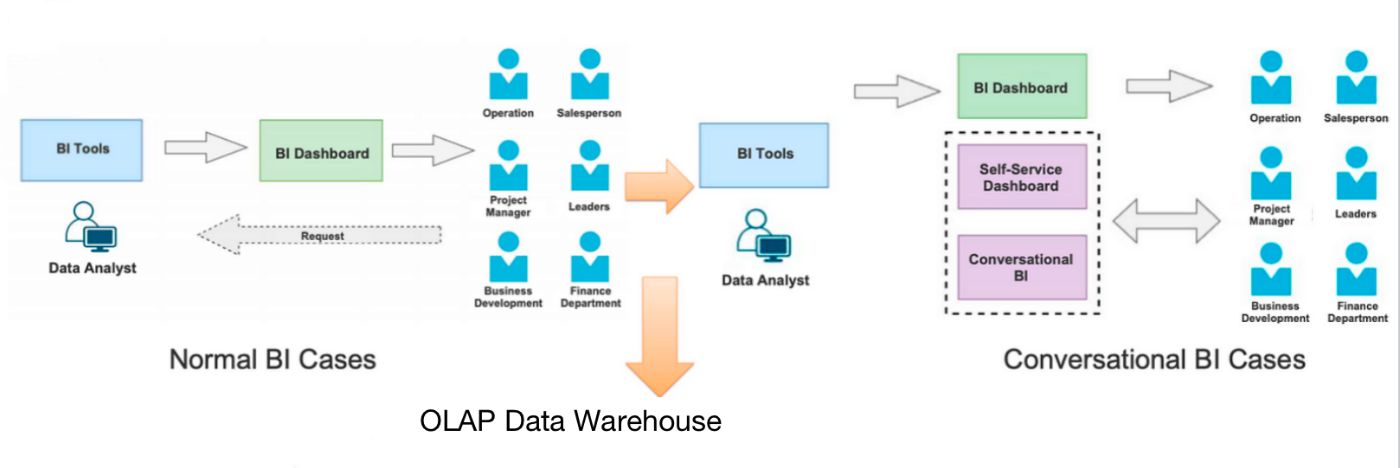
Обычный сценарий BI работает следующим образом: аналитики данных настраивают информационные панели на платформе BI в зависимости от потребностей пользователей данных (например, финансового отдела и менеджеров по продуктам). Но мы хотели большего. Мы хотели удовлетворить более уникальные потребности пользователей данных, такие как сведение и детализация в любом указанном измерении. Вот почему мы включаем определяемый пользователем анализ разговорных данных.
В отличие от обычных случаев BI, с инструментами BI общаются пользователи данных, а не аналитики данных. Им нужно только описать свои требования на естественном языке, а мы, используя наши возможности НЛП, превратим их в SQL. Звучит знакомо? Да, это похоже на GPT-4 для конкретного домена. За исключением того, что мы оптимизировали его в течение длительного времени и настроили для лучшей интеграции с Apache Doris, чтобы наши пользователи данных могли ожидать более высоких показателей совпадений и более точных результатов синтаксического анализа. Затем сгенерированный SQL будет отправлен в Apache Doris для выполнения. Таким образом, пользователи данных могут просматривать любые детали разбивки и сворачивать или детализировать любые поля.
Как Apache Doris делает это хорошо?
Apache Doris имеет следующие сильные стороны по сравнению с предварительно вычисляемыми механизмами OLAP, такими как Apache Kylin и Apache Druid:
* Гибкие модели запросов, поддерживающие пользовательские сценарии. * Поддержка ассоциации таблиц, агрегированных вычислений и запросов на разбивку * Быстрое время отклика
Наши внутренние пользователи оставляют положительные отзывы об этом анализе разговорных данных.
Предложения
Мы накопили некоторый практический опыт использования Apache Doris, который, по нашему мнению, может избавить вас от некоторых обходных путей.
Дизайн таблицы
Используйте повторяющуюся таблицу для небольших объемов данных (например, менее 10 миллионов строк). Дублирующиеся таблицы поддерживают как агрегированные, так и разбивочные запросы, поэтому вам не нужно создавать дополнительную таблицу со всеми подробными данными.
Используйте сводную таблицу для больших объемов данных. Затем вы можете выполнить сводное индексирование, ускорить запросы с помощью материализованного представления и оптимизировать поля агрегации поверх сводных таблиц. Недостатком является то, что, поскольку сводные таблицы представляют собой предварительно вычисляемые таблицы, вам потребуется дополнительная таблица разбивки для подробных запросов.
При обработке огромных объемов данных со многими связанными таблицами создайте плоскую таблицу с помощью ETL, а затем загрузите ее в Apache Doris, где вы сможете выполнить дальнейшую оптимизацию на основе типа таблицы Aggregate. Или вы можете воспользоваться оптимизацией присоединения, рекомендованной сообществом Doris.
Хранилище
Мы изолируем горячие и горячие данные в хранилище. Данные за прошлый год хранятся на SSD, а данные старше этого года хранятся на HDD. Apache Doris позволяет нам установить период охлаждения для разделов, но соответствующую настройку можно выполнить только при создании раздела. Наше текущее решение — автоматическая синхронизация, при которой мы переносим определенную часть исторических данных с SSD на жесткий диск, чтобы убедиться, что все данные за прошлый год размещены на SSD.
Обновить
Перед обновлением обязательно сделайте резервную копию метаданных. Альтернативный метод — запустить новый кластер, создать резервную копию файлов данных в удаленной системе хранения, такой как S3 или HDFS, через Broker, а затем импортировать данные из данных старого кластера в новый кластер путем восстановления из резервной копии.
Производительность после обновления версии
Начиная с Apache Doris 0.12, мы догоняем выпуски Apache Doris. В наших сценариях использования последняя версия может обеспечить в несколько раз более высокую производительность, чем ранние, особенно в запросах со сложными функциями и операторами, включающими несколько полей. Мы очень ценим усилия сообщества Apache Doris и настоятельно рекомендуем вам установить последнюю версию.
Обзор
Подводя итог тому, что мы получили от Apache Doris:
* Apache Doris может быть хранилищем данных в режиме реального времени + в автономном режиме, поэтому нам нужен только один ETL-скрипт. Это экономит нам много времени на разработку и затраты на хранение, а также позволяет избежать несоответствия между показателями в реальном времени и в автономном режиме.
* Apache Doris 1.1.x поддерживает векторизацию и, таким образом, обеспечивает в 2–3 раза более высокую производительность, чем более ранние версии. Результаты тестирования показывают, что Apache Doris 1.1.x не уступает ClickHouse по производительности запросов к плоским таблицам.
* Apache Doris сам по себе мощный и не зависит от других компонентов. В отличие от Apache Kylin, Apache Druid и ClickHouse, Apache Doris не требует никаких других компонентов для заполнения каких-либо технических пробелов. Он поддерживает агрегацию, запросы на разбивку и связанные запросы. Мы перенесли более 90 % нашего анализа на Apache Doris, что значительно упростило и упростило нашу эксплуатацию и техническое обслуживание.
* Apache Doris прост в использовании, так как поддерживает протокол MySQL и стандартный SQL.
Оригинал
🔥 Популярное на этой неделе
-
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г.
⭐ Самое популярное
-
Marvel’s Wolverine: все, что мы знаем об эксклюзиве для PS5 на данный момент
31 марта 2023 г. -
Новые фильмы 2023 года: самые крупные предстоящие релизы скоро появятся в кинотеатрах
7 декабря 2022 г. -
8 проектов с открытым исходным кодом, которые помогут вашему бизнесу работать эффективно
6 апреля 2022 г. -
Новые фильмы Netflix 2023 года: самые большие оригинальные фильмы, выходящие на стример
28 декабря 2022 г. -
Новое обновление Xbox Series X только что вышло и может сэкономить вам деньги
12 января 2023 г.
Categories
- Технологии и IT (27076)
- Игры, развлечения и хобби (4775)
- Искусственный интеллект и будущее (294)
- Бизнес и предпринимательство (273)
- Общество и культура (244)
- Дизайн и креатив (202)
- Экономика и финансы (107)
- Социальные медиа и интернет-культура (107)
- Наука и исследования (74)
- Спорт и здоровье (55)
- Психология и саморазвитие (50)
- Образование и обучение (20)
- Маркетинг и реклама (17)
- Путешествия и lifestyle (6)